
The missing explanation of ZK-SNARKs: Part 1 posted November 2020
What are ZK-SNARKs and how do they work? This is a question I’ve had for years, and always felt like the resources I found gave no clear intuition as to how all of that stuff worked. So today, after a breakthrough in my own understanding, I thought it would be good to re-share what I’ve learned in a more understandable picture. Something that tells you what is the right way of thinking about these things, and what are the gaps that you can fill for yourself if you want to.
Getting terminology out of the way
The first part of the question is pretty easy to answer. ZK-SNARKs, no matter what their funny name might imply, are simply zero-knowledge proofs that are:
- non interactive
- general purpose
- and succinct
Huh, what are all these words? you ask, intimidated by their vagueness.
Well first, zero-knowledge proofs are cryptographic proofs that you know something, without revealing the something (zero-knowledgeness). That “something” is usually called the witness, but this detail doesn’t matter much. There are a lot of resources about zero-knowledge proofs so I won’t explain much about how they work, or what their exact cryptographic properties are (completeness, soundness, zero-knowledgeness).
Zero-knowledge proofs are often seen used to prove that you know the discrete logarithm in some base of an element of some group (e.g. what is $x$ in $g^x \mod p$), or similarly-limited statements.
“Limited yes, but still useful!” yells Schnorr, inventor of the Schnorr signature scheme which is fabricated by taking a zero-knowledge proof of the knowledge of a discrete logarithm, and making it non-interactive. A zero-knowledge proof or ZKP is an interactive protocol between a prover (who knows the witness) and a verifier (who has to be convinced). An interactive protocol sucks in the real world, as it often limits the number of potential use-cases of the primitive, and slows down protocols depending on the number of round trips that need to happen between the prover and the verifier. Fortunately, some ZKPs can be constructed without interaction with a verifier. In other words, a prover can simply create a proof, and that proof can be verified by anyone at any point in time later without further help from the prover. When ZKPs are made non-interactive, we simply call them non-interactive zero-knowledge proofs or NIZKs. I talk more about the link between signatures and zero-knowledge proofs here.
ZKPs and NIZKs can also be constructed on much more general statements like “I know an input to some function such that the execution gives some output”, or more specifically “I know $a$ in $f(a, b) = c$”. If this still doesn’t make sense think about the usual example given to illustrate general-purpose ZKPs: “I know the solution of the sudoku”.
We’re almost there: ZK-SNARKs are general-purpose non-interactive zero-knowledge proofs, and more! They are also succinct, meaning that the proofs they produce are small in size and are fast to verify, which makes them so special they deserve to be called ZK-SNARKs. Not every modern proof systems deserve that special classification, for example STARKs don’t :(
As a recap:
- zero-knowledge proof: a cryptographic proof that you know something, without revealing the something
- non interactive: a proof that was constructed without the help of a verifier
- general purpose: a proof of a more general statement, like the knowledge of secret inputs or outputs of a program
- succinct: a small proof that is fast to verify
But not only did you ask, what are ZK-SNARKs, but you also asked about how they work.
The actual stuff
And oh boy, this is a complex subject to answer. First and foremost, there are many many schemes, too many of them, and so I’m not sure exactly how to answer that question. But I have some idea of how some of them work, and so I imagine that most of them follow that pattern, or improve on it, so let me explain…
There’s two parts to your typical ZK-SNARK:
- The proving system, which I'll explain in this post.
- The translation or compilation of a program to something the proving system can prove, which I'll explain in part 2 of this post.
The first part is not too hard to understand, while the second sort of requires a graduate course into the subject…
Proving your knowledge of a constrained polynomial
Here it is, remember that one: ZK-SNARKs are all about proving that you know some polynomial $f(x)$ that has some roots. By roots I mean that the verifier has some values in mind (e.g. $1$ and $2$) and the prover must prove that the secret polynomial they have in mind evaluates to $0$ for this values (e.g. $f(1) = f(2) = 0$). By the way, a polynomial that has 1 and 2 as roots (in our example) can be written as $f(x)=(x-1)(x-2)h(x)$ for some polynomial $h(x)$. (If you’re not convinced try to evaluate that at $x=1$ and $x=2$.) So we say that the prover must prove that they know an $f(x)$ and $h(x)$ such that $f(x) = t(x)h(x)$ for some target polynomial $t(x) = (x-1)(x-2)$ (in the example that $1$ and $2$ are the roots that the verifier wants to check).
But that’s it, that’s what ZK-SNARKs proving systems usually provide: something to prove that you know some polynomial. I’m repeating this because the first time I learned about that it made no sense to me: how can you prove that you know some secret input to a program, if all you can prove is that you know a polynomial. Well, that’s why part 2 of this explanation is so difficult: it’s about translating a program into a polynomial. But more on that later.
Back to our proving system, how does one prove that they know such a function $f(x)$? Well they just have to prove that they know an $h(x)$ such that you can write $f(x)$ as $f(x) = t(x)h(x)$. Ugh… Not so fast here. We’re talking about zero-knowledge proofs right? How can we prove this without giving out $f(x)$? Well, by using three tricks!
- homomorphic commitments
- bilinear pairings
- different polynomials evaluate to different values most of the time
So let's go through each of them shall we?
Homomorphic commitments
The first trick is to use commitments to hide the values that we’re sending to the prover. But not only do we hide them, we also want to allow the verifier to perform some operations on them so that they can verify the proof. Specifically verify that if the prover commits on their polynomial $f(x)$ as well as $h(x)$, then we have $$ com(f(x)) = com(t(x)) com(h(x)) = com(t(x)h(x)) $$
where $com(t(x))$ is computed by the verifier as these are the known constraints on the polynomial. These operations are called homomorphic operations and we can’t perform them if we use hash functions as commitment mechanisms. Instead, we can simply “hide the values in the exponent” (e.g. for a value $v$ then send the commitment $g^v \mod{p}$) as these are commitments that allow for these homomorphic operations. (To convince yourself, observe that if $a = bc$ then $g^a = g^b g^c = g^{b+c}$.
Wait, this is not what we wanted… we wanted $g^a = g^{bc}$.
Bilinear pairings
$g^a = (g^b)^c = g^{bc}$ gets us there, but only if $c$ is a known value and not a commitment (e.g. $g^c$). Unfortunately this is a limitation for our proving protocol, as there will be multiplication operations between commitments. This is where bilinear pairings can be used to unblock us, and this is the sole reason why we use bilinear pairings in a ZK-SNARK (really just to be able to multiply the values inside the commitments). I don’t want to go too deep into what bilinear pairings are, but just know that it is just another tool in our toolkit that:
- Takes two values of our group (the values generates by $g$ raised to different powers modulo $p$) and place them in another group.
- By moving stuff from one group to the other, we can multiply things that couldn't be multiplied previously.
So using $e$ as the typical way of writing a bilinear pairing, we have $e(g_1, g_2) = h_3$ and we can use it to perform multiplications hidden in the exponent via this one equation:
$$ e(g^b, g^c) = e(g)^{bc} $$
But no more about bilinear pairings! Again that’s the only reason why we use these in ZK-SNARKs. It’s just a trick to make our homomorphic commitments more homomorphic, to allow us to do:
$$ com(f(x)) = com(t(x)) com(h(x)) = com(t(x)h(x)) $$
Where does the succinctness comes from?
Finally, the succinctness of ZK-SNARKs come from the fact that two functions that differ will evaluate to different points most of the time. What this means for us is that if my $f(x)$ is not really equal to $t(x)h(x)$, meaning that I don’t have a polynomial $f(x)$ that really has the roots we’ve chosen with the verifier, then evaluating $f(x)$ and $t(x)h(x)$ at a random point $r$ will not give out the same result (most of the time). In other words for almost all $r$, $f(r) \neq t(r)h(r)$.
This is known as the Schwartz-Zippel lemma, which I pictured in the following illustration.
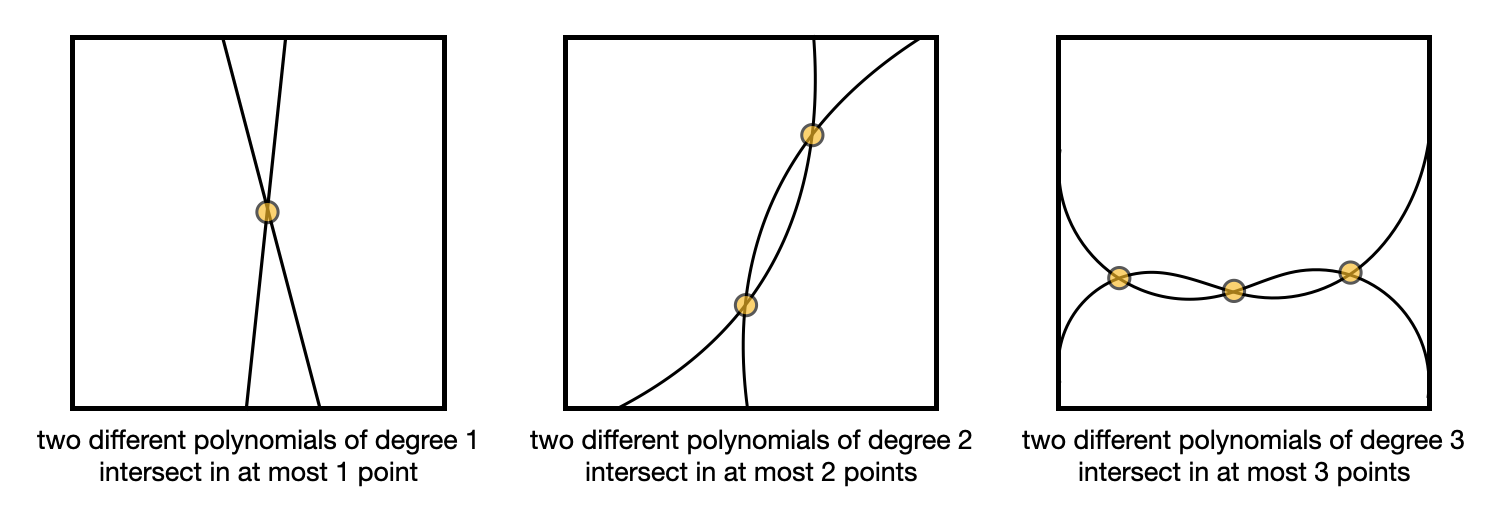
Knowing this, it is enough to prove that $com(f(r)) = com(t(r)h(r))$ for some random point $r$. This is why ZK-SNARKs are so small; by comparing points in a group you end up comparing entire polynomials!
But this is also why there is a “trusted setup” needed before most ZK-SNARKs can work. If a prover learns the random point $r$, then they can forge bad polynomials that will verify. So a trusted setup is about:
- creating a random value $r$
- committing different exponentiation of it $g^r, g^{r^2}, g^{r^3}, \ldots$ so that they can be used by the prover to compute their polynomial without knowing the point $r$
- destroying the value $r$
Does the second point makes sense? If my polynomial as the prover is $f(x) = x^2 + x$ then all I have to do is compute $g^{r^2} g^r$ to obtain a commitment of my polynomial evaluated at that random point $r$.

Comments
Troy Rose
Been wondering for a while about how ZK-SNARKS work ever since reading the zero coin whitepaper!
Excited to read the next part!!
leave a comment...