Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
At Real World Crypto 2019, Mihir Bellare won the Levchin Prize (along with Eric Rescorla) and gave a short and inspiring speech. You can watch it here. In it, he briefly mentioned what I'll call the speed issue:
when I started it was a question of being responsive to the industry and practical needs [...] Now I think these are much deeper questions [...] Who benefits from the work we do? [...] Who benefits from making things faster beyond a certain point? The constant search for speed. What sort of people do we become when we cannot wait half a second for a web page to load because TLS is doing a round trip and we're cutting corners.
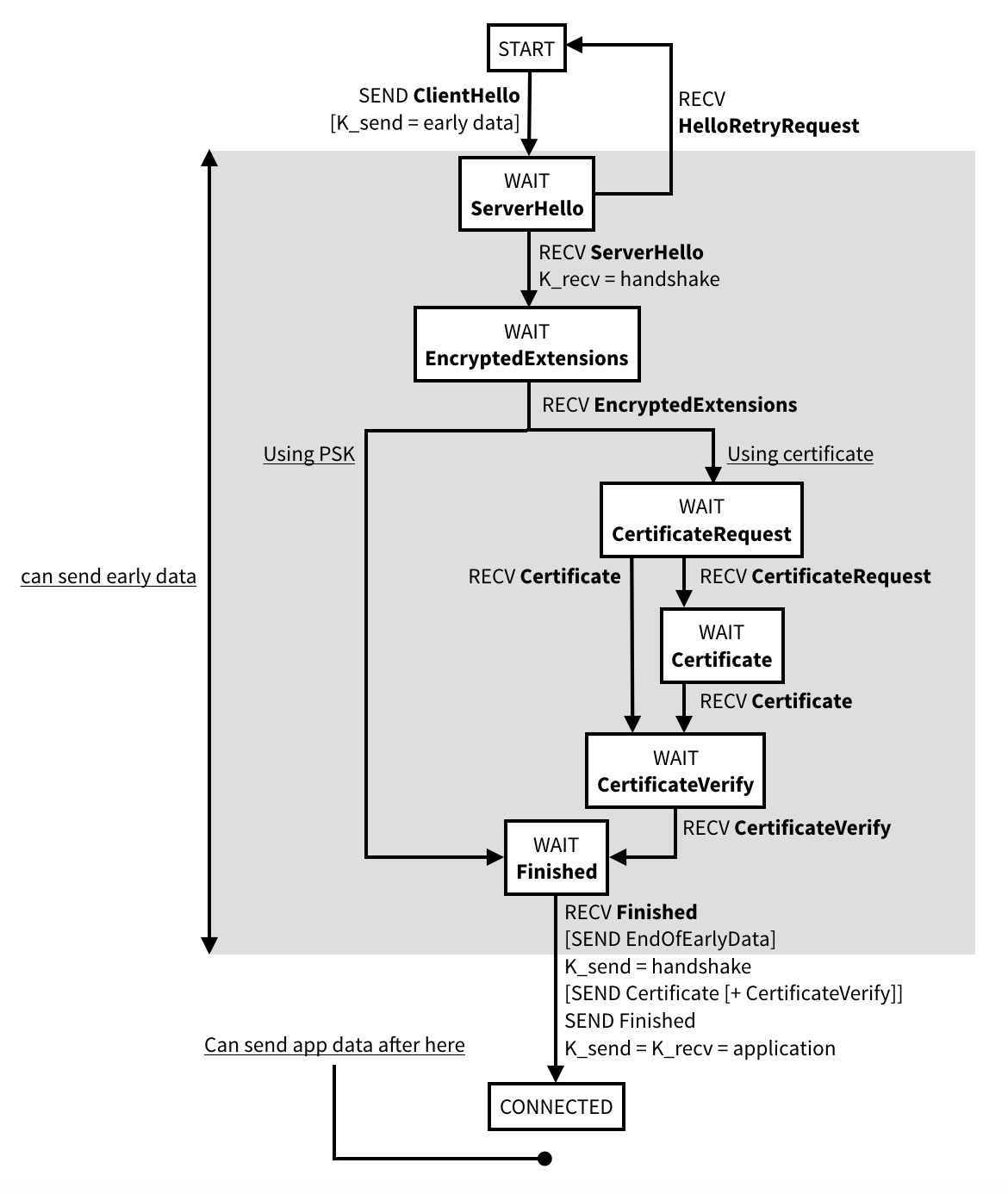
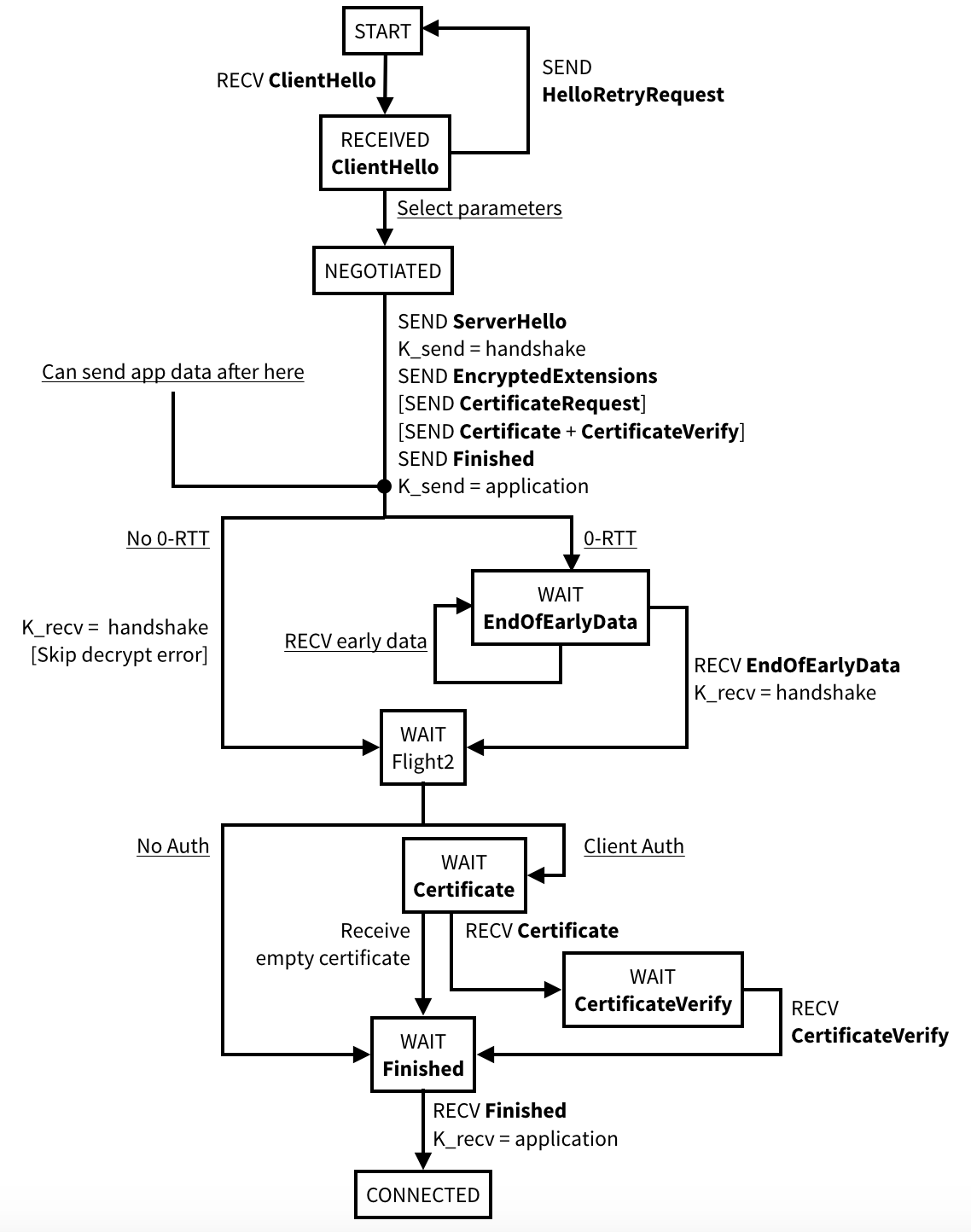
In here, Bellare is obviously hinting at Eric Rescorla's work with TLS 1.3, in particular the 0-RTT or early data feature of the new protocol. If you don't know what it is, it's a new feature which allows a client to send encrypted data as part of its very first flight of messages. As I explained in this video, it does not protect against replay attacks, nor benefits from forward secrecy.
Replay: a passive observer can record these specific messages, then replay them at a later point in time. You can imagine that if the messages were bank transactions, and replaying them would prompt the bank to initiate a new transaction, then that would be a problem.
Forward Secrecy: TLS sessions in TLS 1.3 benefits from this security property by default. If the server's long-term keys are stolen at a certain point in time, previous sessions won't be decryptable. This is because each session's security is augmented by doing an ephemeral key exchange with keys that are deleted right after the handshake. To break such a session you would need to obtain these ephemeral keys in addition to the long-term key of the server. Sending 0-RTT data happens before any ephemeral key exchange can happen. The data is simply encrypted via a key derived from a pre-shared key (PSK). Here the lack of forward secrecy means that if the PSK is stolen at a later point in time, that data will be decryptable. This is much less of an issue for browsers as these PSK are often short-lived, but it's not always the case in other scenarios.
0-RTT has been pretty controversial, it has generated a lot of discussion on the TLS 1.3 mailing list (see 1, 2, 3) and concerns about its security have taken an entire section in the specification itself.
While I spent quite some time telling you about TLS 1.3's 0-RTT in this post, it is just one example of a security trade-off that WE made, all of us, for the benefit of a few big players. Was it the right thing to do? Maybe, maybe not.
What are the other examples? Well guess why we're using AES-GCM? Because it is hardware accelerated. But who asked Intel for it? Why are we standardizing a shitty WPA 3.0 protocol? Probably because some Wi-Fi Alliance is telling us to use it, but what the F is going on there? Why is full disk encryption (FDE) completely flawed? I am not even talking about the recent Self-encrypting deception: weaknesses in the encryption of solid state drives (SSDs) research, but rather the fact that vendors implementing FDE are never using authentication on ciphertexts! and continue to refuse to tackle the issue via primitives like wide-block ciphers. Probably because it's not fast enough!
Now look at what cryptographic primitives people are pushing for nowadays: AES-GCM, Chacha20-Poly1305, Curve25519, BLAKE2. This is pretty much what you're forced into if you're using any protocol in 2019 (yes even the Noise Protocol Framework). Are these algorithms bad? Of course not. But they are there because large companies wanted them. And they wanted them because they were fast. I touched on that in Maybe you shouldn't skip SHA-3 after Adam Langley's wrote an article on SHA-3 not being fast enough.
We're in a crypto era where the hotness is in the "cycles per byte" (cpp).
All of this is concerning, because once you look at it this way, you see that big players have a huge influence over our standards and the security trade-offs we end up doing for speed are not always worth it.
If you're not a big player, you most likely don't care about these kinds of optimizations. The cryptography you use is not going to be the bottleneck of your application. You do not have to do these trade-offs.
Mathias Hall-Andersen, Alishah Chator, Nick Sullivan and I have released a new construction called nQUIC.
nQUIC = Noise + QUIC
If you don't know what QUIC is, let me briefly explain: it is the last invention of Google, which is being standardized with the IETF. It's a take on the lessons learned developing HTTP/2 about the limitations of TCP. You can see it as a better TCP(2.0) for a better HTTP(/3) with encryption built in by default.
The idea is that, when you visit a page, you end up fetching way more files than you think. There is some .css, some .js, a bunch of .png and maybe even other pages via some iframes. To do this, browsers have historically opened multiple TCP connections (to the same server perhaps) in order to receive the file faster. This is called multiplexing and it's not too hard to do, you just need to use a different TCP port for every connection you create. The problem is that it takes time for each TCP connection to start (there is a TCP handshake as well as a TLS handshake) and then to figure out how fast they can go (TCP flow control).
So in HTTP/2, instead of opening several TCP connections to the same server, we just open one. We then do the multiplexing inside of this one connection.
So now you're doing one TCP handshake, then you optimize the connection via TCP's mechanism, and you rely on that to receive whatever the server sends to you. It sends you a bunch of blocks, in whatever order, that you can buffer and glue back together. For example, you might receive some html, then some jpg, then the rest of the html.
One problem is that if faults start appearing on the network, all the different objects you're trying to receive will be impacted, not just one of them. So one ACK can mess every element on the page.
Comes QUIC which fixes these multiplexing issues by re-inventing TCP. Because of middle boxes and firewall issues, QUIC is built on top of UDP instead of creating another protocol on top of IP. It doesn't matter much in theory because UDP is just IP with ports (and ports are useful).
QUIC has different streams, which can carry different content (in order) and are not impacted by issues happening in other streams. You can thus carry the html page in one stream, an image in another stream, the css file in another stream, etc.
On top of that, the people at Google thought that encryption would be very useful to have baked into the protocol instead of making it optional and a responsability of applications (that's what TLS is). Google started this encryption mechanism with QUIC Crypto, which was a very simple protocol, and then decided to replace it with TLS 1.3. While this might make sense for the web, it doesn't really make sense in other settings where simpler security protocols could be used. This is what I talked about in more length in this blog post. Go read it before reading the rest of this post, I'll wait.
You read it? Nice. Well you'll be delighted to see that the nQUIC I've talked about in the first line of this article is exactly what I've been talking about: QUIC secured by the Noise Protocol Framework instead of TLS 1.3.
You can read about the research here. What we found is that it is extremly easy to integrate Noise into QUIC, because it was made to be encapsulated into a lower protocol, whereas integrating TLS 1.3 into QUIC is very hackish. It is also faster, because of the lack of signatures. It is way more secure, thanks to the lack of complexity and x509 parsing as well as the symbolic proofs provided by the research community (see for example NoiseExplorer, and its wonderful talk at Real World Crypto 2019). Finally, we have also added post-compromise security to the protocol, which is a must for long-lived sessions.
After spending many years working in information security, as a consultant, I've had the chance to audit a multitude of different systems invented and developed by many different people. While there is a lot to say about that, the focus of this article is about some of the toxicity I've noticed in the field.
If you're like me, you must have heard the security jokes about developers during conferences, read the github issues of independent researchers yelling at volunteering contributors, or maybe witnessed developer shaming in whitepapers you read. Although it is (I believe) a minority, it is a pretty vocal one that has given a bad rap to security in general. Don't believe me? Go and ask someone working at a company with an internal security team, or read what Linus has to say about it. Of course different people at different companies will have different kind of experiences, so don't take this post as a generalization.
It is true that developers often don't give a damn about security. But this is not a good reason to dismiss them. If you work in the field, it is important to ask yourself "why?" first. And if you're a good person, what should follow next is "how can I help?".
Why? It might not be totally clear to people who have done little to no (non-security focused) development, but the mindset of someone who is writing an application is to build something cool. Imagine that you're trying to ship some neat app, and you realize that you haven't written the login page yet. It now dawns on you that you will have to figure out some rate-limiting password attempt mechanism, how to store the passwords, a way for people to recover their passwords, perhaps even two-factor authentication... But you don't want to do all of that, do you? You just want to write the cool app. You want to ship... Now imagine that after a few days you get everything done, and now some guy that you barely know is yelling at you because there is an exploitable XSS in your application. You almost hear yourself saying out loud "an XX-what?" and here goes your week end, perhaps even your week you start thinking. You will have to figure out what is going on, respond to the person who brought the bug, attempt to fix it. All of that while trying to minimize the impact on your personal reputation. And that's if it's only a single bug.
I have experienced this story of myself. Years ago, I was trying my hands with a popular PHP web framework of the time, when one of the config file asked from me to manually modify it in order to bootstrap the application. Naturally, I obliged, until I reached a line reading
// you must fill this value with a 32-random-characters key
$config['encryption_key'] = "";
Being pretty naive at the time, I simply wrote a bunch of words until I managed to get to the required number of letters (32). It must have looked like something like this:
// you must fill this value with a 32-random-characters key
$config['encryption_key'] = "IdontKnowWhatImDoing0932849jfewo";
Was I wrong? Or was it the framework's fault for asking me to do this in the first place? You got the idea: perhaps we should stop blaming developers.
How can you help? Empathize. You will often realize that security people who have worked non-security development jobs at some point in their career will often understand the developers better AND will manage to get them to fix things. I know, finding bugs is cool, and we're here to hack and break things. But some of these things have people behind them, the codebase is sometimes their own labor of love, their baby. Take the time to teach them about was is wrong, if they don't understand they won't be able to fix the issues effectively. Use language to vehiculate your ideas, sure it is a critical finding but do you need to write that on a github issue to shame someone? Perhaps the word "important" is better? Put yourself in their shoes and help them understand that you're not just coming here to break things, but you're helping them to make their app a better one! How awesome is that?
Sure they need to fix things and take security seriously. But how you get to there is as important.
I also need to mention that building better APIs for developers is an active area of research. You can't educate everyone, but you can contribute: write good tutorials (copy/pastable examples first), good documentation, and safe-by-default frameworks.
Thank-you for reading this.
Your mission, should you choose to accept it, is to be an awesome security peep now :)
EDIT: Mason pointed me to this article which I think has some really good points as well:
Another element of a critique-focused report involves the discussion of positive findings of the assessment. As the saying goes, a spoonful of sugar makes the medicine go down.
And indeed, If I liked what I've seen during an audit, I always start a discussion by telling the developers how much I liked the code/protocol/documentation. They are always really happy to hear it and my followed-up critiques are heard way more seriously. Interestingly enough, I've always felt like this is how a good performance-review should go as well.
In my free time in the last years, I have helped (for free) some VCs and friends to figure out what are good opportunities in the cryptography field. I'm at an excellent position to see what is serious cryptography, and even what a promising start up looks like. This is because my day-to-day job is to audit them.
It turns out that it is often quite easy to quickly spot the bad grapes by noticing common red flags. Here's a list of key words that you should probably stay away from: patented, proprietary protocol, one-time pad, AES-256, unbreakable, post-quantum, ICO, supply-chain, AI, machine learning, prime numbers, re-inventing TLS, etc.
In general, if a company focuses its pitch on the actual crypto they use instead of the problems they solve, you might want to turn around. If something doesn't seem right, find an expert to help you. Even Ycombinator got fooled.
I like drawing, and I haven't drawn in a long time. I figured I could use crypto as an excuse to draw something and start this year in a more creative way :)
Here I glance over a lot of the concepts. I don't explain what is Elgamal or how it works, I don't explain proofs based on games and what semantic security is (and why it is considered insufficient), I don't even explain what I mean by an adversary's advantage. I'm expecting that you will read that on your own and then head here to understand how you can use all of that to prove Elgamal's semantic security.
I've participated in multiple public audits since I've started working at the Cryptography Services of NCC Group. People can often see my work through the research I do, but a good chunk of my time is spent auditing and breaking real world applications. NCC Group sometimes release public reports and I think it is a good opportunity for outsiders to see what I work on, and what the audit-part of my work looks like.
Unfortunately we rarely release much details when we find critical vulnerabilities, so the more interesting reports are always partially published (like the Google one) or just not public. One day I'll find a way to talk about (without leaking out any information about clients of course) some of the juicy findings I and others have found in my years of consulting. Some of these war stories are extremely entertaining. We sometimes don't find much, but when we completely break a cryptocurrency or a company's flagship product, it feels like we're the best in the world at what we do.
On May 15th, I approached Yuval Yarom with a few issues I had found in some TLS implementations. This led to a collaboration between Eyal Ronen, Robert Gillham, Daniel Genkin, Adi Shamir, Yuval Yarom and I. Spearheaded by Eyal, the research has now been published here. And as you can see, the inventor of RSA himself is now recommending you to deprecate RSA in TLS.
We tested 9 different TLS implementations against cache attacks and 7 were found to be vulnerable: OpenSSL, Amazon s2n, MbedTLS, Apple CoreTLS, Mozilla NSS, WolfSSL, and GnuTLS. The cat is not dead yet, with two lives remaining thanks to BearSSL (developed by my colleague Thomas Pornin) and Google's BoringSSL.
The issues were disclosed back in August and the teams behind these projects were given time to resolve them. Everyone was very cooperative and CVEs have been dispatched (CVE-2018-12404, CVE-2018-19608, CVE-2018-16868, CVE-2018-16869, CVE-2018-16870).
The attack leverages a side-channel leak via cache access timings of these implementations in order to break the RSA key exchanges of TLS implementations. The attack is interesting from multiple points of view (besides the fact that it affects many major TLS implementations):
It affects all versions of TLS (including TLS 1.3) and QUIC. Where the latter version of TLS does not even offer an RSA key exchange! This prowess is achieve because of the only known downgrade attack on TLS 1.3.
It uses state-of-the-art cache attack techniques. Flush+Reload? Prime+Probe? Branch-Predition? We have it.
The attack is very efficient. We found ways to ACTIVELY target any browsers, slow some of them down, or use the long tail distribution to repeatdly try to break a session. We even make use of lattices to speed up the problem.
Manger and Ben-Or on RSA PKCS#1 v1.5. You heard of Bleichenbacher's million messages attack? Guess what, we found better. We use Manger's OAEP attack on RSA PKCS#1 v1.5 and even Ben-Or's algorithm which is more efficient than and was published BEFORE Bleichenbacher's work in 1998. I uploaded some of the code here.
To learn more about the research, you should read the white paper. I will talk specifically about protocol-level exploitation in this blog post.
Attacking RSA, The Origins
While Ben-Or et al. research was initially used to support the security proofs of RSA, it was none-the-less already enough to attack the protocol. But it is only in 1998 that Daniel Bleichenbacher discovers a padding oracle and devise his own practical attack on RSA. The consequences are severe, most TLS implementations could be broken, thus mitigations were designed to prevent Daniel's attack. Follows a series of "re-discovery" where the world realizes that it is not so easy to implement such mitigations:
Bleichenbacher (CRYPTO 1998) also called the 1 million message attack, BB98, padding oracle attack on PKCS#1 v1.5, etc.
Let's be realistic, the mitigations that developers had to implement were unrealistic. Furthermore, an implementation that would attempt to log such attacks would actually help the attacks. Isn't that funny?
The research I'm talking about today can be seen as one more of these "re-discovery". My previous boss' boss (Scott Stender) once told me: "you can either be the first paper on the subject, or the best written one, or the last one". We're definitely not the first one, I don't know if we write that well, but we sure are hopping to be the last one :)
RSA in TLS?
Briefly, SSL/TLS (except TLS 1.3) can use an RSA key exchange during a handshake to negotiate a shared secret. An RSA key exchange is pretty straight forward: the client encrypts a shared secret under the server's RSA public key, then the server receives it and decrypts it. If we can use our attack to decrypt this value, we can then passively decrypt the session (and obtain a cookie for example) or we can actively impersonate one of the peer.
Attacking Browsers, In Practice.
We employ the BEAST-attack model (in addition to being colocated with the victim server for the cache attack) which I have previously explained in a video here.
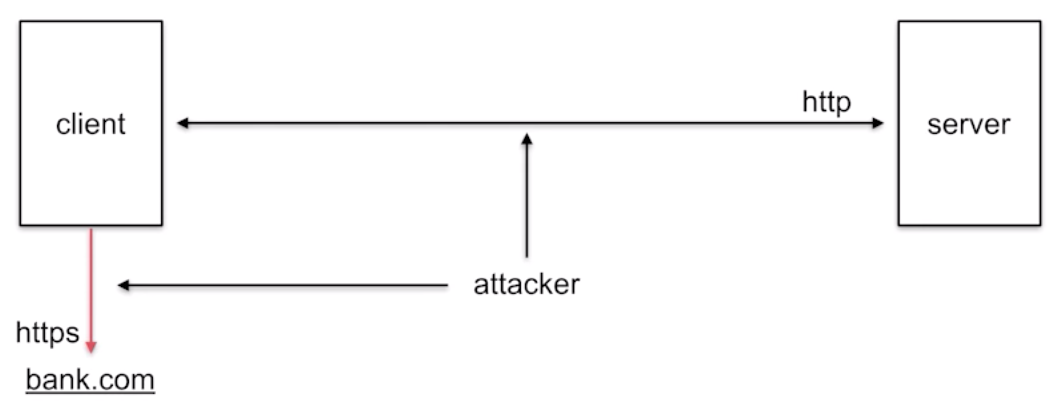
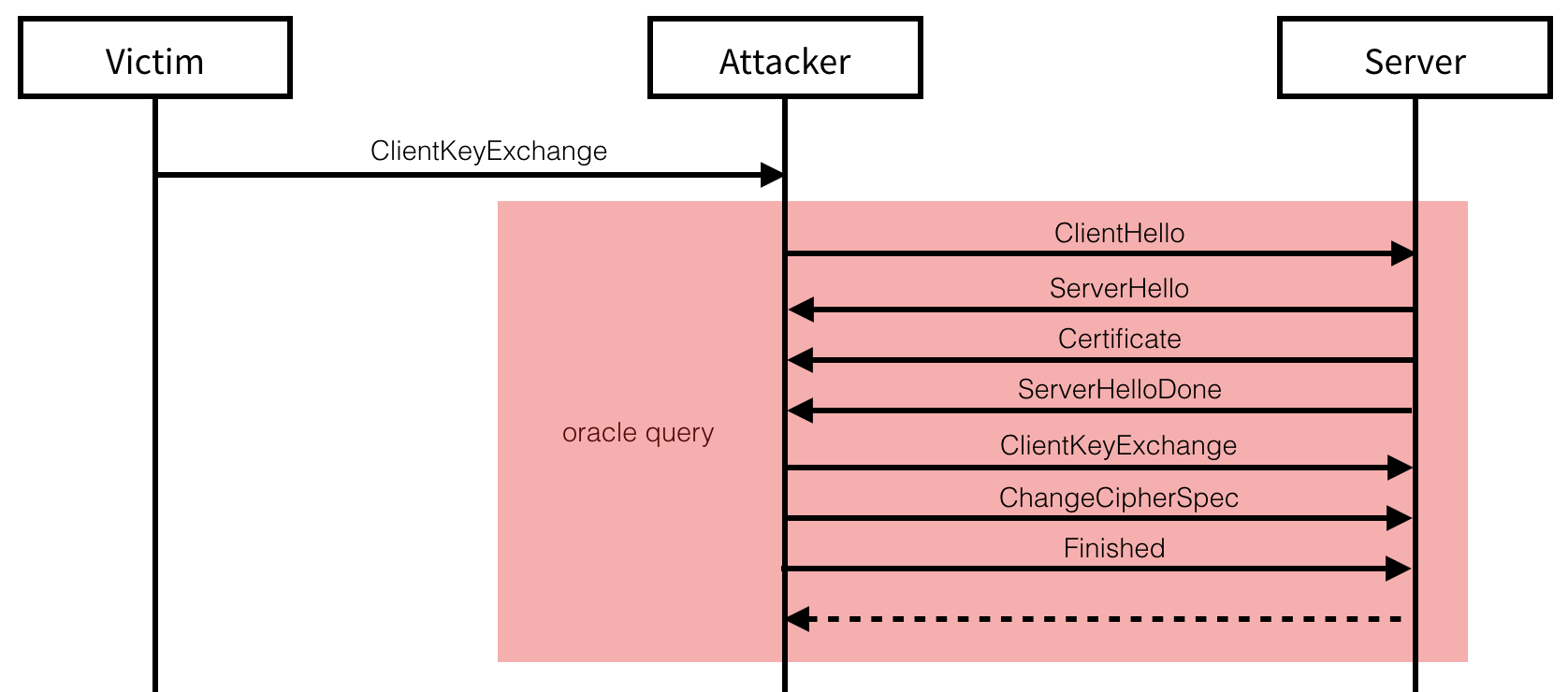
With this position, we then attempt to decrypt the session between a victim client (Bob) and bank.com: we can serve him with some javascript content that will continuously attempt new connections on bank.com. (If it doesn't attempt a new connection, we can force it by making the current one fail since we're in the middle.)
Why several connections instead of just one? Because most browsers (except Firefox which we can fool) will time out after some time (usually 30s). If an RSA key exchange is negotiated between the two peers: it's great, we have all the time in the world to passively attack the protocol. If an RSA key exchange is NOT negotiated: we need to actively attack the session to either downgrade or fake the server's RSA signature (more on that later). This takes time, because the attack requires us to send thousands of messages to the server. It will likely fail. But if we can try again, many times? It will likely succeed after a few trials. And that is why we continuously send connection attempts to bank.com.
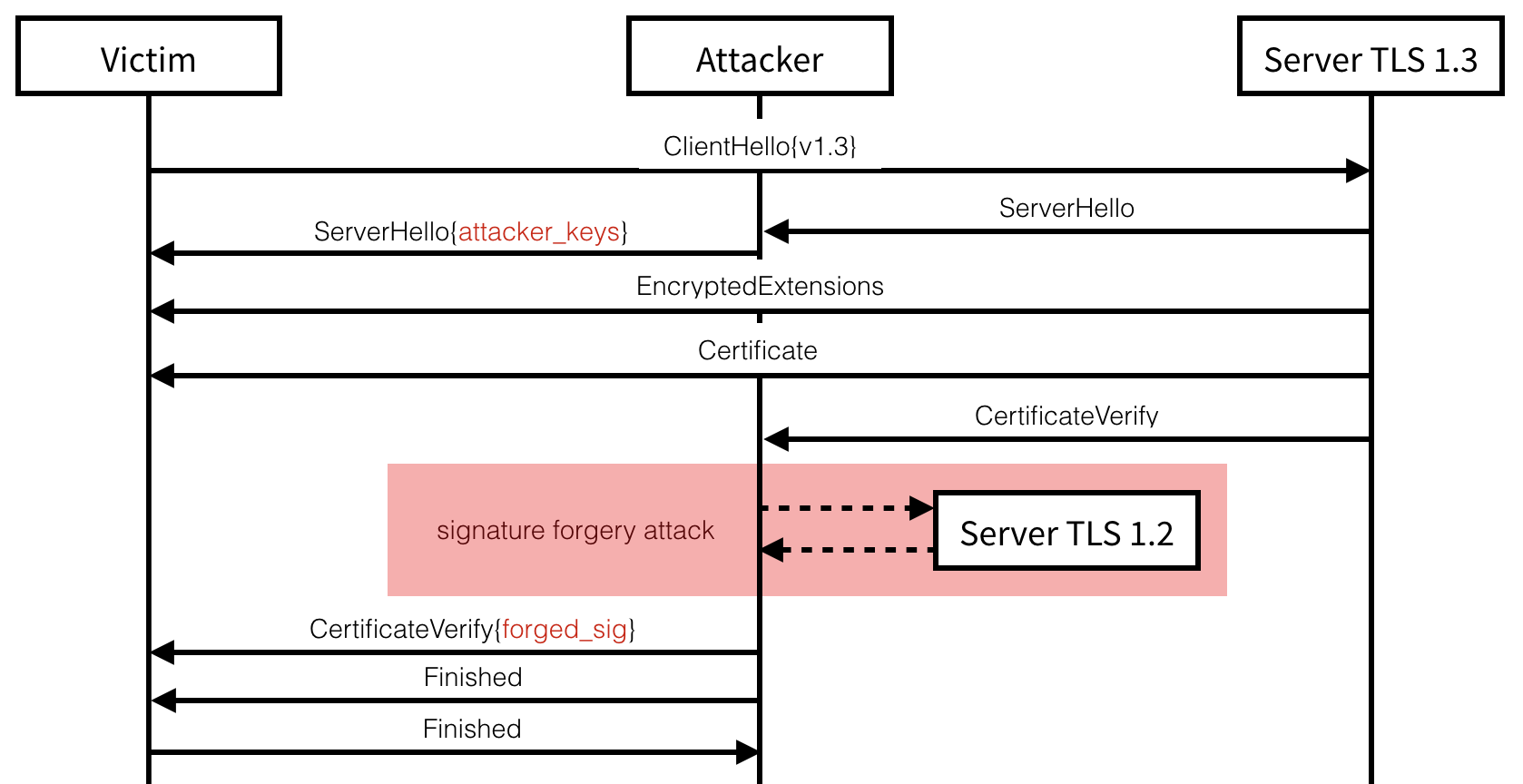
Attacking TLS 1.3
There exist two ways to attack TLS 1.3. In each attack, the server needs
to support an older version of the protocol as well.
The first technique relies on the fact that the current server’s public key is an RSA public
key, used to sign its ephemeral keys during the handshake, and that the
older version of TLS that the server supports re-use the same keys.
The second one relies on the fact that both peers support an older version
of TLS with a cipher suite supporting an RSA key exchange.
While TLS 1.3 does not use the RSA encryption algorithm for its key
exchanges, it does use the signature algorithm of RSA for it; if the
server’s certificate contain an RSA public key, it will be used to sign
its ephemeral public keys during the handshake. A TLS 1.3 client can
advertise which RSA signature algorithm it wants to support (if any)
between RSA and RSA-PSS. As most TLS 1.2 servers already provide support
for RSA , most will re-use their certificates instead of updating to the
more recent RSA-PSS. RSA digital signatures specified per the standard
are really close to the RSA encryption algorithm specified by the same
document, so close that Bleichenbacher’s decryption attack on RSA
encryption also works to forge RSA signatures. Intuitivelly, we have
$pms^e$ and the decryption attack allows us to find $(pms^e)^d = pms$,
for forging signatures we can pretend that the content to be signed
$tbs$ (see RFC 8446) is $tbs = pms^e$ and obtain $tbs^d$ via the attack, which is
by definition the signature over the message $tbs$. However, this
signature forgery requires an additional step (blinding) in the
conventional Bleichenbacher attack (in practice this can lead to
hundreds of thousands of additional messages).
Key-Reuse has been shown in the past to allow
for complex cross-protocol attacks on TLS. Indeed, we can successfully
forge our own signature of the handshake transcript (contained in the
CertificateVerify message) by negotiating a previous version of TLS
with the same server. The attack can be carried if this new connection
exposes a length or bleichenbacher oracle with a certificate using the
same RSA key but for key exchanges.
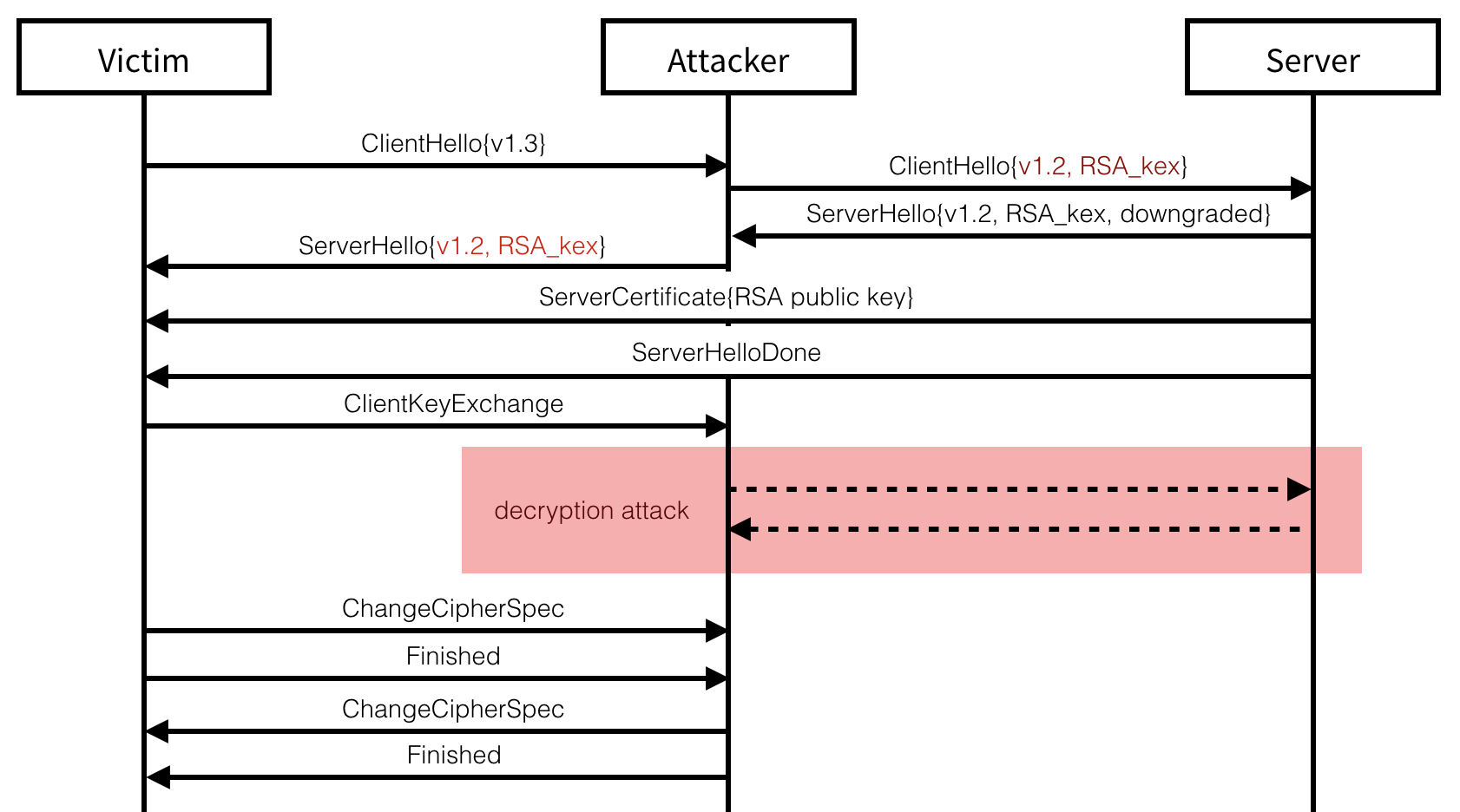
Downgrading to TLS 1.2
Every TLS connection starts with a negotiation of the TLS version and
other connection attributes. As the new version of TLS (1.3) does not
offer an RSA key exchange, the exploitation of our attack must first
begin with a downgrade to an older version of TLS. TLS 1.3 being
relatively recent (August 2018), most servers supporting it will also
support older versions of TLS (which all provide support for RSA key
exchanges). A server not supporting TLS 1.3 would thus respond with an
older TLS version’s (TLS 1.2 in our example) server hello message. To
downgrade a client’s connection attempt, we can simply spoof this answer
from the server. Besides protocol downgrades, other techniques exist to
force browser clients to fallback onto older TLS versions: network
glitches, a spoofed TCP RST packet, a lack of response, etc. (see POODLE)
Continuing with a spoofed TLS 1.2 handshake, we can simply present the
server’s RSA certificate in a ServerCertificate message and then end
the handshake with a ServerHelloDone message. At this point, if the
server does not have a trusted certificate allowing for RSA key
exchanges, or if the client refuse to support RSA key exchanges or older
versions than TLS 1.2, the attack is stopped. Otherwise, the client uses
the RSA public key contained in the certificate to encrypt the TLS
premaster secret, sends it in a ClientKeyExchange message and ends its
part of the handshake with a ChangeCipherSpec and a Finished
messages.
At this point, we need to perform our attack in order to decrypt the RSA
encrypted premaster secret. The last Finished message that we send must
contains an authentication tag (with HMAC) of the whole transcript, in
addition of being encrypted with the transport keys derived from the
premaster secret. While some clients will have no handshake timeouts,
most serious applications like browsers will give up on the connection
attempt if our response takes too much time to arrive. While the attack
only takes a few thousand of messages, this might still be too much in
practice. Fortunately, several techniques exist to slow down the
handshake:
we can send the ChangeCipherSpec message which might reset the client’s timer
Once the decryption attack terminates, we can send the expected Finished
message to the client and finalize the handshake. From there everything
is possible, from passively relaying and observing messages to the
impersonated server through to actively tampering requests made to it.
This downgrade attack bypasses multiple downgrade mitigations: one
server-side and two client-side. TLS 1.3 servers that negotiate older
versions of TLS must advertise this information to their peers. This is
done by setting a quarter of the bytes from the server_random field in
the ServerHello message to a known value. TLS 1.3 clients that end
up negotiating an older version of TLS must check for these values and
abort the handshake if found. But as noted by the RFC, “It does not
provide downgrade protection when static RSA is used.” – Since we alter
this value to remove the warning bytes, the client has no opportunity to
detect our attack. On the other hand, a TLS 1.3 client that ends up
falling back to an older version of TLS must advertise this information in their subsequent client hellos, since
we impersonate the server we can simply ignore this warning.
Furthermore, a client also includes the version used by the client hello
inside of the encrypted premaster secret. For the same reason as
previously, this mitigation has no effect on our attack. As it stands,
RSA is the only known downgrade attack on TLS 1.3, which we are the
first to successfuly exploit in this research.
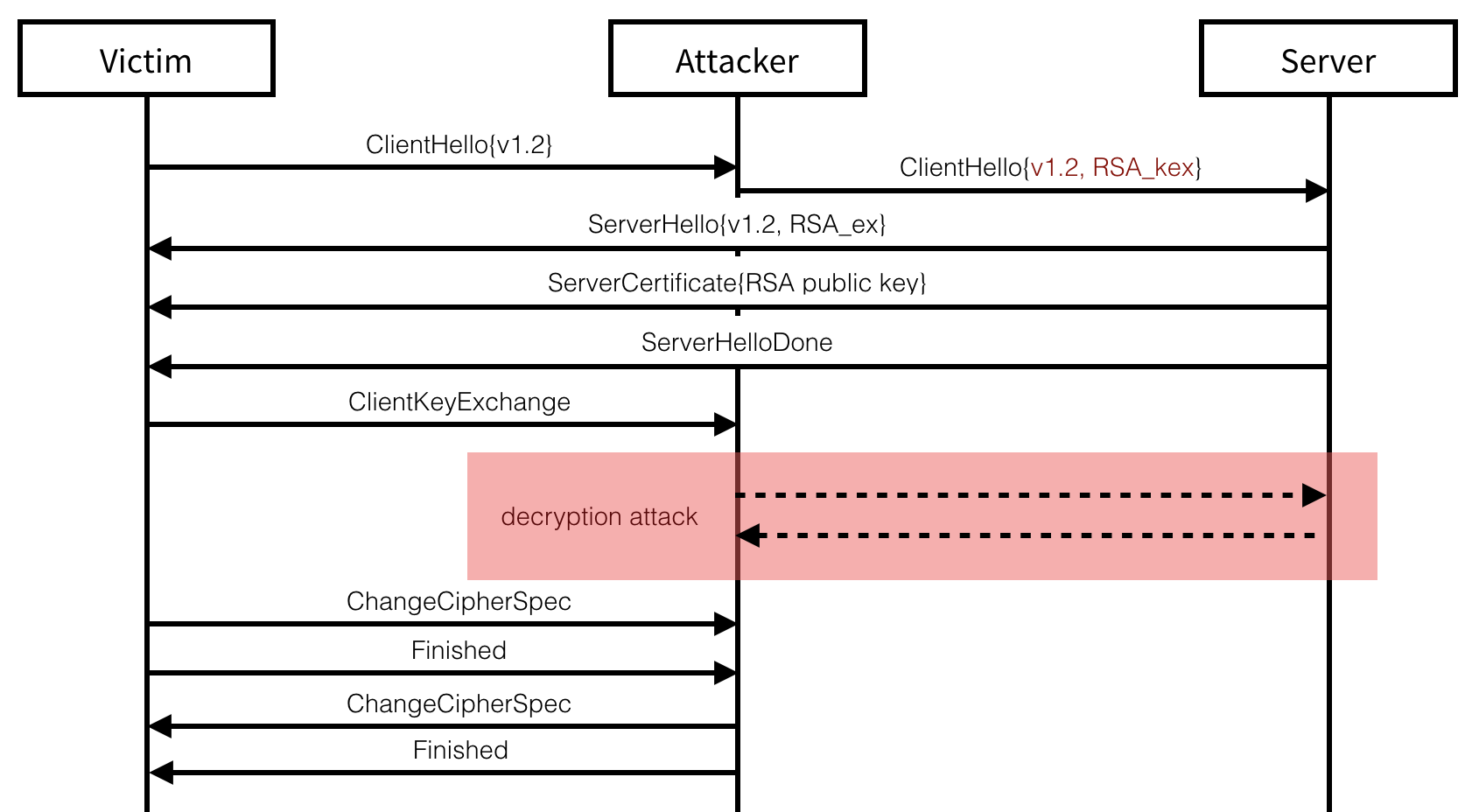
Attacking TLS 1.2
As with the previous attack, both the client and the server targetted
need to support RSA key exchanges. As this is a typical key exchange
most known browsers and servers support them, although they will often
prefer to negotiate a forward secret key exchange based on ephemeral
versions of the Elliptic Curve or Finite Field Diffie-Hellman key
exchanges. This is done as part of the cipher suite negotiation during
the first two handshake messages. To avoid this outcome, the
ClientHello message can be intercepted and modified to strip it out of
any non-RSA key exchanges advertised. The server will then only choose
from a set of RSA-key-exchange-based cipher suites which will allow us
to perform the same attack as previously discussed. Our modification of
the ClientHello message can only be detected with the Finished
message authenticating the correct handshake transcript, but since we
are in control of this message we can forge the expected tag.
On the other side, if both peers end up negotiating an RSA key exchange
on their own, we can passively observe the connection and take our time
to break the session.