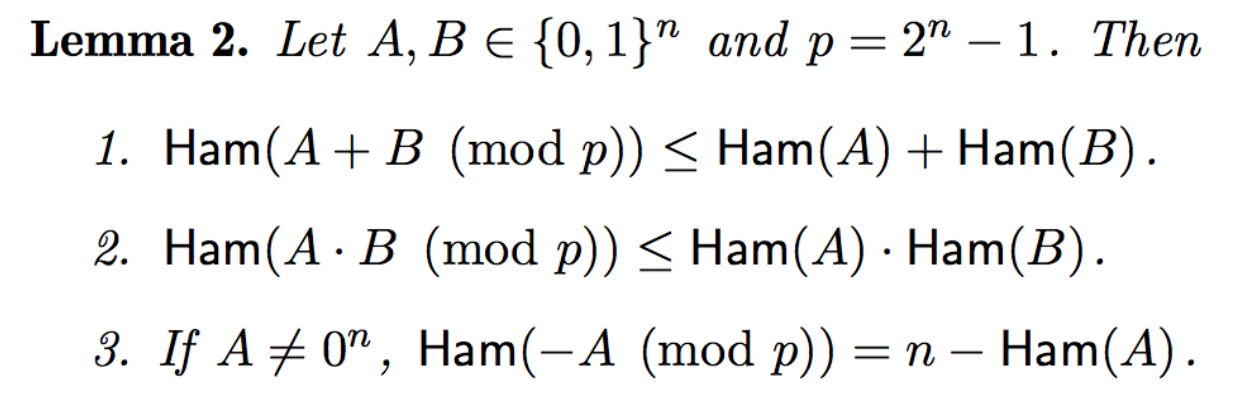Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
The Keccak Code Package repository contains all of the Keccak team's constructions, including for example SHA-3, SHAKE, cSHAKE, ParallelHash, TupleHash, KMAC, Keyak, Ketje and KangarooTwelve. ParallelHash and KangarooTwelve are two hash functions based on the same basis of SHA-3, but that can be sped up with parallelization. This makes these two hash functions really interesting, especially when hashing big files.
MMX, SSE, SSE2, AVX, AVX2, AVX-512
To support parallelization, a common way is to use SIMD instructions, a set of instructions generally available on any modern 64-bit architecture that allows computation on large blocks of data (64, 128, 256 or 512 bits). Using them to operate in blocks of data is what we often call vector/array programming, the compiler will sometimes optimize your code by automatically using these large SIMD registers.
SIMD instructions have been here since the 70s, and have become really common. This is one of the reason why image, sound, video and games all work so well nowadays. Generally, if you're on a 64-bit architecture your CPU will support SIMD instructions.
There are several versions of these instructions. On Intel's side these are called MMX, SSE and AVX instructions. AMD has SSE and AVX instructions as well. On ARM these are called NEON instructions.
MMX allows you to operate on 64-bit registers at once (called MM registers). SSE, SSE2, SSE3 and SSE4 all allow you to use 128-bit registers (XMM registers). AVX and AVX2 introduced 256-bit registers (YMM registers) and the more recent AVX-512 supports 512-bit registers (ZMM registers).
Looking at the list of architectures supported by the Keccak Code Package I see Haswell, which is of the same family and supports AVX2 as well. Compiling with it, I can run my KangarooTwelve code with AVX2 support, which parallelizes four runs of the Keccak permutation at the same time using these 256-bit registers!
In more details, the Keccak permutation goes through several rounds (12 for KangarooTwelve, 24 for ParallelHash) that need to serially operate on a succession of 64-bit lanes. AVX (no need for AVX2) 256-bit's registers allow four 64-bit lanes to be operated on at the same time. That's effectively four Keccak permutations running in parallel.
Intrisic Instructions
Intrisic functions are functions you can use directly in code, and that are later recognized and handled by the compiler.
In C, if you're compiling with GCC on an Intel/AMD architecture you can start using intrisic functions for SIMD by including x86intrin.h. Or you can use this script to include the correct file for different combination of compilers and architectures:
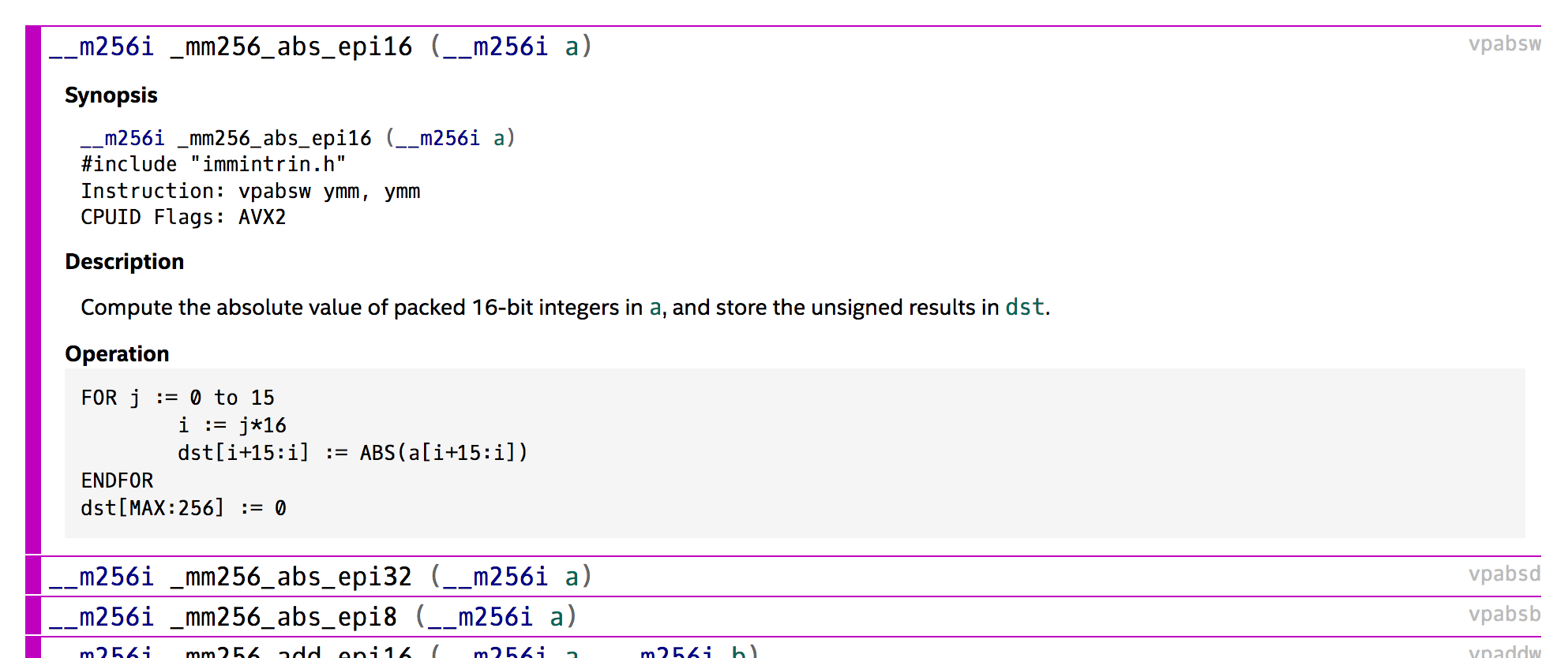
If we look at the reference implementation of KangarooTwelve in C we can see how they decided to use the AVX2 instructions. They first define a __m256i variable which will hold 4 lanes at the same time.
#define ANDnu256(a, b) _mm256_andnot_si256(a, b)
#define CONST256(a) _mm256_load_si256((const V256 *)&(a))
#define CONST256_64(a) (V256)_mm256_broadcast_sd((const double*)(&a))
#define LOAD256(a) _mm256_load_si256((const V256 *)&(a))
#define LOAD256u(a) _mm256_loadu_si256((const V256 *)&(a))
#define LOAD4_64(a, b, c, d) _mm256_set_epi64x((UINT64)(a), (UINT64)(b), (UINT64)(c), (UINT64)(d))
#define ROL64in256(d, a, o) d = _mm256_or_si256(_mm256_slli_epi64(a, o), _mm256_srli_epi64(a, 64-(o)))
#define ROL64in256_8(d, a) d = _mm256_shuffle_epi8(a, CONST256(rho8))
#define ROL64in256_56(d, a) d = _mm256_shuffle_epi8(a, CONST256(rho56))
#define STORE256(a, b) _mm256_store_si256((V256 *)&(a), b)
#define STORE256u(a, b) _mm256_storeu_si256((V256 *)&(a), b)
#define STORE2_128(ah, al, v) _mm256_storeu2_m128d((V128*)&(ah), (V128*)&(al), v)
#define XOR256(a, b) _mm256_xor_si256(a, b)
#define XOReq256(a, b) a = _mm256_xor_si256(a, b)
#define UNPACKL( a, b ) _mm256_unpacklo_epi64((a), (b))
#define UNPACKH( a, b ) _mm256_unpackhi_epi64((a), (b))
#define PERM128( a, b, c ) (V256)_mm256_permute2f128_ps((__m256)(a), (__m256)(b), c)
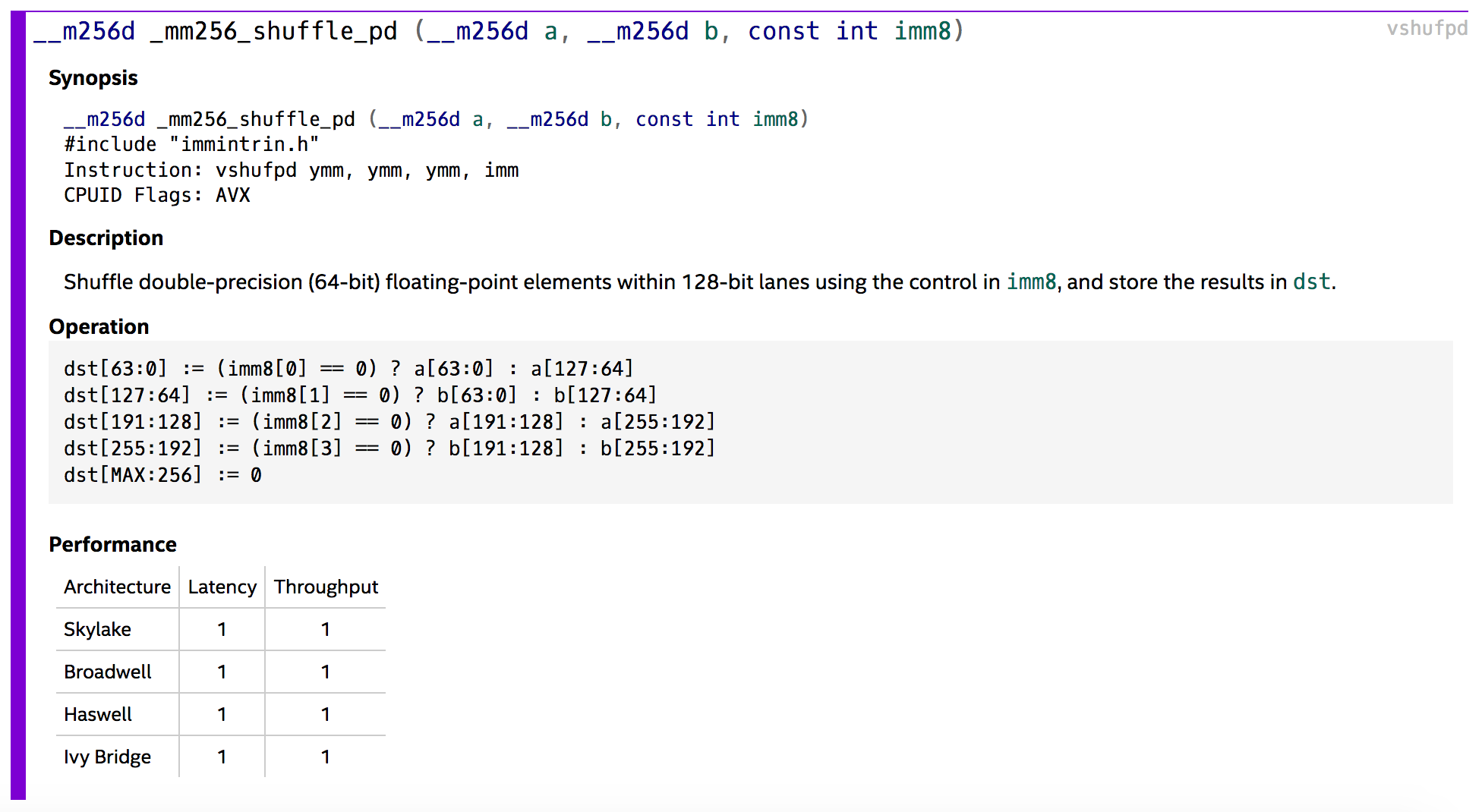
#define SHUFFLE64( a, b, c ) (V256)_mm256_shuffle_pd((__m256d)(a), (__m256d)(b), c)
And if you're wondering how each of these _mm256 function is used, you can check the same Intel documentation
a lot of keywords here are really interesting. But first, what is a Mersenne prime?
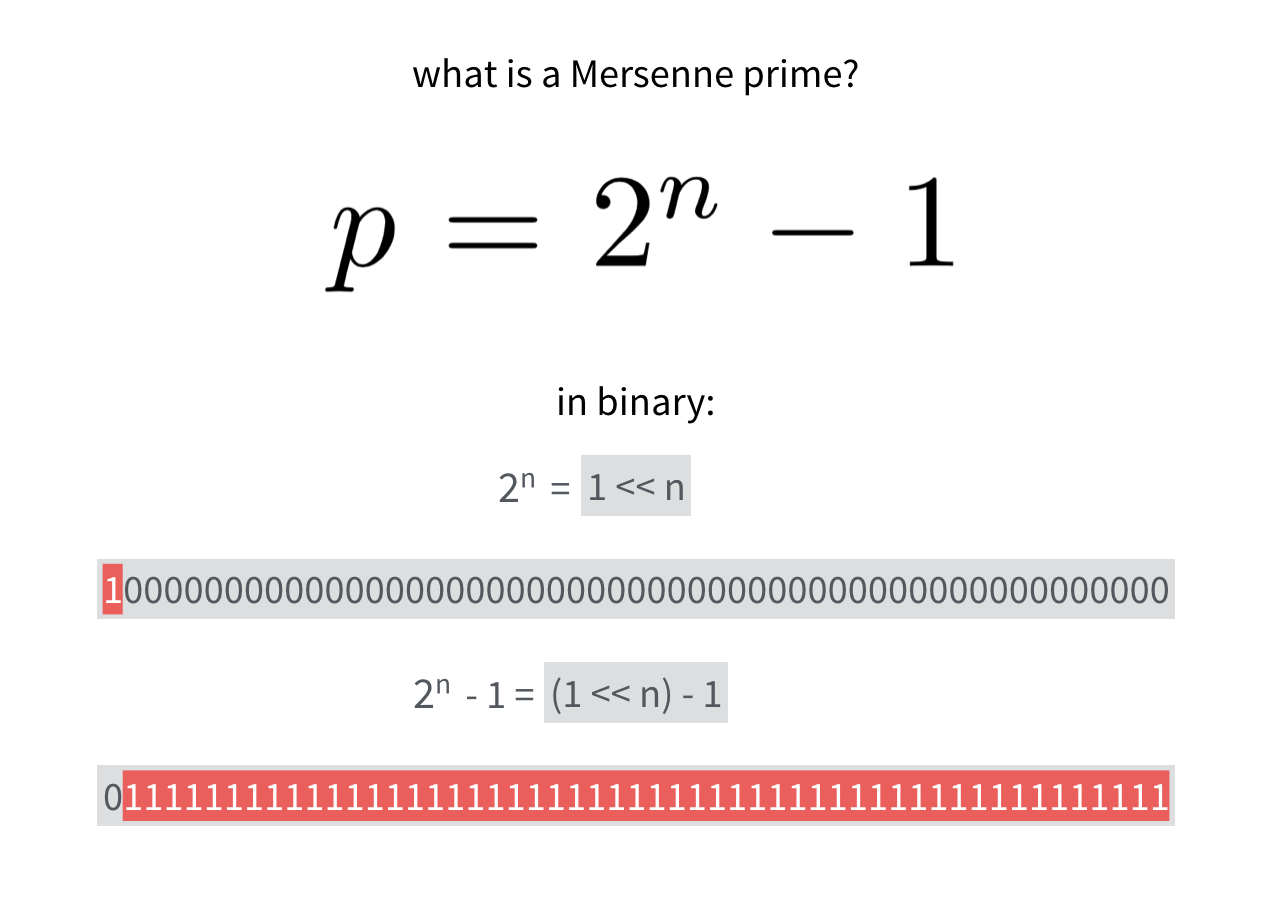
A mersenne prime is simply a prime \(p\) such that \(p=2^n - 1\). The nice thing about that, is that the programming way of writing such a number is
(1 << n) - 1
which is a long series of 1s.
A number modulo this prime can be any bitstring of the mersenne prime's length.
OK we know what's a Mersenne prime. How do we build our new public key cryptosystem now?
Let's start with a private key: (secret, privkey), two bitstrings of low hamming weight. Meaning that they do not have a lot of bits set to 1.
Now something very intuitive happens: the inverse of such a bitstring will probably have a high hamming weight, which let us believe that \(secret \cdot privkey^{-1} \pmod{p}\) looks random. This will be our public key.
Now that we have a private key and a public key. How do we encrypt ?
The paper starts with a very simple scheme on how to encrypt a bit \(b\).
\[ciphertext = (-1)^b \cdot ( A \cdot pubkey + B ) \pmod{p} \]
with \(A\) and \(B\) two public numbers that have low hamming weights as well.
We can see intuitively that the ciphertext will have a high hamming weight (and thus might look random).
If you are not convinced, all of this is based on actual proofs that such operations between low and high hamming weight bitstrings will yield other low or high hamming weight bitstrings. All of this really work because we are modulo a \(1111\cdots\) kind of number. The following lemmas taken from the paper are proven in section 2.1.
How do you decrypt such an encrypted bit?
This is how:
\[ciphertext \cdot privkey \pmod{p}\]
This will yield either a low hamming weight number → the original bit \(b\) was a \(0\),
or a high hamming weight number → the original bit \(b\) was a \(1\).
You can convince yourself by following the equation:
And again, intuitively you can see that everything is low hamming weight except for the value of \((-1)^b\).
This scheme doesn't look CCA secure nor practical. The paper goes on with an explanation of a more involved cryptosystem in section 6.
EDIT: there is already a reduction of the security estimates published on eprint.
Recently T. Duong, D. Bleichenbacher, Q. Nguyen and B. Przydatek released a crypto library intitled Tink. At its center lied an implementation of AES-GCM somehow different from the rest: it did not take a nonce as one of its input.
A few days ago, at the Crypto SummerSchool in Croatia, Nik Kinkel told me that he would generally recommend against letting developers tweak the nonce value, based on how AES-GCM tended to be heavily mis-used in the wild. For a recap, if a nonce is used twice to encrypt two different messages AES-GCM will leak the authentication key.
I think it's a fair improvement of AES-GCM to remove the nonce argument. By doing so, nonces have to be randomly generated. Now the new danger is that the same nonce is randomly generated twice for the same key. The birthday bound tells us that after \(2^{n/2}\) messages, \(n\) being the bit-size of a nonce, you have great odds of generating a previous nonce.
The optimal rekey point has been studied by Abdalla and Bellare and can computed with the cubic root of the nonce space. If more nonces are generated after that, chances of a nonce collision are too high. For AES-GCM this means that after \(2^{92/3} = 1704458900\) different messages, the key should be rotated.
This is of course assuming that you use 92-bit nonces with 32-bit counters. Some protocol and implementations will actually fix the first 32 bits of these 92-bit nonces reducing the birthday bound even further.
Isn't that a bit low?
Yes it kinda is. An interesting construction by Dan J. Bernstein called XSalsa20 (and that can be extended to XChacha20) allow us to use nonces of 192 bits. This would mean that you should be able to use the same key for up to \(2^{192/3} = 18446744073709551616\) messages. Which is already twice more that what a BIG INT can store in a database
It seems like Sponge-based AEADs should benefit from large nonces as well since their rate can store even more bits. This might be a turning point for these constructions in the last round of the CAESAR competition. There are currently 4 of these: Ascon, Ketje, Keyak and NORX.
With that in mind, is nonce mis-use resistance now fixed?
EDIT: Here is a list of recent papers on the subject:
It is heavily based on the official Go's x/crypto/sha3 library. But because of minor implementation details the relevant files have been copied and modified there so you do not need Go's SHA-3 implementation to run this package. Hopefully one day Go's SHA-3 library will be more flexible to allow other keccak construction to rely on it.
I have tested this implementation with different test vectors and it works fine. Note that it has not received proper peer review. If you look at the code and find issues (or not) please let me know!
This implementation does not yet make use of SIMD to parallelize the implementation. But we can already see improvements due to the smaller number of rounds:
100 bytes
1000 bytes
10,000 bytes
K12
761 ns/op
1875 ns/op
15399 ns/op
SHA3
854 ns/op
3962 ns/op
34293 ns/op
SHAKE128
668 ns/op
2853 ns/op
29661 ns/op
This was done with a very simple bench script on my 2 year-old macbook pro.
Adam Langley from Google wrote a blogpost yesterday called Maybe Skip SHA-3. It started some discussions both on HN and on r/crypto
Speed drives adoption, Daniel J. Bernstein (djb) probably understand this more than anyone else. And this is what led Adam Langley to decide to either stay on SHA-2 or move to BLAKE2. Is that a good advice? Should we all follow his steps?
I think it is important to remember that Google, as well as the other big players, have an agenda for speed. I'm not saying that they do not care about security, it would be stupid for me to say that, especially seeing all of the improvements we've had in the field thanks to them in the last few years (Project Zero, Android, Chrome, Wycheproof, Tink, BoringSSL, email encryption, Key Transparency, Certificate Transparency, ...)
What I'm saying is that although they care deeply about security, they are also looking for compromises to gain speed. This can be seen with the push for 0-RTT in TLS, but I believe we're seeing it here as well with a push for either KangarooTwelve (K12) or BLAKE2 instead of SHA-3/SHAKE and BLAKE (which are more secure versions of K12 and BLAKE2).
Adam Langley even went as far as to recommend folks to stay on SHA-2.
But how can we keep advising SHA-2 when we know it can be badly misused? Yes I'm talking about length extension attacks. These attacks that prevent you from using SHA-2(key|data) to create a Message Authentication Code (MAC).
We recently cared so much about misuses of AES-GCM (documented misuses!) that Adam Langley's previous blog post to the SHA-3 one is about AES-GCM-SIV.
We cared so much about simple APIs, that recently Tink simply removed the nonce argument from AES-GCM's API.
If we cared so much about documented misusage of crypto APIs, how can we not care about this undocumented misuse of SHA-2? Intuitively, if SHA-2 was to behave like a random oracle there would be no problem at all with the SHA-2(key|data) construction. Actually, none of the more secure hash functions like Blake and SHA-3 have this problem.
If we cared so much about simple APIs, why would we advise people to "fix" SHA-2 by truncating 256 bits of SHA-512's output (SHA-512/256)?
The reality is that you should use SHA-3. I'm making this as a broad recommendation for people who do not know much about cryptography. You can't go wrong with the NIST's standard.
Now let's see how we can dilute a good advice.
If you care about speed you should use SHAKE or BLAKE.
If you really care about speed you should use KangarooTwelve or BLAKE2.
If you really really care about speed you should use SHA-512/256. (edit: people are pointing to me that Blake2 is also faster than that)
If you really really really care about speed you should use CRC32 (don't, it's a joke).
How big of a security compromise are you willing to make? We know the big players have decided, but have they decided for you?
Is SHA-3 that slow?
Where is a hash function usually used? One major use is in signing messages. You hash the message before signing it because you can't sign something that is too big.
Here is a number taken from djb's benchmarks on how many cycles it takes to sign with ed25519: 187746
Here is a number taken from djb's benchmarks on how many cycles it takes to hash a byte with keccak512: 15
Spoiler Alert: you probably don't care about a few cycles.
Not to say there are no cases where this is relevant, but if you're doing a huge amount of hashing and you're hashing big messages, you should rather switch to a tree-hashing mode. KangarooTwelve, BLAKE2bp and BLAKE2sp all support that.
EDIT: The Keccak team just released a response as well.
Reading cryptographic implementations, you can quickly spot a lot of weirdness and oddities. Unfortunately, this is because very few cryptographic implementations aim for readability (hence the existence of readable implementations). But on the other hand, there are a lot of cool techniques in there which are interesting to learn about.
Bit-slicing is one I've never really talked about, so here is a self-explanatory tweet quoting Thomas Pornin:
But I'm here to talk about loop unrolling. Here's what wikipedia has to say about it:
Loop unrolling, also known as loop unwinding, is a loop transformation technique that attempts to optimize a program's execution speed at the expense of its binary size, which is an approach known as the space-time tradeoff.
Here is an implementation of MD5 in go. You can see that the gen.go file is generating a different md5block.go file which will be the unrolled code. Well yeah, sometimes it's just easier than doing it by hand :]
It hasn't been thoroughly tested, and its main goal was to help me understand the specification of Strobe while kicking around ideas to challenge the spec.
I hope that this implementation can help someone else understand the paper/spec better. The plan is to have a usable implementation by the time Strobe's specification is more stable (not that it isn't, its version is actually 1.0.2 at the moment).
Following is a list of divergence from the current specification:
Operate
The main Operate public function that allows you to interact with STROBE as a developer has a different API. In pseudo code:
Operate(meta bool, operation string, data []byte, length int, more bool) → (data []byte)
I've also written high level functions to call the different known operations like KEY, PRF, send_ENC, etc... One example:
// `meta` is appropriate for checking the integrity of framing data.
func (s *strobe) send_MAC(meta bool, output_length int) []byte {
return s.Operate(meta, "send_MAC", []byte{}, output_length, false)
}
The meta boolean variable is used to indicate if the operation is a META operation.
For any operation, there is a corresponding "meta" variant. The meta operation works exactly the same way as the ordinary operation. The two are distinguished only in an "M" bit that is hashed into the protocol transcript for the meta operations. This is used to prevent ambiguity in protocol transcripts. This specification describes uses for certain meta operations. The others are still legal, but their use is not recommended. The usage of the meta flag is described below in Section 6.3.
Each operation that has a relevant META variant, also contains explanation on it. For example the ENC section:
send_meta_ENC and recv_meta_ENC are used for encrypted framing data.
The operations are called via their strings equivalent instead of their flag value in byte. This could in theory be irrelevant if only the high level functions were made available to the developers.
A length argument is also available for operations like PRF, send_MAC and RATCHET that require a length. A non-zero length will create a zero buffer of the required length, which is not optimal for the RATCHET operation.
// does the operation requires a length?
if operation == "PRF" || operation == "send_MAC" || operation == "RATCHET" {
if length == 0 {
panic("A length should be set for this operation.")
}
// create an empty data slice of the relevant size
data = bytes.Repeat([]byte{0}, length)
} else {
if length != 0 {
panic("Output length must be zero except for PRF, send_MAC and RATCHET operations.")
}
// copy the data not to modify the original data
data = make([]byte, len(data_))
copy(data, data_)
}
Verbose
One of my grip with the Strobe's specification is that nothing is truly explained through words: the reader is expected to follow reference snippets of code written in Python. Everything has been optimized and it is quite hard to understand what is really happening (hence why I wrote this implementation in the first place). To remediate this, I wrote a clear path of what is happening for each operation. It is great for other readers who want to understand what is happening, but obviously not the optimal thing to do for an efficient implementation :)
It looks like a bunch of if and else if (Go does not have support for switch):
if operation == "AD" { // A
// nothing happens
} else if operation == "KEY" { // AC
cbefore = true
forceF = true
} else if operation == "PRF" { // IAC
cbefore = true
forceF = true
...
_Duplex
I have omited any function name starting with _ as Go has a different way of making functions available out of a package: make the first letter upper case.
The _duplex function was written after Golang's official SHA-3 implementation and is not optimal. The reason is that SHA-3 does not need to XOR anything in the state until after either the end of the rate (block size) or the end of the input has been reached. Because of this, Go's SHA-3 implementation waits for these to happen while STROBE often cannot: STROBE often needs the result right away. This led to a few oddities.
pos
I do not use the pos variable as it is easily obtainable from the buffered state. This is another (good) consequence of Go's decision on waiting before running the Keccak function. Some other implementations might want to keep track of it.
cur_flags
The specification states that cur_flags should be initialized to None. Which is annoying to program (see how I did it for I0). This is why I took the decision that a flag cannot be zero, and I'm initializing cur_flags to zero.
// operation is valid?
var flags flag
var ok bool
if flags, ok = OperationMap[operation]; !ok {
panic("not a valid operation")
}
R is always R
The specification states that the initialization should be done with R = R + 2. This is to have a match with cSHAKE's padding when using some STROBE instances like Strobe-128/1600 and Strobe-256/1600.
I like having constants and not modifying them. So I initialize with a smaller rate (block_size) and do not conform with cSHAKE's specification. Is it important? I think yes. It does not make sense to use cSHAKE's padding on Strobe-128/800, Strobe-256/800 and Strobe-128/400 as their rate is smaller than cSHAKE's defined rate in its padding.
EDIT: I ended up reverting this change. As I only implemented Strobe-256/1600, it is easy to conform to cSHAKE by just initializing with R + 2 which will not modify the constant R.