Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
WhatsApp just announced their integration of the Signal protocol (formerly known as the Axolotl protocol). An interesting aspect of it is the use of a TLS-like protocol called Noise Pipes. A protocol based on the Noise protocol framework, a one-man work led by Trevor Perrin with only a few implementations and a moderately long specificiations available here. I thought it would be interesting to understand how protocols are made from this framework, and to condense it in a 25 minutes video. Here it is.
The paper is available on eprint. titled A Systematic Analysis of the Juniper Dual EC Incident, it contains some background on Dual EC, IKE and a timeline of event that should read like a nice story. This is the paper you're going to read next week! So go print it now =)
CVE-2016-3959 also called the golang infinite loop just triggered a new version of the language Go. The cherry on the cake is that it was discovered by me!
A: Anything that uses the big.Exp function concurrently where the modulo parameter can be controlled by an attacker. For crypto this means mostly DSA and RSA which are used for example in TLS and SSH, as well as many other cryptographic applications, like recently in the Let's Encrypt client (hope they patched). ECDSA also use the big.Exp function but this elliptic curve version of DSA usually does not use custom curves so the attacker has usually no known way to make someone compute calculations over his curves parameters if they are non-standard.
A: Programming languages have int types that can usually hold integers up to 64bits (For example, in C this type is called uint64_t). But crypto needs numbers that are much bigger than that, up to 4000 bits sometimes. So big number libraries are the libraries used to play with numbers of such sizes without getting a headache =)
Q: What was the problem with big.Exp?
A: It was a pretty simple one, the lack of a zero check for the modulus made the calculation turn into an infinite loop. Interestingly the developers of Go did not patch the vulnerability by adding the zero check inside of big.Exp but did it inside of the implementations of DSA, RSA and ECDSA. This means that other cryptographic functions or non-cryptographic functions that employ this big.Exp function, concurrently, with the third parameter controlled by the user, might still be subject to DoS attacks.
If you have any other questions feel free to ask! The comment section is here for that ;)
I asked some questions to one of the co-author Adwait Nadkarni, I thought that it might be interesting to others:
But offline attacks can also be much harder, because they require either trying every single possible encryption key, or figuring out the user’s passcode and the device-specific key (the unique ID on Apple, and the hardware-bound key on newer versions of Android).
Q: I don't understand why you would have to guess that HBK, can't you just access it on the phone?
A: Thats a good question. To prevent the security from only being dependent on the user-supplied passcode, the HBK is supposed to be inaccessible from most software, similar to the iOS device-specific UID. That is, the HBK is supposed to be accessible only via the trusted executable environment (TEE), that is isolated on a different microprocessor. Untrusted software (even with compromise of the main kernel) is not supposed to be able to directly access the HBK.
That said, the reality is manufacturer-dependent. The TEE on different devices has been repeatedly compromised (Qualcomm TEE implementation compromised in 2014, HTC in 2015, etc.). Thus, there is threat of software compromise that may allow the attacker to retrieve or misuse the HBK.
Q: Is the secure enclave on the recent iPhones that TEE? Does that mean that most phones are vulnerable to offline brute force attacks? (since most phone don't have TEE (I'm not sure about that) and have a 4-6 digit PIN instead of an alphanumeric password)
A: The TEE is for Android; iOS uses secure enclave similarly. Most phones that do not use a device-specific key (i.e., old Android devices that run <Android 4.4, very old iOS devices) are vulnerable to offline brute-force attacks. Most phones (even old ones like our Nexus 4) do have TEE.
We built our own MDM application for our Android phone, and verified that the passcode can be reset without the user’s explicit consent; this also updated the phone’s encryption keys. We could then use the new passcode to unlock the phone from the lock screen and at boot time
Q: if you do that, the content on the phone would have to be decrypted with the real passcode and re-encrypted with your new passcode. I would imagine that the real passcode is not stored anywhere (there should be a password hash stored instead for verification only), so how does that technique works for the decryption phase? (don't know if the question is clear enough)
A: The phone is not directly encrypted with the passcode, but with a randomly generated DEK. The DEK is then encrypted with the KEK, which in turn is generated from the passcode and the HBK. Now, when the passcode is changed, the phone decrypts the DEK with the old KEK, then recreates the new KEK with the new passcode and HBK, and re-encrypts the DEK with the new KEK. Data is not touched when the passcode changes.
Q: so, specifically then, how does the phone uses the old KEK if it doesn't have the old passcode?
A: The old KEK is not created on the fly, but stored in the hardware-backed keystore (accessible only via the TEE). The TEE can retrieve it to decrypt the encrypted DEK.
Generally, operating system software is signed with a digital code that proves it is genuine, and which the phone requires before actually installing it.
this part made me wonder, what if we used lasers? Fault attacks are a big thing in the smart card industry, why is no one talking about it for cellphones? This prompted me to ask Frederico Menarini from Riscure:
Q: In iOS or Android if you want to update the phone, the update needs to be signed with Apple or Google or Samsung, etc... update key. But what you could do if you could mount a fault attack (lasers?) would be to target the point where the cellphone refuses the patch because of a false signature.
A: In principle, fault attacks are possible on phones – nothing prevents it and the scenario you described is valid. Laser attacks might be challenging though because certain chips use package-on-package or chip stacking, which means that you might not be able to directly affect the CPU using light.
In general attacking mobile phone chips will be complicated because they run at extremely high frequencies compared to smartcards (smartcards rarely run faster than 50 MHz) and because the feature size is much smaller (state of the art in smartcards is 90nm, which makes targeting the right area of the chip with a laser easier).
Here's a little demo of my work in progress research =)
The top right screen is the client, the bottom right screen is the server. I modified two numbers in some Socat file (hopefully it will be one number soon) and the backdoor is there. It's a public value and both the server and the client can generate their own certificates and use them in the TLS connection. For simplicity I don't do that, but just know that it would change nothing.
To get a Man-in-the-middle position I took the simplest approach I could think of: the screen on the left is a proxy, the client connect to the server through the proxy.
You will see that the proxy on the left will start parsing the server and the client packets as soon as it sees a TLS handshake. It then collects the server and the client Randoms, the server and the client DH public keys, and the DH parameters of the server to check if the backdoor is there. You will see a red message displaying that indeed, the backdoor is present.
For simplicity again (this is a proof of concept) I only use TLS 1.2 with AES128-CBC as the symmetric cipher and SHA-256 as the hash function used in the PRF/MAC/etc...
In a few seconds the premaster key, then the master key, then the MAC and encryption keys are computed and the traffic is then decrypted live.
Got my graphic tablet back, needed to do a small video to get back into it so I made something on Pollard's p-1 factorization algorithm:
You can find the records on factoring with p-1 on loria.fr, the biggest prime factor found was of 66 digits (~220bits) using B1=10^8 and B2=10^10. But people have been using bigger parameters like B1=10^10 and B2=10^15. It doesn't really make sense to continue using p-1 after that, and more efficient algorithms that still have a complexity tied to the size of the smallest factor exist. The Elliptic Curve Method (Or Lenzstra factorization method) is one of them, and is carrying the same ideas as p-1 in the elliptic curves.
In the video I also don't talk about B2. This is if you have a factorization of p-1 that is B1-powersmooth, except for a large single prime. You can just set a B2 which would be larger than this last factor and try every factor between B1 and B2. There are some optimizations that exist to do that faster instead of doing it naively but this is it.
I have this list of papers that is accumulating in a folder. After an idea of @gtank I decided to print the whole (~150 two-sided pages) and go to my local UPS store to bind it for ~8$.
I'm not posting the pdf I printed here, but I made it with pdfjoin --paper letterpaper --rotateoversize false *, could have used pdfbook to make it smaller but after printing a few pages I felt that it would be too small for my weary eyes (now I sound like an old bag).
here's the list of the papers I printed. They all seem like you can print them without going to jail.
Once we are done with the handshake, both parties are now holding the same set of keys. Right after the Server sends its ChangeCipherSpec message it starts encrypting. Right after the Client sends his own ChangeCipherSpec he starts encrypting his messages as well.
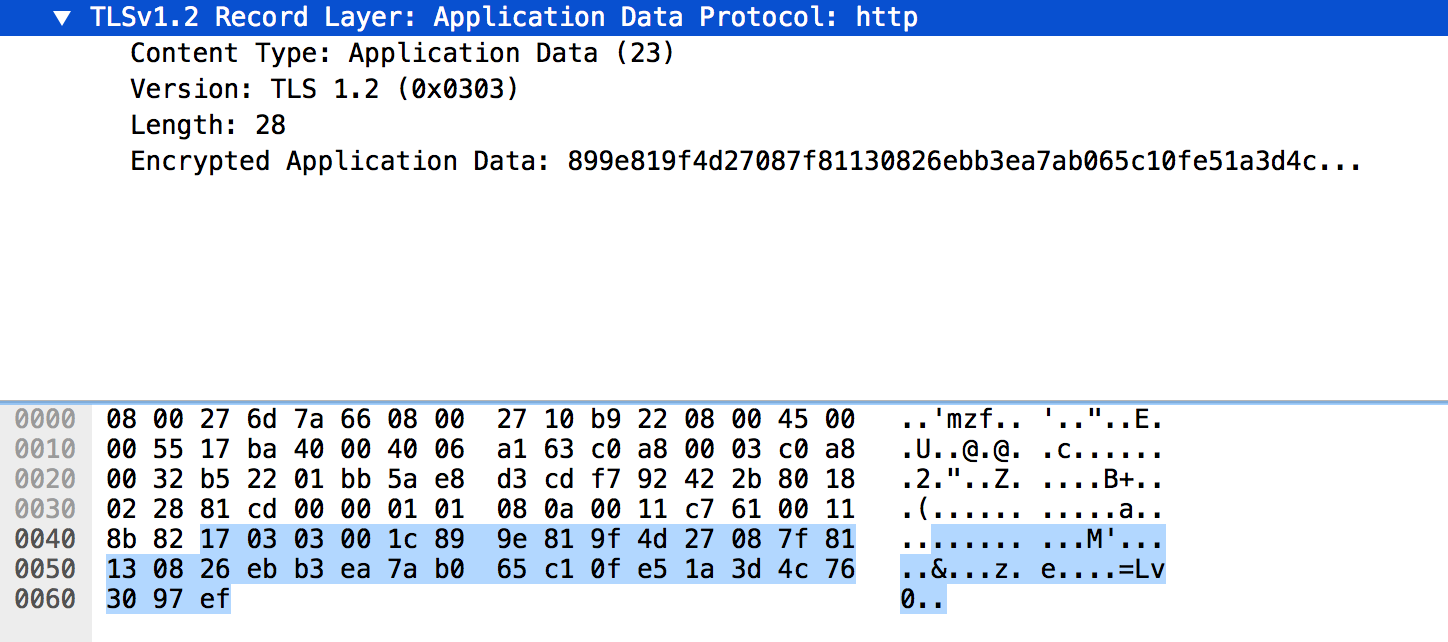
The encrypted records still start with the type of record, the TLS version and the length of the following bytes in clear. The rest is encrypted.
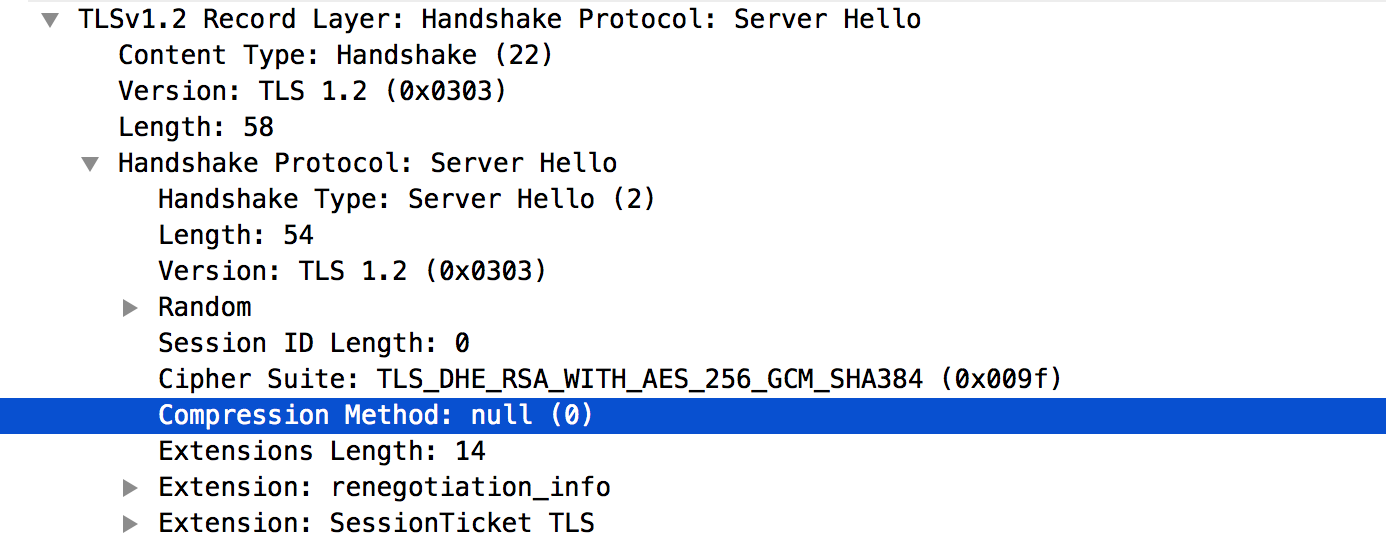
We won't talk about compression because there are a bunch of vulnerabilities that should make you think twice about using compression. So here it is, null! (more about that)
struct {
ContentType type;
ProtocolVersion version;
uint16 length;
select (SecurityParameters.cipher_type) {
case stream: GenericStreamCipher;
case block: GenericBlockCipher;
case aead: GenericAEADCipher;
} fragment;
} TLSCiphertext;
So as I said, we start with the type, the version and the length.
Right after the CipherSpecChange both parties will send an encrypted handshake message (a MAC of the whole transcript to authenticate the handshake), but most of the messages after will be encrypted Application data messages containing the real communications we want to protect.
0x17 is the byte for application data, then we have the TLS version, for TLS 1.2 it is 0x0303 (don't bother), then we have the length of the fragment which is described below for the AES-CBC case.
So in the case of AES-128, you would have an IV of 16 bytes followed by the encrypted data.
Yup, the MAC is not here because it is encrypted. TLS is a MAC-then-encrypt construction (...), you can do encrypt-then-MAC in practice but through an extension (cf. RFC 7366).
The rest is pretty straight forward, after decryption of the block-ciphered structure you remove the padding, check the MAC, use the content.