Quick access to articles on this page:
more on the next page...
Some of you might have seen the answer of this famous stack overflow question what are the differences between a digital signature, a mac and a hash?:
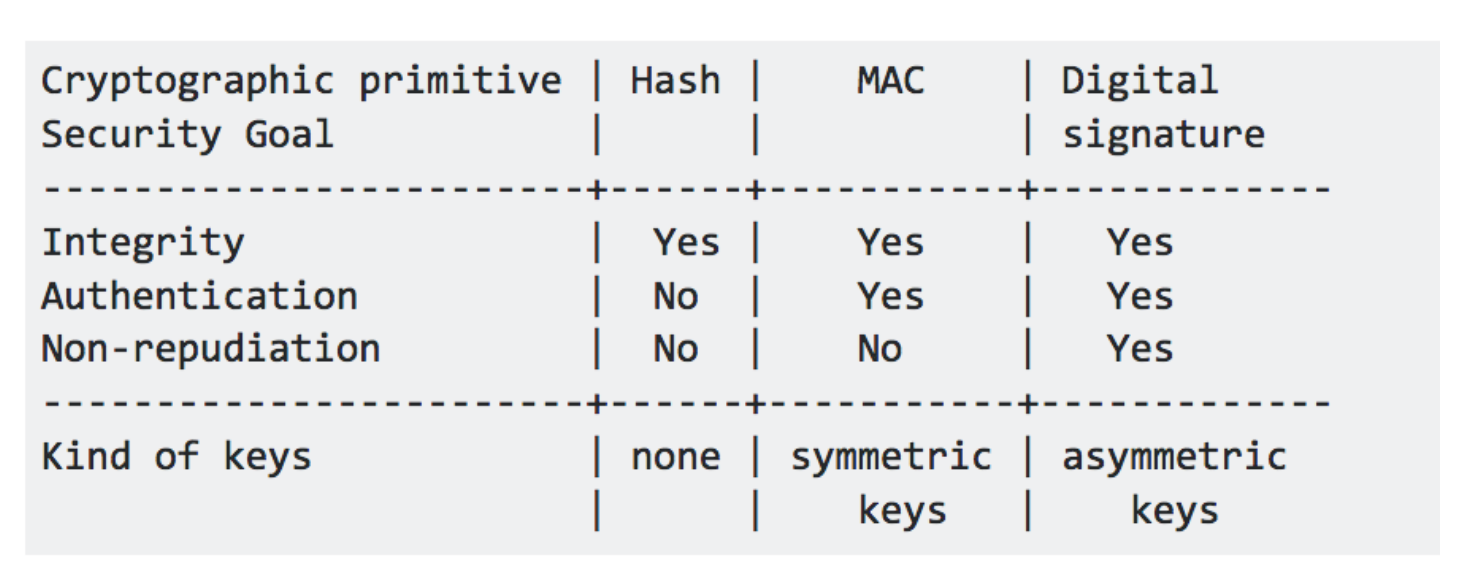
The above table is from the most upvoted answer --but it is false. A hash function does not provide integrity, a MAC provides integrity.
Instead a cryptographic hash function provides three properties, well defined in the world of cryptography: collision resistance, pre-image resistance and second pre-image resistance. Nothing else.

cSHAKE is something to make your own SHAKE! It's defined in this NIST's doc SP 800-185 along other awesome Keccak structures like KMAC (a message authentication code a la hash(key + data) with no length-extension attacks!) and TuppleHash (a hash function to hash structures without ambiguity (fingerprints!)).
And without surprises, it suffers from the same SHA-3 bit ordering problems I talked about in this blogpost and this one as well.
So I thought it would be a good opportunity for me to talk more about SHAKE, cSHAKE and remind you how the bit ordering works!
What is SHAKE?
SHAKE (Secure Hash Algorithm and KECCAK), defined in FIPS 202, is an Extendable-Output Function (or XOF). It's like SHA-3 but with an infinite output. For whatever length you need. You can use that as a KDF, a PRNG, a stream cipher, etc ...
It's based on The Keccak permutation function, and it works pretty much like SHA-3 does. The two differences are that a different domain separator is used (1111 is appended to the input instead of 01 for SHA-3) and you can continue to squeeze the sponge as much as you like (whereas SHA-3 defines how much you should squeeze).
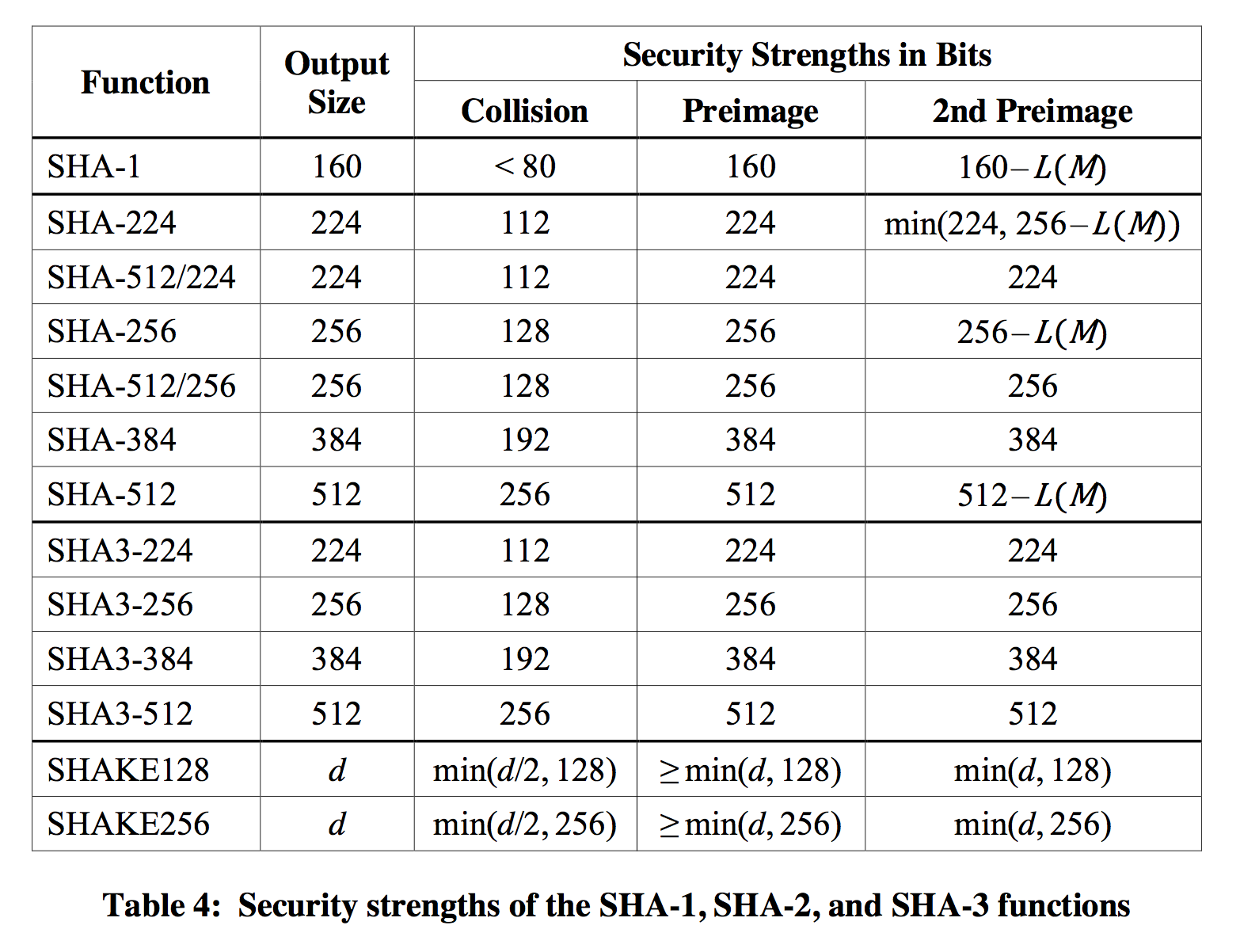
Of course the squeezing will affect the security of your output, if used as a hash you can expect to have 128-bit security against all attacks (including collision resistance) when using an output of 256-bit. If you truncate that down to 128-bit, you will get rid of the collision resistance property but still have (at least) 128-bit security against pre-image attacks. More information is available in the FIPS 202 document where you will find this table in Appendix A:
cSHAKE
SHA-3 and SHAKE were great constructions, but Keccak has so much to offer that the NIST had to release another document: SP 800-185 (for "special publication"). It covers some other constructions (as I said previously), but this is still not the extent of what is possible with Keccak. If you're interested, check KangarooTwelve (which is to SHA-3 what Blake2 is to Blake, a less secure but more efficient hash function), the duplex construction (use the sponge continuously!), Ketje and Keyak (two authenticated encryption modes), ...
SP 800-185 defines cSHAKE as a customable version SHAKE. It works the same except that you have one new input to play with: a customization string. If you've used HKDF before you will quickly get its purpose: avoid collisions between different usages of the Shake function. Here are two examples given by the NIST special publication:
cSHAKE128(input: public_key, output: 256 bits, "key fingerprint"), where "key fingerprint" is the customization string.cSHAKE128(input: email_contents, output: 256 bits, "email signature")
how it works
As with SHAKE, you can choose an output length, here is how the input and the customization string gets fed to the cSHAKE function:
- Use an empty
N string (this is for NIST use only)
- Choose a customization string
S
- apply
encode_string() on the empty string N and on your customization string S
- apply the
bytepad function to both with the rate of the permutation in bytes (168 in the case of cSHAKE128).
- prepend this to your input
- append the bits
00 to your input (domain separator)
KECCAK(bytepad(encode_string(N) || encode_string(S), 168) || input || 00)
What are these functions?
encode_string: left_encode(len(input)) || input.
left_encode: a way to encode a length. It encodes the length of the length, then the length :) all of that in an LSB bit numbering.
bytepad: left_encode(block_size) | input | 0000...0000 with enough 0s for the resulting output to be a byte array multiple of the rate.
The above function can be rewritten:
KECCAK(left_encode(block_size) || left_encode(0) || "" || left_encode(len(S)) || S || 0000...0000 || input || 00)
(This input will then get padded inside of Keccak.)
left_encode
These functions are defined in the special publication NIST document, but they are quite different in the reference implementation).

So here is another explanation on this bit re-ordering trick. Imagine that we have this input to the left_encode function:
0001 0000 | 0011 0001 | 0111 1110
As an hex table it would look like this:
0x10 | 0x31 | 0x7e
Now, the left_encode specification tells us to completely reverse this value, then add a reversed length on the left (here 3). It would look like this:
0111 1110 | 1000 1100 | 0000 1000
1100 0000 | 0111 1110 | 1000 1100 | 0000 1000
This is quite annoying to code. Fortunately, the reference implementation has a trick: it takes the bytes as-is but re-position them following the little endian ordering convention, then add the padding in a natural MSB first bit numbering:
0111 1110 | 0011 0001 | 0001 0000
0000 0011 | 0111 1110 | 0011 0001 | 0001 0000
The Sponge code then re-interprets this in little endian convention:
0001 0000 | 0011 0001 | 0111 1110 | 0000 0011
Which is exactly what was expected, except in reversed order :) which is OK because if you remember correctly from my previous blogpost every operation of the spec is implemented in reversed in the reference implementations.
How to use cSHAKE?
The official Keccak Code Package contains all the keccak functions in C. I've written a Golang version of cShake here that you can put in your golang.org/x/crypto/sha3/ directory, as it hasn't been reviewed by anyone yet I would take this with chopsticks.
As I talked about in a previous blogpost, Keccak and SHA3-3 are different in their bit convention, which gave birth to quite an overly complicated specification. The lack of good explanations in both the reference implementations and the reference documents led me to write this blogpost.
Padding
Before going further, let me briefly re-explain the multi-rate padding also called pad10*1:
- take the input and append the delimiter (
01 for SHA-3)
- append a
1 to start the padding
- append enough
0s followed by a final 1 so that the resulting output is a multiple of the rate
Here is a graphical example with input 0x9c = 1001 1100 and where the rate of our permutation is only 3 bytes:
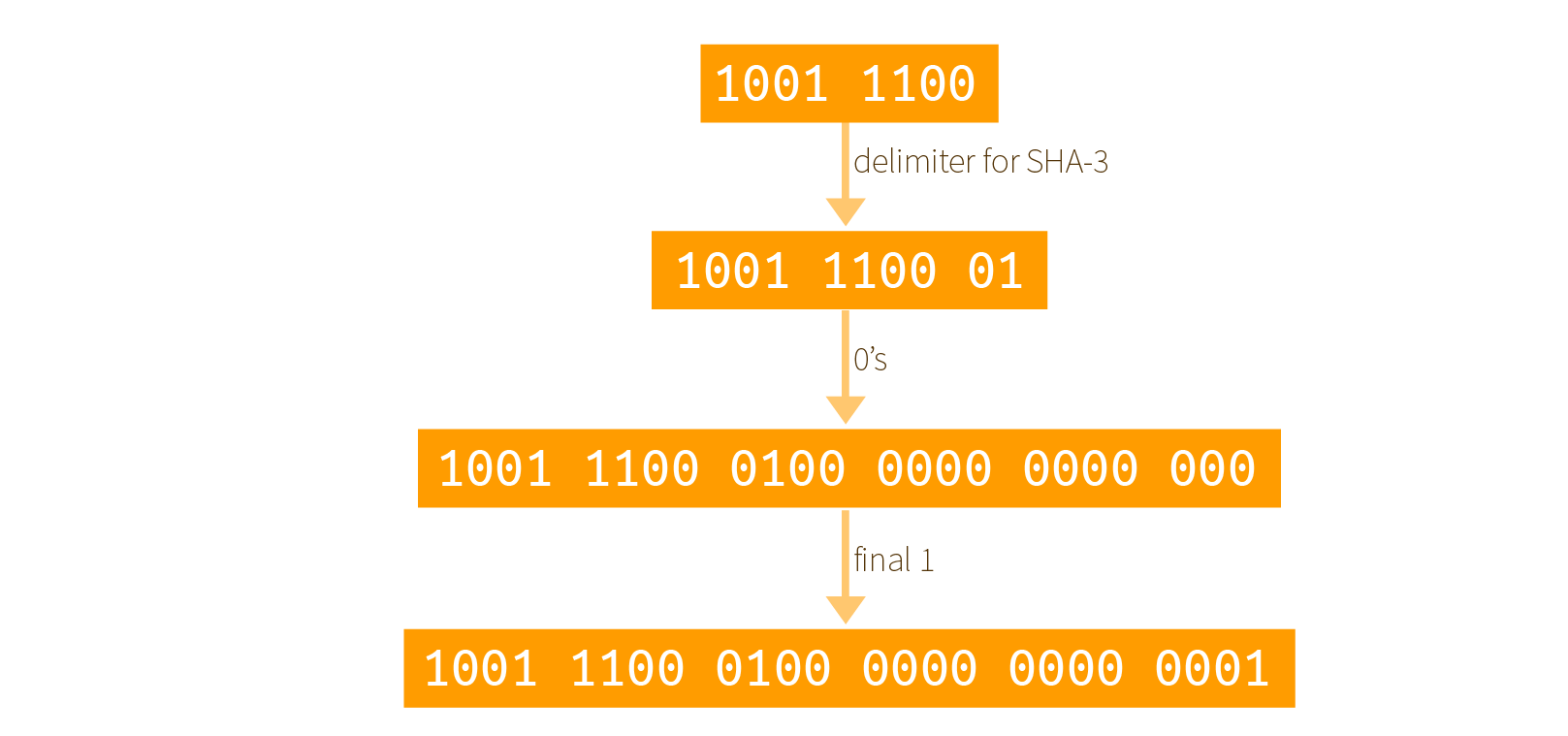
note that I forgot to add a 1 after the delimiter and before all the 0s (thanks Rachel)
Now, I'll just acknowledge that most implementations, and even the specification, talk about using 0x80 for the final bit. This blogpost should answer why.
Theoretical bit numbering
Keccak is specified in term of bits, but is discreetly aware of byte arrays as well. This is important as the rounds of Keccak require us to XOR parts of the input with lanes of the state. These lanes can be represented as uint64 types for keccak-f[1600], which we'll be looking at in this blogpost.
It could be hard to understand what is really going on in FIPS 202, but a look at an older version of the specification shows that Keccak interprets byte arrays in big-endian, but with an LSB bit numbering.
If you look at the Appendix B.1 of FIPS 202. You can see that before an input can be interpreted by SHA-3, it needs to go through some transformations.
Here is our own example of how it works with an input of 0xaebcdf. First the bits are re-mapped, then a padding is added, finally it is split into as many lanes as possible (here we have two 16-bit lanes):
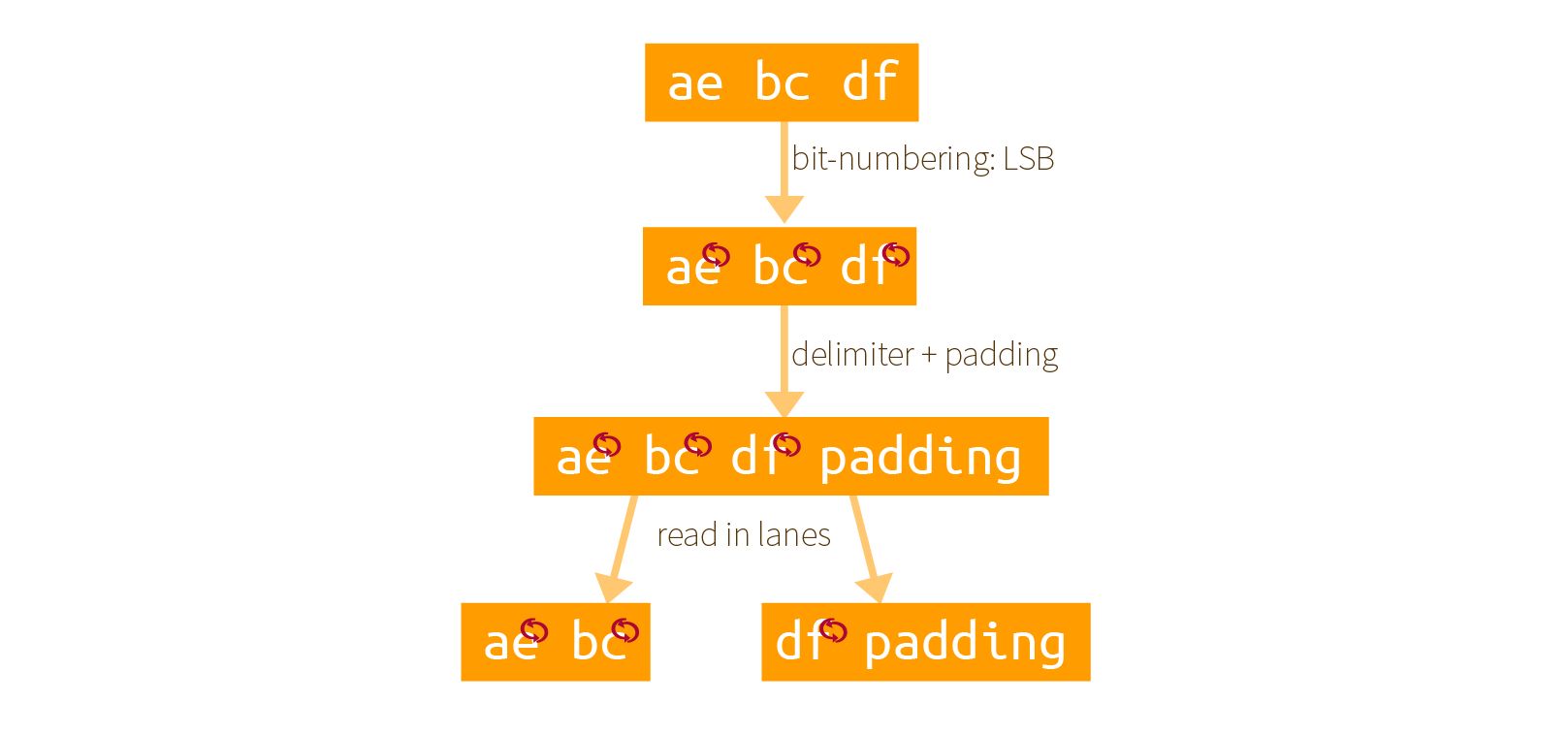
The same examples with bits:
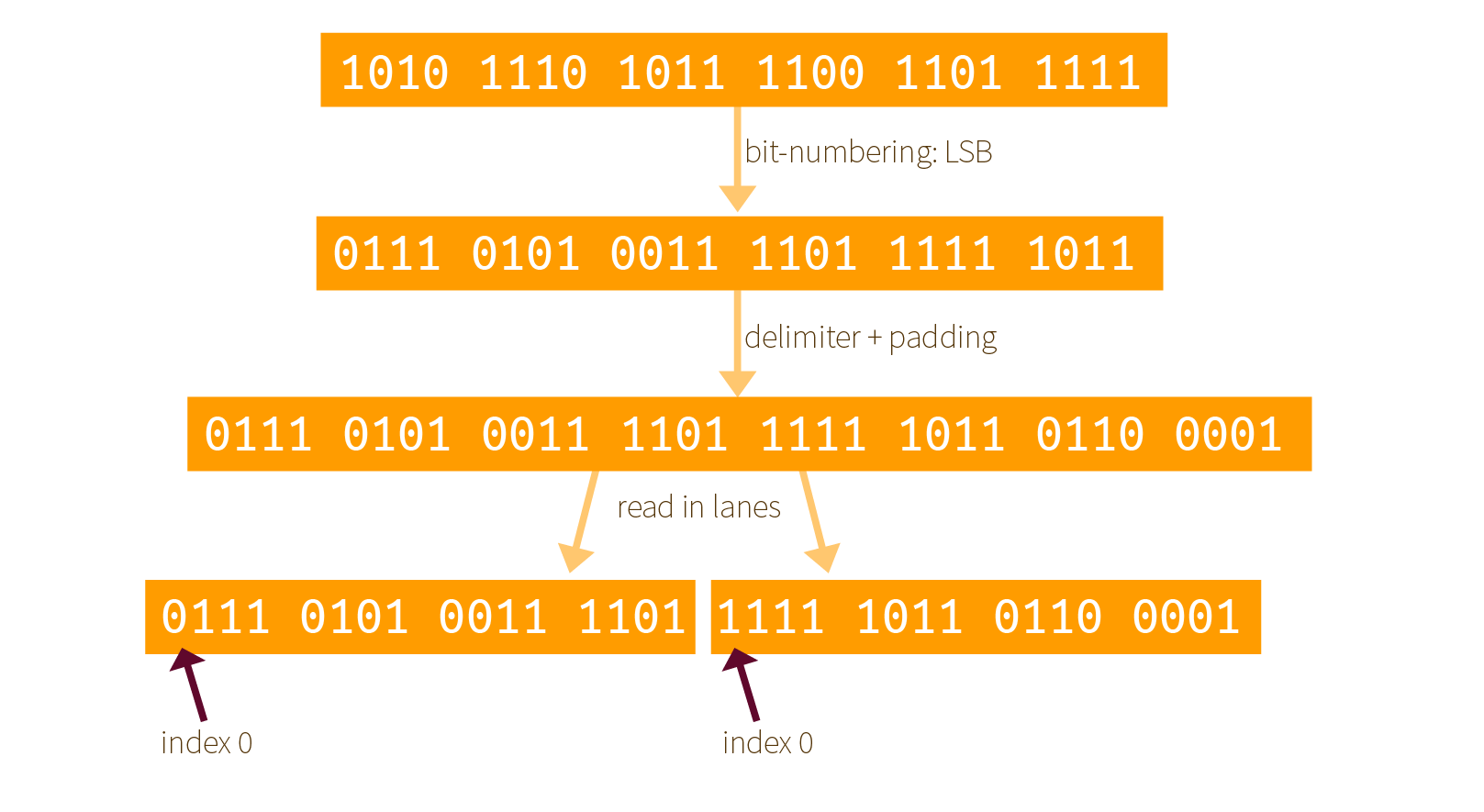
Two things that you must understand here:
- the padding is applied after re-mapping the bits, not before! Since the padding is already defined for Keccak's internal ordering of its bits.
- all of this is done so that a bit string is indexed as LSB first, not MSB first. It's weird but Keccak did it this way.
Why is the indexing of a bitstring so important?
Because we later apply the permutation function on the state, and some of the operations need to know what are the indexes of each bits. More on that later.
How to implement the re-mapping
It must be annoying to reverse all these bits right? What about not doing it? Well brace yourself, there is indeed a clever trick that would allow you to avoid doing this. And this trick is what is used in most of SHA-3's implementations. Here is a graphical explanation of what they do:
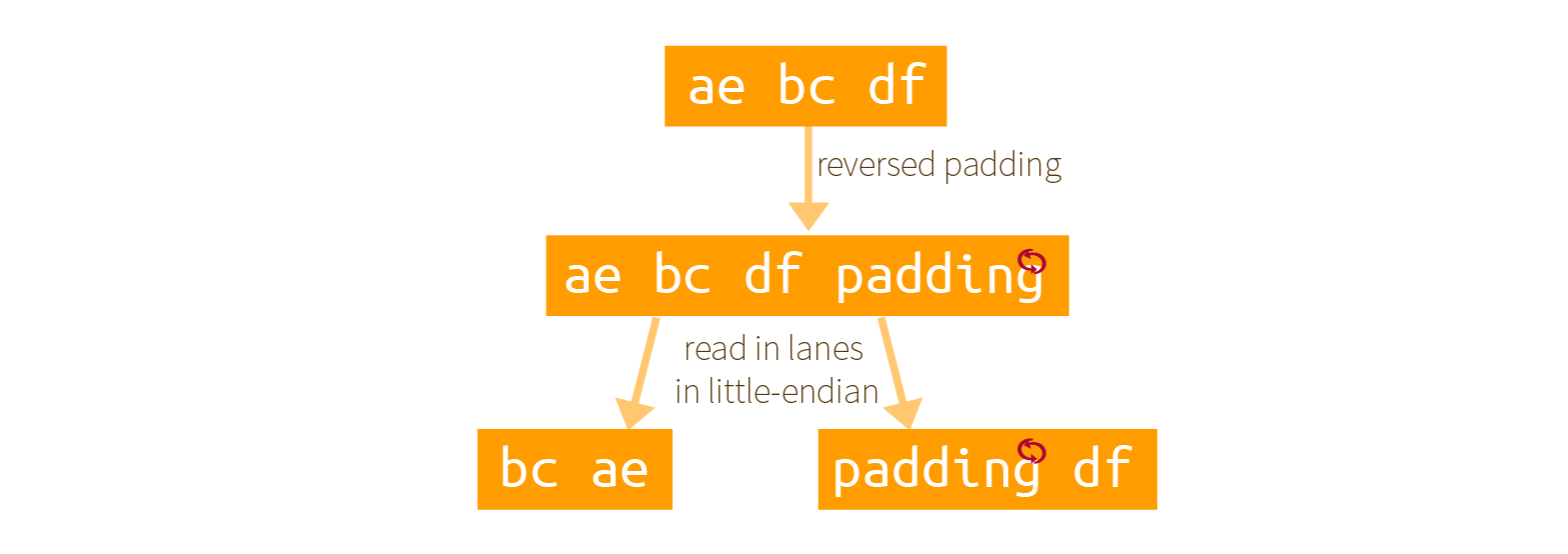
By reading the byte array as little-endian, and using an already reversed delimiter + padding, some magic happens!
The result is exactly the same but in reverse order.
If you aren't convinced look at the following diagram (which shows the same thing with bits) and look at the previous section result. Same, but the bitstream is readable in the reversed direction.
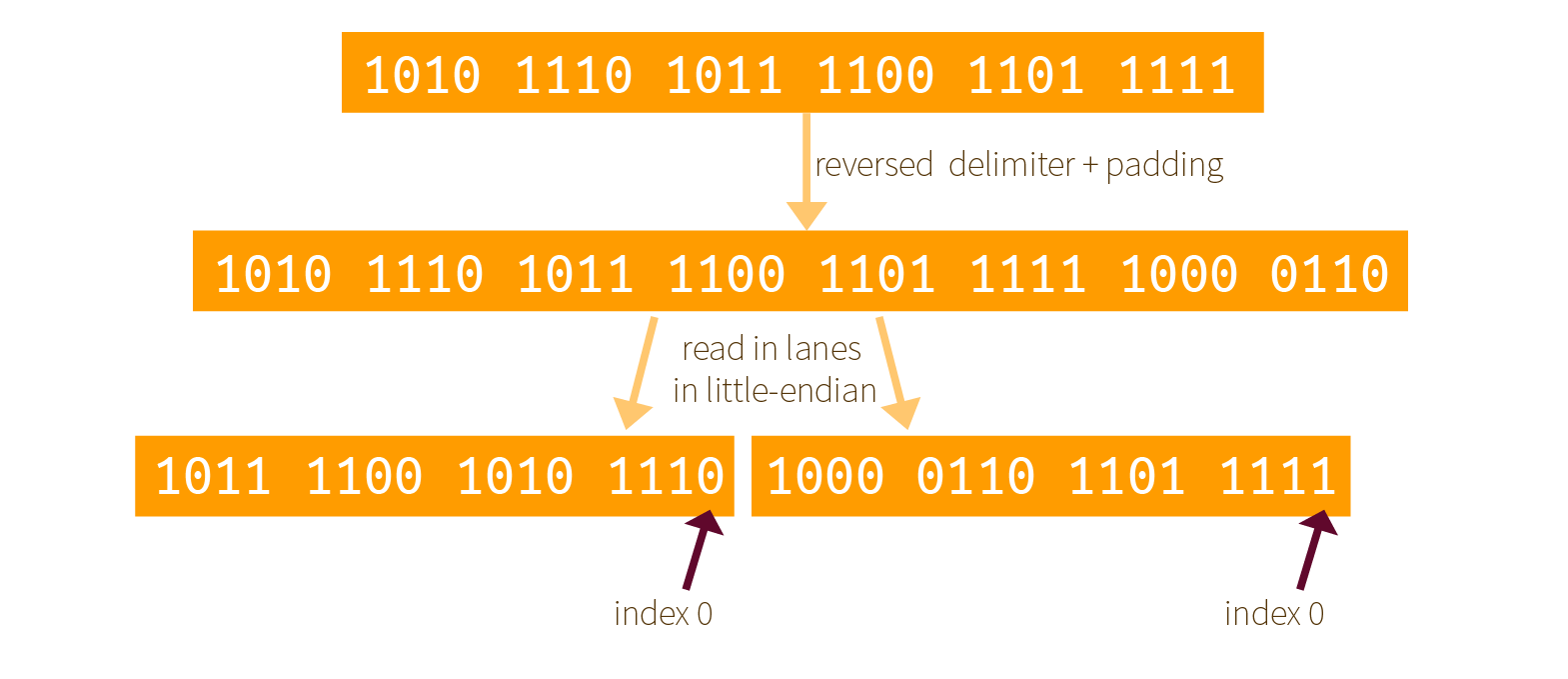
This means that now the index 0 of Keccak's internal ordering is on the right, not on the left. How will it influence the round functions that apply on our lanes?
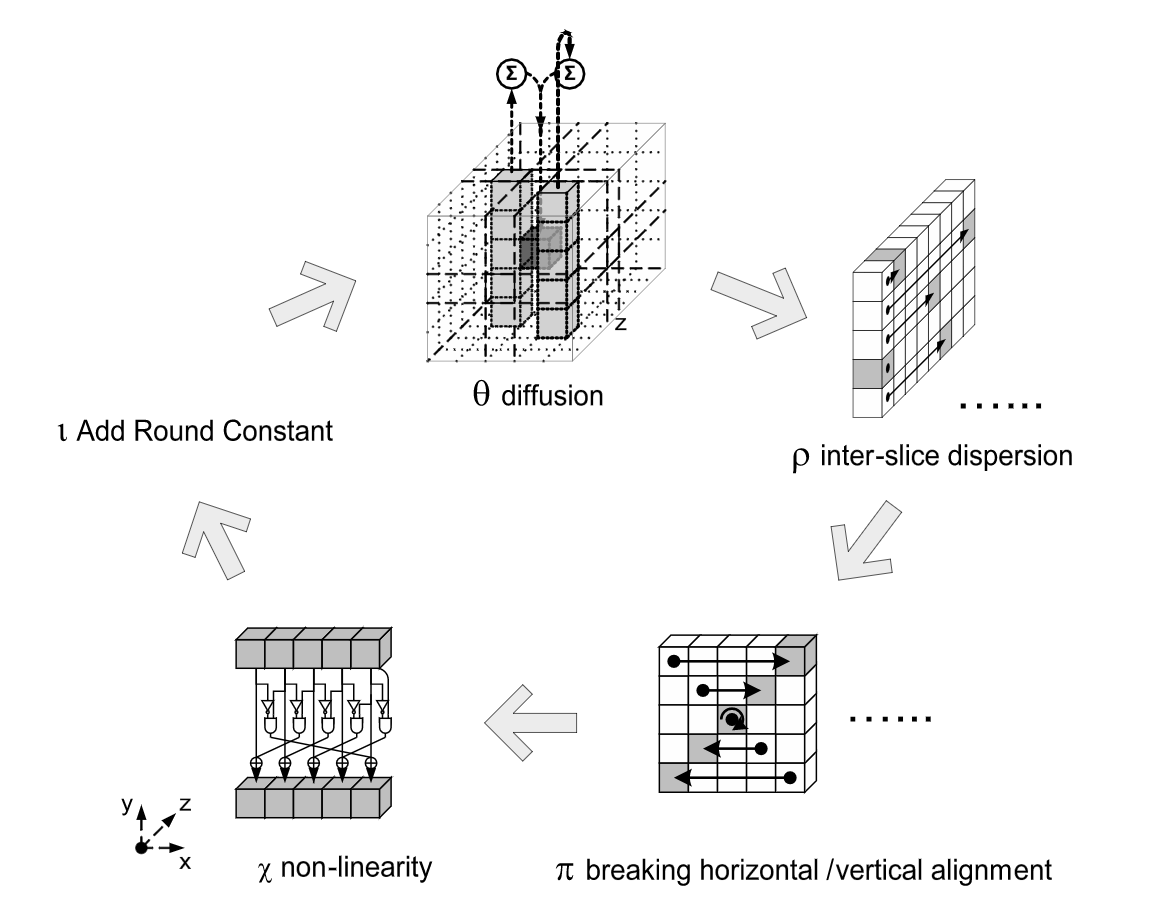
It turns out that a lot of operations are unchanged. Who would have known that XORs, ANDs and NOTs operations were not affected by the order of the bits! but only some rotations and bit positioning are. If you look at the reference implementations you will see that indeed, rotations have been reversed (compared to what the reference tells you to do).
And this is how a clever implementation trick made its way in a specification with no real explanation.
You're welcome!
"Why is Java a big pile of crap?" said the article. And after reading through the argumentation, I would move to the comment section and read a divergent point of view. Who was right? I wondered. Although everyone knows that Java is indeed a huge pile of crap, many other articles follow the same path of disputing one biased opinion that might be right, wrong, but really is both. I often mused on if I would come to write such a piece, and I think today is the day.
Keccak's (and/or SHA-3's) specification makes no sense.
Yup, it makes no sense, and I have a list of points you'll have to read through to understand how exactly.
By the way, if you didn't know, Keccak was the winner of the SHA-3 competition and blablabla...

Chocoweird indexing
First, let me introduce you to the internal state of Keccak.
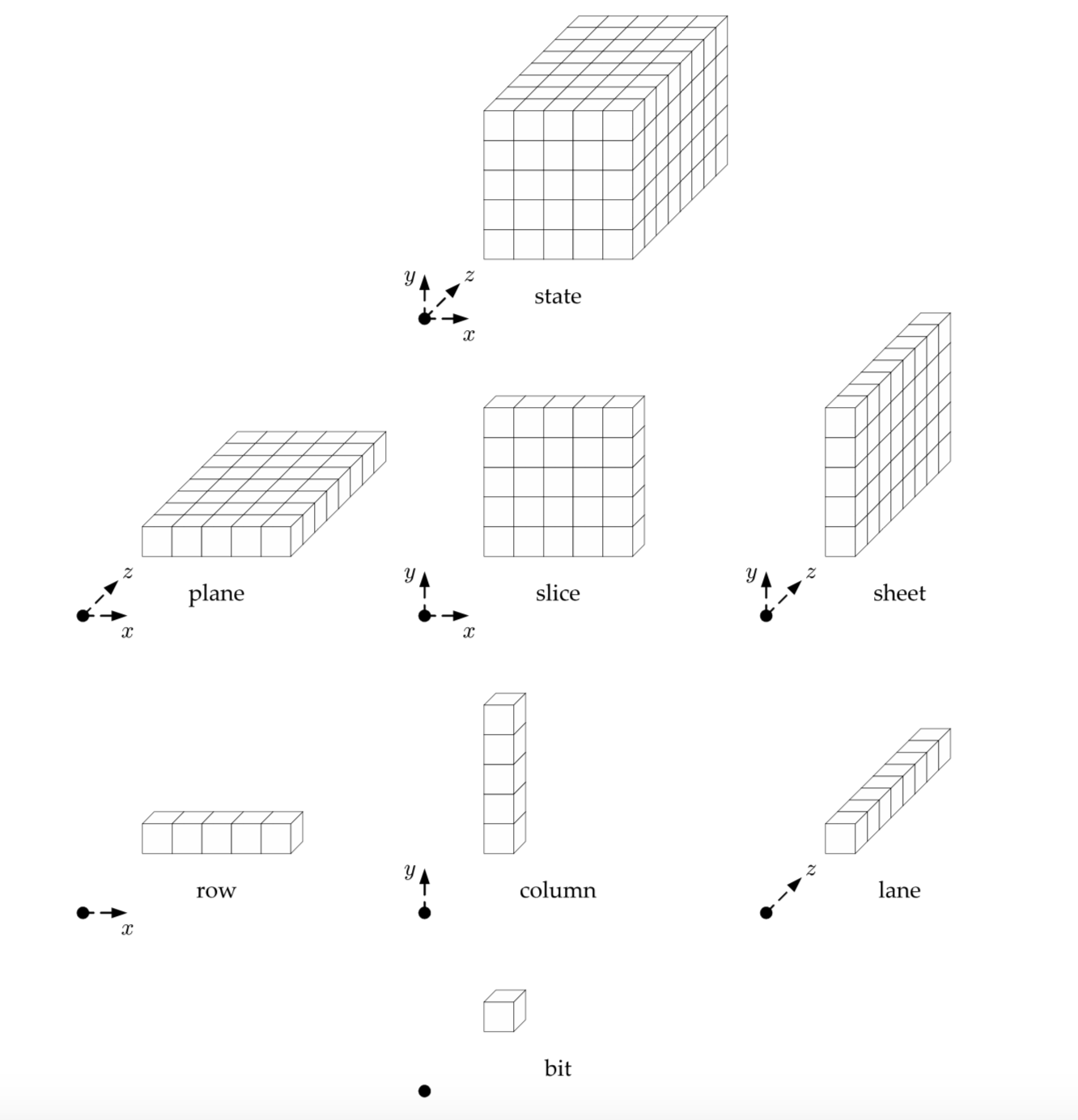
It is some sort of rectangular 3D object, and its different sub-objects have different names. Each little cube is a bit (a 1 or a 0). Cute.
I mean why not, AES was a square right? If we make it 3D we augment the security by one dimension. Sounds logical.
It gets weirder.
This is how the little cubes are indexed.

If you've started to reason on how you could translate that thing into a struct, stop. Don't overthink it. The x and y coordinates don't matter: all operations are done modulo the other columns or rows or you name it... you could have the indexes x = 0 and y = 0 anywhere really; it wouldn't change a thing. This picture doesn't even appear in Keccak's specification, only in FIPS 202. It is probably a joke from the NIST.
Multiple of bytes? Nopecheese
A uint8_t array
...you must have thought, still trying to have a head start, still shooting to figure out how you would stuck these bits in your code.
But wait. The NIST loves to think about bits though, not bytes. That's often surprising to people who end up implementing their specs with a byte length instead of a bit length and it led to what DJB calls a bit attack.
SHA-3 was no exception, NIST said to Keccak: you shall be able to handle the darkest desires of our stupid developers. You must account for ALL INPUTS. You must accept non-multiple of bytes.
Keccak provided. You can now hash 7-bit inputs with SHA-3.
The poor user is given enough rope with which to hang himself -- something a standard should not do.
—Rivest, 1992, commenting on the NIST/NSA “DSA” proposal
Bit indexing brainfudge
Let's talk about bit numbering, not byte order like big-endian and little-endian, no-no, bit numbering.
There are two ways to order bits in a byte (and we'll say here that a byte is an octet: it contains 8 bits):
- MSB first:
0x02 = 0000 0010, 0x01 = 0000 0001, ...
- LSB first:
0x40 = 0000 0010, 0x80 = 0000 0001, ...
Now what does this have to do with Keccak?
Keccak's bit numbering is LSB first, whereas NIST's one is MSB first (no kidding).
This means a re-mapping needs to take place when converting an input to the internal state of Keccak. This was all explained in the old specification of Keccak (see section 5).
Unfortunately these explanations disappeared in the latest version of the spec, and the NIST ended up writing up the conversion in an appendix (B.1) of their own specification FIPS 202.
Let me tell you: FIPS 202's explanation makes no sense. They end up mixing the theoretical internal state of Keccak with methods on how you can implement the re-mapping without having to inverse the bits of each bytes. It took me a while to figure it out and I am not the only one (most questions about Keccak/SHA-3 on internet end up being about their bit re-ordering).
Conclusion
Is SHA-3 Complicated? Some people would say no. But in reality there is no way to understand how to implement SHA-3 without looking at a reference implementation. NIST standards should seriously take a look at the process of TLS 1.3: no-one has been seen copying a reference implementation. Implementers are independently coding up what they understand of the draft specifications, and if cross-testing doesn't work it's either because they failed to understand something or because the specification needs some more love.
Having said that, Keccak is really cool and some of its applications look promising.
If you look at Go's implementation of GCM, in particular this, you can see that the counter is set to nonce||1:
if len(nonce) == gcmStandardNonceSize {
// Init counter to nonce||1
copy(counter[:], nonce)
counter[gcmBlockSize-1] = 1
}
It needs to be. Without it, the first block of keystream is the encryption of 0 if the nonce is 0 (which can happen if nonces are generated from a counter). The encryption of 0 is also... the authentication key!
Draft 19 has been published, this is a quick post talking about what has changed. This is mosty taken from the draft changelog as well as reading the commits since version 18. I've tried to keep up with what was important, but I ignored the many typos and small fixes, as well as what I think doesn't matter from draft to draft (exporters, cookies, ...)
Add pre-extract Derive-Secret stages to key schedule
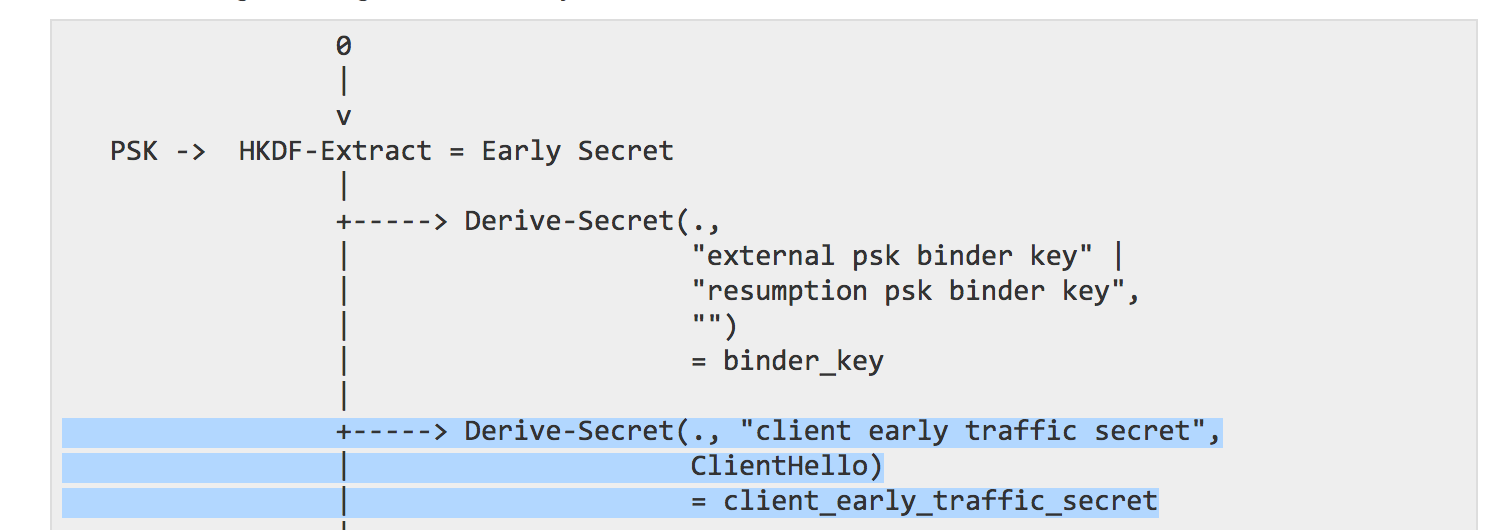
The key schedule part of TLS 1.3 is quite tricky. At different stage of the connection a "secret" is derived from different inputs, and used again to derive different keys and IVs (to encrypt/decrypt data). When a new phase begins (for example when handshake messages need to be encrypted, or when the handshake is over and application data messages need to be encrypted) a new secret is derived and new keys can be derived from that secret.

Here you can see (the top arrow) that the Handshake secret is derived using the HKDF-Extract() function with the previous secret and the Diffie-Hellman key exchange output. Keys and IVs for both the Client and the Server are then derived from that secret (arrows pointing to the right). Next (all the way down) the Master secret is derived from that secret and the traffic keys, protecting the application data, can be derived from it.
Notice the Derive-Secret() function being used before re-using HKDF-Extract() again. This is new in Draft 19. This Derive-Secret() is the HKDF-Expand() function. If you know HKDF you know that it acts like a lot of different KDFs: in two steps. It extract the entropy given, and it then expands it. This was used to derive keys (you can see it with the arrows pointing on the right), but not to derive secrets. It is now fixed and that's why you can see it being used to derive the new Master secret. One of the positive outcome of this change is that HKDF can now more easily be replaced with another KDF.
Consolidate "ticket_early_data_info" and "early_data" into a single extension
This was an easy one.
The early_data extension was an empty extension used by a Client in the ClientHello message when it wanted to send 0-RTT data; and by a Server in the EncryptedExtensions message to confirm acceptance of the 0-RTT data.
The ticket_early_data_info was an extension that a Server would send in a ticket (for session resumption) to advertise to the Client that 0-RTT was available. It only contained one field: the maximum size of the data that should be sent as 0-RTT data.
Both are now merged under early_data which can be used for both purposes. Less extensions :) it's a good thing.
struct {} Empty;
struct {
select (Handshake.msg_type) {
case new_session_ticket: uint32 max_early_data_size;
case client_hello: Empty;
case encrypted_extensions: Empty;
};
} EarlyDataIndication;
Change end_of_early_data to be a handshake message
To use the 0-RTT feature of TLS 1.3, a client can start sending 0-RTT data right after a ClientHello message. It is encrypted with a set of keys and IVs derived from the PSK and the ClientHello. The PSK will typically be some resumption secret from a previous connection, but it can also be a pre-shared key (yeah, you can't do 0-RTT if you don't already share some secret with the server). The image below is taken from the key schedule section.
When a client is done sending this 0-RTT data, it can then finish the handshake by sending the remaining handshake messages (Certificate, CertificateVerify, Finished). These remaining handshake messages are encrypted (new in TLS 1.3) under a handshake key. To warn the server that the client is done sending 0-RTT data and that it is now using the handshake key to encrypt messages, it would previously (draft 18) send a end_of_early_data alert. This alert is now a handshake message! Which is what it should have been all along :)
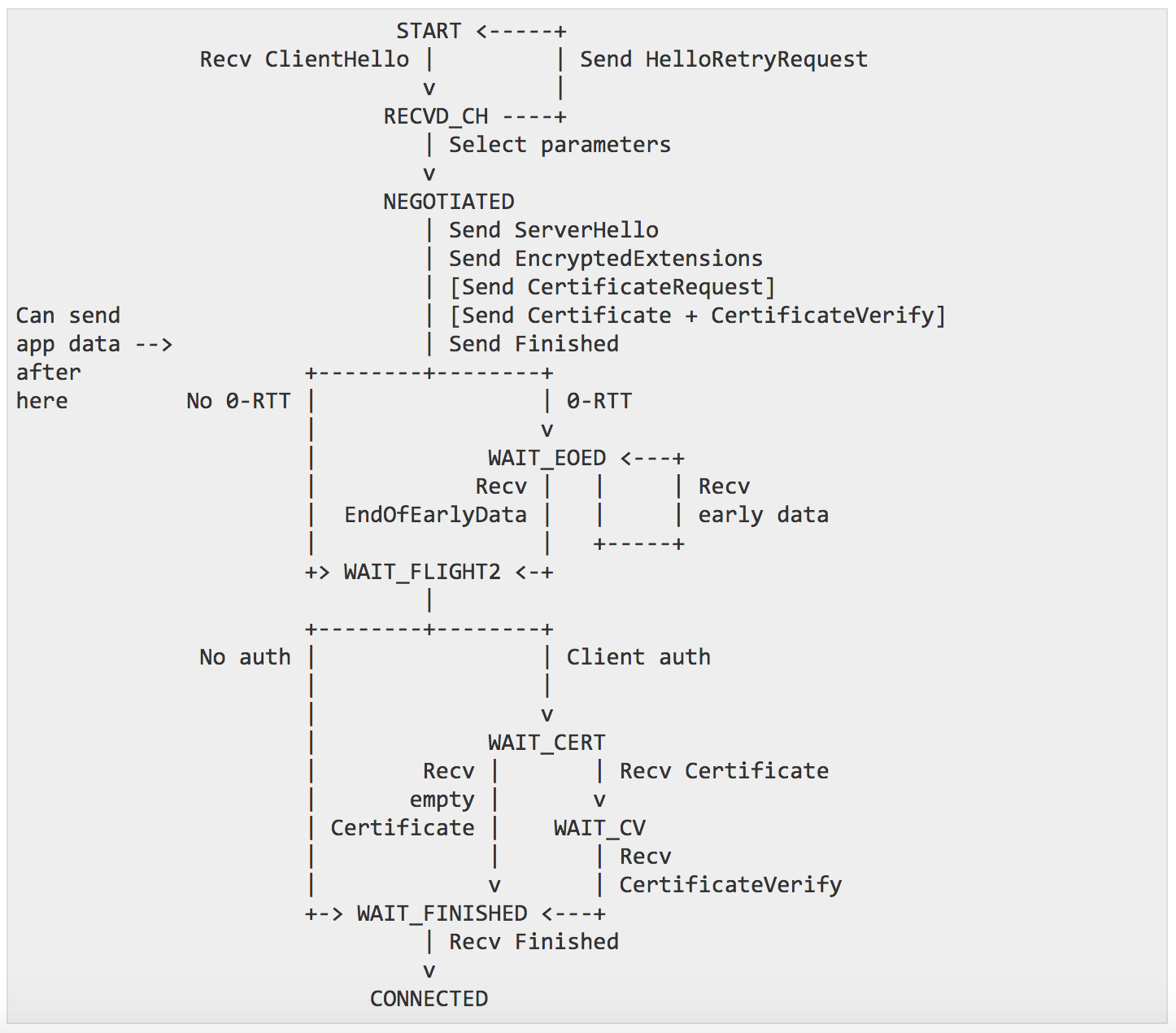
Add state machine diagram
New diagrams representing the different client/server state machines made their way in draft 19! TLS 1.3 will officially be the first TLS RFC to provide so many diagrams. And they're beautiful too, what an artistic performance.
server workflow
client workflow
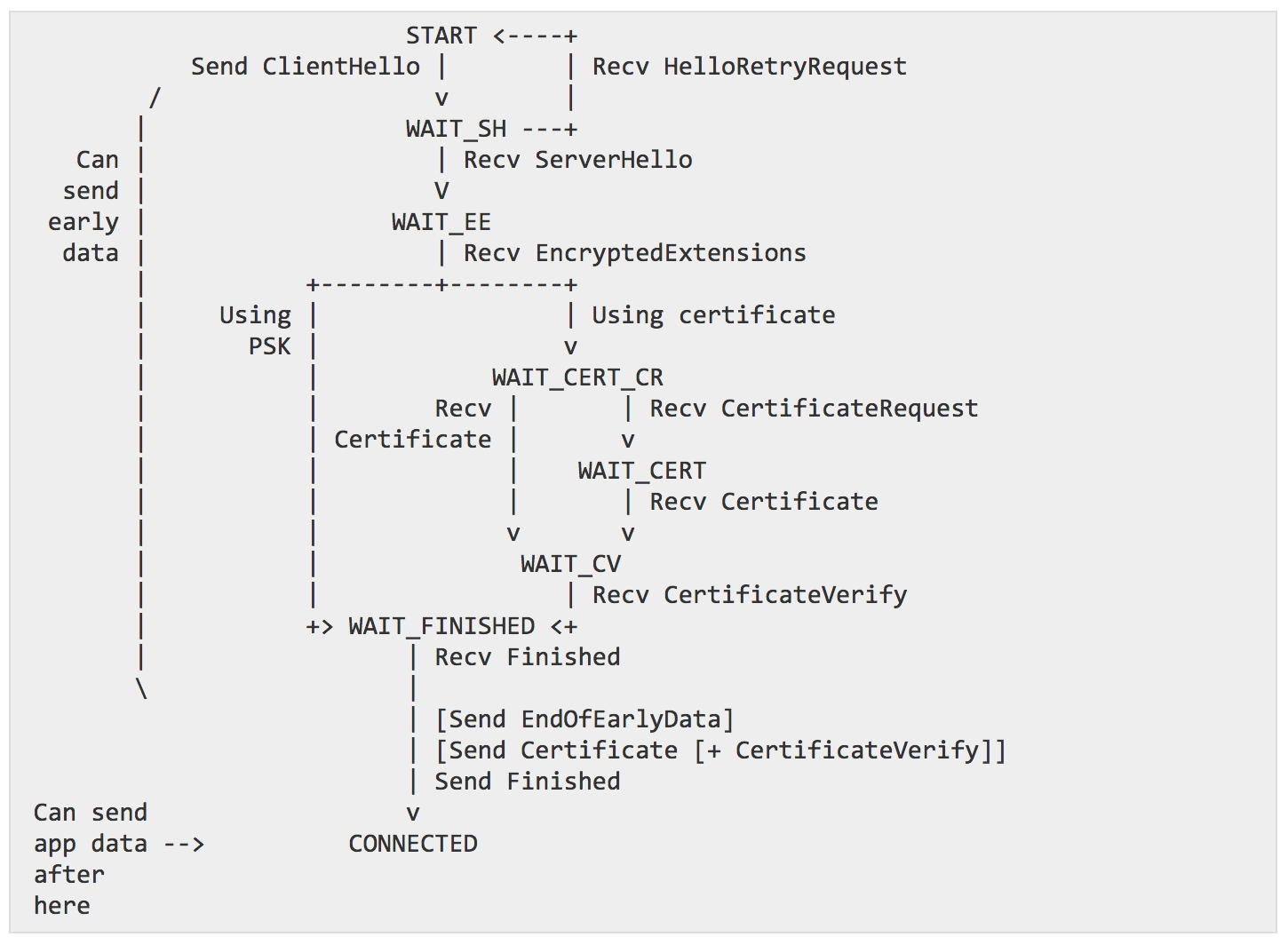
That's about it
I haven't spotted anything else major. Some SHOULDs became MUSTs, and some MUSTs became SHOULDs. At the moment, I believe the PSK and 0-RTT flows are quite hard to understand. Perhaps a diagram representing the flow of PSK from a server or client would be nice to have. Eric Rescorla has pointed out a few questions that should be answered to move the draft forward. I've seen so many issues, PR and commits these last weeks that I'm wondering when TLS 1.3 will be considered ready... but it's moving forward :)
After Real World Crypto, like every year, NCC Con follows next.
NCC Con is the NCC Group conference, a conference for its employees only, with a bunch of talks and drinks. I gave a talk on TLS 1.3 that I hope I can translate to a blog post at some point.
This year I also designed the NCC Group's Mascot! Which was given away as a T-shirt and a sticker to all the employees at the conference. It was a pretty surreal moment for me to see people around me, at the conference and in the casinos (it was in Vegas) wearing that shirt I designed :D


And here is a wallpaper with my original submission
Some pictures with people wearing it :)

(The notes for day 2 are here.)
The first talk on Quantum Computers was really interesting, but unfortunately mostly went over my head. Although I'm glad we had a pro who could come and talk to us on the subject. The take away I took from it was to go read the SMBC comics on the same subject.
After that there was a talk about TPMs and DAA for Direct Anonymous Attestation. I should probably read the wikipedia page because I have no idea what that was about.
Helena Handschuh from Cryptography Research talked about DPA Resistance for Real People. There are many techniques we use as DPA countermeasures but it seems like we still don't have the secret sauce to completely prevent that kind of issues, so what we really end up doing is rotating the keys every 3 encryption/decryption operations or so... That's what they do at Rambus, and at least what I've heard other people doing when I was at CHES this year. Mike Hamburg describes the way they rotate keys in his STROBE project a bit. Handschuh also talked about the two ways to certify a DPA-resistant product. There are evaluations like Common Criteria, which is usually the normal route, but now there is also validation. Don't ask me about that.
David Cash then entered the stage and delivered what I believe was the best talk of the conference. He started with a great explanation of ORE vs OPE. OPE (Order Preserving Encryption) allows you to encrypt data in a way that ciphertexts conserve the same lexicographic order, ORE (Order Revealing Encryption) does not, but some function over the ciphertexts end up revealing the order of the plaintexts. So they're kind of the same in the end and the distiction doesn't seem to really matter for his attacks. What matters is the distinction between Ideal ORE and normal ORE (and the obviously, the latter is what is used in the real world).
Ideal ORE only reveals the order while the ORE schemes we use also reveal other things, for example the MSDB (most significant different bits) which is the position of the first non-similar bit between two plaintexts.
Previous research focused on attacking a single column of encrypted data while their new research attacks columns of correlated data. David gives the example of coordinates and shows several illustrations of his attack revealing an encrypted image of the linux penguin, encrypted locations on a map or his go-about saved and encrypted by a GPS. Just by looking at the order of coordinates everything can be visually somewhat restored.
Just by analyzing the MSDB property, a bunch of bits from the plaintexts can be restored as well. It seemed like very bad news for the ORE schemes analyzed.
Finally, two points that seemed really important in this race for the perfect ORE scheme is that first: the security proofs of these constructions are considering any database data as uniformly random, whereas we know that we rarely need to store completely random data :) Especially columns are often correlated with one another.
Second, even an (hypothetical) ideal ORE was vulnerable to their research and to previous research (he gave the example of encrypting the whole domain in which case the order would just reveal the plaintexts).
This is a pretty bad stab at ORE scheme in general, showing that it is intuitively limited.
Paul Grubbs followed with an explanation of BoPETS, a term that I believe he recently coined, meaning "Building on Property revealing EncrypTion". He gave a good list of products that I replicated below in a table.
| Order Preserving Encryption |
SAP, Cipherbase, skyhigh, CipherCloud, CryptDB |
| Searchable Encryption |
Shadowcrypt, Mylar, kryptonostik, gitzero, ZeroDB, CryptDB |
| Deterministic Encryption |
Perspecsys, skyhigh, CipherCloud, CryptDB |
They looked at Mylar and saw if they could break it from 3 different attacker setups: a snapshot setup (smash and grab attack), passive (attacker got in, and is now observing what is happening), active (attacker can do pretty much anything I believe).
Mylar uses some encrypted data blob/structure in addition to a "principal graph" containing some metadata, ACL, etc... related to the encrypted data. Grubbs showed how he could recover most of the plaintexts from all the different setups.
Tal Malkin interjected that these attacks would probably not apply to some different PPE systems like IBM OXT. Grubbs said it did not matter. Who's right, I don't know.
As for the active attacker problem, there seem to exist no intuitive solution there. If the attacker can do anything, you're probably screwed.
Raluca Ada Popa (Mylar) followed Grubbs by talking about her product Mylar and rejected all of Grubbs claims, saying that there were out of the scope of Mylar OR were attacking mis-use of the product. IIRC the same thing happened when CryptDB was "broken", CryptDB released a paper arguing that these were false claims.
After Mylar, Popa intend to release two new products with better security: Verena and Opaque.
David Mcgrew mentionned Joy and gave a long talk about detecting PRNG failures. Basically look for public values affected by a PRNG like signatures or the server/client random in TLS.
And that was it. See you next year.
If you have anything to say about my notes, the talks, or other people's notes, please do so in the comments :)
There was a HACS workshop right after RWC, and Tim Taubert wrote some notes on it here.


{kind=link}