
Real World Crypto: Day 2 posted January 2016
This is the 2nd post of a series of blogpost on RWC2016. Find the notes from day 1 here.
disclaimer: I realize that I am writing notes about talks from people who are currently surrounding me. I don't want to alienate anyone but I also want to write what I thought about the talks, so please don't feel offended and feel free to buy me a beer if you don't like what I'm writing.
And here's another day of RWC! This one was a particularly long one, with a morning full of blockchain talks that I avoided and an afternoon of extremely good talks, followed by a suicidal TLS marathon.

09:30 - TLS 1.3: Real-World Design Constraints
tl;dw: hello tls 1.3
DJB recently said at the last CCC:
"With all the current crypto talks out there you get the idea that crypto has problems. crypto has massive usability problems, has performance problems, has pitfalls for implementers, has crazy complexity in implementation, stupid standards, millions of lines of unauditable code, and then all of these problems are combined into a grand unified clusterfuck called Transport Layer Security.
For such a complex protocol I was expecting the RWC speakers to make some effort. But that first talk was not clear (as were the other tls talks), slides were tiny, the speaker spoke too fast for my non-native ears, etc... Also, nothing you can't learn if you already read this blogpost.
10:00 - Hawk: Privacy-Preserving Blockchain and Smart Contracts
tl;dw: how to build smart contracts using the blockchain
- first slide is a picture of the market cap of bitcoin...
- lots of companies are doing this block chain stuff:
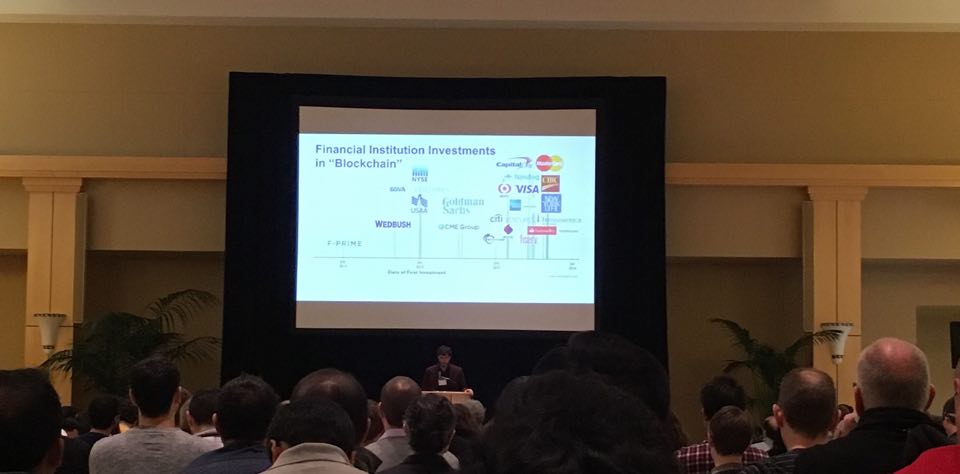
- DAPS. No idea what this is, but he's talking about it.
Dapps are based on a token-economy utilizing a block chain to incentivize development and adoption.
- bitcoin privacy guarantees are abysmal because of the consensus on the block chain.
- contracts done through bitcoin are completely public
- their solution: Hawk (between zerocash and ethereum)
- uses zero knowledge proofs to prove that functions are computed correctly
- blablabla, lots of cool tech, cool crypto keywords, etc.
if you're really interested, they have a tech report here (pdf)
As for me, this tweet sums up my interest in the subject.
So instead of playing games on my mac (see bellow (who plays games on a mac anyway?)). I took off to visit the Stanford campus and sit in one of their beautiful library

12:00 - Lightning talks.

I'm back after successfuly avoiding the blockchain morning. Lightning talks are mini talks of 1 to 3 minutes where slides are forbidden. Most were just people hiring or saying random stuff. Not much to see here but a good way to get into the talking thing it seems.
In the middle of them was Tancrede Lepoint asking for comments on his recent Million Dollar Curve paper. Some people quickly commented without really understanding what it was.
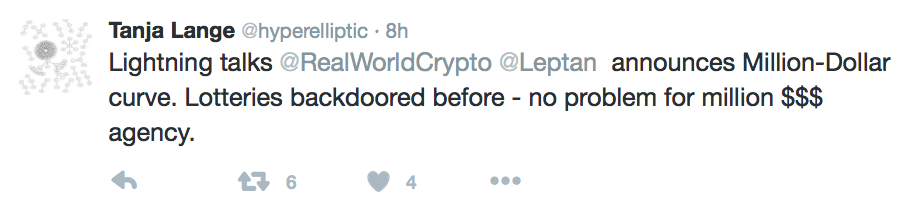
(Sorry Tanja :D). Overall the idea of the paper is how to generate a safe curve that the public can trust. They use the Blum Blum Shub PRNG to generate the parameters of the curve, iterating the process until it completes a list of checks (taken from SafeCurves), and seeding with several drawings from lotteries around the world in a particular timeframe (I think they use a commitment for the time frame) so that people can see that these numbers were not chosen in a certain ways (and would thus be NUMS).
14:00 - An Update on the Backdoor in Juniper's ScreenOS
tl;dw: Juniper
Slides are here. The talk was entertaining and really well communicated. But there was nothing majorly new that you can't already read in my blogpost here.
- it happened around Christmas, lots of security people have nothing to do around this period of the year and so the Juniper code was reversed really quickly (haha).
- the password that looks like a format string was already an idea taken straight from a phrack 2009 issue (0x42)
Developing a Trojaned Firmware for Juniper ScreenOS Platforms
- unfiltered Dual EC outputs (the 30 bytes of output and 2 other bytes of a following Dual EC output) from a IKE nonce
- but the Key Exchange is done before generating the nonce? They're still working on verifying this on real hardware (they will publish a paper later)
- in earlier versions of ScreenOS the nonces used to be 20 bytes, the RNG would output 20 bytes only

- When they introduced Dual EC in their code (Juniper), they also changed the nonce length from 20 bytes to 32 bytes (which is perfect for easy use of the Dual EC backdoor). Juniper did that! Not the hackers.
- they are aware, through their disclosure, that it is "exploitable"
- the new patch (17 dec 2015) removed the SSH backdoor and restored the Dual EC point.
A really good question from Tom Ritter: "how many bytes do you need to do the attack". Answer: truncated output of Dual EC is 30 bytes (instead of 32), so you need to bruteforce the 2 bytes. To narrow the search space, 2 bytes from the next output is practical and enough. So ideally 30 bytes and 2 bytes from a following output allows for easy use of the Dual EC backdoor.
(which is something I forgot to mention in my own explanation of Dual EC)
14:20 - Pass: Strengthening and Democratizing Enterprise Password Hardening
tl;dw: use a external PRF
- Ashley Madison and other recent breaches taught us that hashing was not enough to protect passwords
- smash and grab attacks
A smash and grab raid or smash and grab attack (or simply a smash and grab) is a particular form of burglary. The distinctive characteristics of a smash and grab are the elements of speed and surprise. A smash and grab involves smashing a barrier, usually a display window in a shop or a showcase, grabbing valuables, and then making a quick getaway, without concern for setting off alarms or creating noise.
- The Ashley Madison breach is interesting because they used bcrypt and salting with high cost parameter, which is better than industry norms to protect passwords.
- he cracked 4000 passwords from the leaks anyway

- millions of password were cracked a few weeks after
- He has done some research and has come up with a response: PASS, password hardening and typo correctors
- facebook password onion from last year's RWC looks like an "archeological record"

- the hmac with the private key transforms the offline attack in an online attack because the attacker now needs to query the PRF service repeatidly.
- "the facebook approach" is to use a queriable "PRF service" for the hmac, it makes it easier to detect attacks.
- but several drawbacks:
- 1) online attackers can instead record the hashes (mostly because of this legacy code)
- 2) the PRF is not called with a per-user granularity (same for all users) -> hard to implement fined-grained rate limiting (throtteling/rate limiting attempts, you are only able to detect global attacks)
- 3) no support for periodic key rotations -> if they detect an attack, they now need to add new lines in their key hashing rotting onion
- PASS uses a PRF Service, same as facebook but also:
- 1) blinding (PRF can't see the password)
- 2) graceful key rotation
- 3) per-user monitoring

- the blinding is a hash raised to a power, unblinding is done by taking the square root of that power (but maybe he simplified an inverse modulo something?)
- a tweek
tis sent as well, basically the user id, it doesn't have to be blinded and so they invented a new concept of "partially oblivious PRF" (PO-PRF)

-
the tweak and the blinded password are sent to the PRF which uses a bilinear pairing construction to do the PO-PRF thingy (this is a new use case fo bilinear pairing apparently).
-
it's easy to implement, completely transparent to users, highly scalable.
- typos corrector: idea of a password correctors for famous typos (ex: a capitalized first letter)
- facebook does this, vanguard does this...
- intuition tells you it's bad: an attacker tries a password, and you help him find it if it's almost correct.
- they instrumented dropbox for a period of 24 hours (for all users) to implement this thing
- they took problems[:3] = [accidental caps lock key, not hitting the shift key to capitalize the first letter, extra unwanted character]
- they corrected 9% of failed password submissions
- minimal security impact, according to their research "virtually no security loss"
- paper seems interesting
- there is some open source code somewhere
Question from Dmitry Khovratovich: Makwa does something like this, exactly like this (outch!). Answer: "I'm not familiar with that"
14:50 - Argon2 and Egalitarian Computing
tl;dw: argon2 hash function efficient against ASICs
- passwords are not long (PIN, human has to remember the password) -> brute force attacks are possible
- password cracking is easier with GPU or FPGAs or even ASICs
- ASICs? -> ex: bitcoin, they switched to ASICs (2^32 hashes/joule on ASIC, 2^17 hashes/joule on GPU)
- Argon2 created for the password hashing competition
- memory-intensive computation: make a password hashing function so that you need a lot of memory to use it -> the ASIC advantage vanishes (if someone wants to explain to me how is that, feel free).

- winner: Argon2
- they wanted the function to be as simple as possible (to simplify analysis)
- you need the previous block to do the next computation (badly parallelizable) and a reference block (takes memory)

- add some parallelism... there was another slide I have no image and no comment :(
- this concept of slowing down attackers has other applications -> egalitarian computing
- for ex: in bitcoin they wanted every user to be able to mine on his laptop, but now there are pools taking up more than 50% (danger: 51% attack)
- can use it for client puzzles for denial of service protection.
- egalitarian computing -> ensures that attacker and defender are the same (no advantage using special computers)

15:10 - Cryptographic pitfalls
tl;dw: 5 stories about cute and subtle crypto fails
- talker is explicit about his non-involvement with Juniper (haha)
-
he's narrating the tales of previously disclosed vulns, 5 case studies, mostly because of "following best practice" attitude (not that it's bad but usually not enough).
- 1)
- concept of zeroisation
- HSM manufacturer had a sandbox for user code, always zeroed memory when it was freed
- problem is, sometimes memory doesn't get freed, like when you pull the power out.
- (reminds me of the cold boot attack of the other day).

-
2)
- concept of "reusing components rather than designing new ones"
- vpn uses dsa/dh for ipsec
- over prime fields
- pkcs#3 defines something
- PKIXS says something else, subtle difference


- 3)
- concept of "using external events to seed your randomness pool", gotta get your entropy from somewhere!
- entropy was really bad from the start because they would boot the device right after production line, nothing to build entropy from (the same thing happened in the carjacking talk at blackhat us2015)
- so the key was almost the same because of that, juniper fixed it after customer report (the customer changed his device, but he didn't get an error that the key had changed)

- 4)
- concept of "randomness in RSA factors"
- government of some country use smartcards
- then they want to use cheaper smartcards, but re-used the same code
- the new RNG was bad

- 5)
- everything is blanked out (he can't really talk about it)
- they used CRC for integrity (instead of a MAC/signature)

from the audience, someone from Netscape speaks out "yup we forget that things have to be random as well" (cf predictable Netscape seed)
16:00 - TLS at the scale of Facebook
tl;dw: how they deployed https, wasn't easy
Timeline of the https deployment:
- In 2010: facebook uses https almost only for login and payments
- during a hackaton they tried to change every http url to https. It turns out it's not that simple.
- not too long after firesheep happened, then Tunisia only ISP started doing script injection to non-https traffic. They had to do something
- In 2011, they tried mixing secure and insecure. Then tried to make ALL apps support https (outch!)
- In 2012, they wanted https only (no https opt-in)
- In 2013, https is the default. At the end of the year they finally succeed: https-only
- (And thinking that not so long ago it was normal to login without a secure connection... damn things have changed)

- Edge Networks: use of CDNs like Akamai or cloudflare or spread your servers in the world
- Proxygen, open source c++ http framework
- (Proxygen mobile still not open source)
- they have a client-side TLS (are they talking about mobile?) built on top of proxygen. This way they can ship improvement to TLS before the platform does, blablabla, there was a nice slide on that.
- they really want 0-RTT, but tls 1.3 is not here, so they modified QUIC crypto to make it happen on top of TCP: it's called Zero.

- certificate pinning: they cancel MITM by disallowing locally-installed CAs on android, iOS they cannot.
- https://www.certificate-transparency.org/ (certificate logs, monitors, auditors)
- SNI header
Server Name Indication (SNI) is an extension to the TLS computer networking protocol[1] by which a client indicates which hostname it is attempting to connect to at the start of the handshaking process. This allows a server to present multiple certificates on the same IP address and TCP port number and hence allows multiple secure (HTTPS) websites (or any other Service over TLS) to be served off the same IP address without requiring all those sites to use the same certificate
- stats:
- lots of session resumption by ticket -> this is good
- low number of handshakes -> that means they store a lot of session tickets!
- very low resumption by session ID (why is this a good thing?)
- they haven't turned off RC4 yet!
- something in the audience tells him about downgrade attacks, outch!
- the referrer field in the http header is empty when you go on another website from a https page! Is that important... no?
- it's easy for a simple website to go https (let's encrypt, ...), but for a big company, fiou it's hard!
- still new feature phones that can't access tls (do they care? mff)
16:30 - No More Downgrades: Protecting TLS from Legacy Crypto
tl;dw: SLOTH

- brainstorming: "how do we fix that in tls 1.3?"
- explanation of Logjam (see my blogpost here)
- at the end of the protocol there is a finish message where is included all the negotiation in a mac:
- but this is already too late: the attacker can forge the mac as well at this point
- this is because the downgrade protection mechanism (this mac at the end) itself depends on downgradeable parameters (the idea behind logjam)
- in tls 1.3 they use a signature instead of the mac
- but you sign a hash function! -> SLOTH (which was released yesterday)
Didn't understand much, but I know that all the answers are in this paper. So stay tuned for a blogpost on the subject, or just read the freaking paper!

- sloth is a transcript collision attack
- he talks about sigma protocol for some reason (proof of knowledge)

- tls 1.3 includes a version downgrade resilience system:
- the server chooses the version
- the server has to choose the highest common version
- ...
- only solution they came up with: put all the versions supported in the server nonce. This nonce value (server.random to be exact) is in all tls versions and is signed before the key exchange happens.
16:50 - The OPTLS Protocol and TLS 1.3
tl;dw: how does OPTLS works
- paper is here
- tls 1.3 improved RTT and PFS
- agreement + confidentiality are the fundamental requirements for a key exchange protocol
- OPTLS is a key exchange that they want tls 1.3 to use
The OPTLS design provides the basis for the handshake modes specified in the current TLS 1.3 draft including 0-RTT, 1-RTT variants, and PSK modes
I have to admit I was way too tired at that point to follow anything. Everything looked like David Chaum's presentation. So we'll skip the last talk in this blogpost.

Comments
leave a comment...