Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
If you don't know about QUIC, go read the excellent Cloudflare post about it. If you're lazy, just think about it as:
Google wanted to improve TCP (2.0™️)
but TCP can't really be changed
so they built it on top of UDP (which is just IP with ports, check the 2 page RFC for UDP if you don't believe me)
they made it with encryption by default
and they called it QUIC, because it's quick, you know
There is more to it, it makes HTTP blazing fast with multiplexed streams and all, but I'm only interested about the crypto here.
Google QUIC's (or gQUIC) default encryption was provided by a home-made crypto protocol called QUIC Crypto. The thing is documented in a 14-page doc file and is more or less up-to-date. It was at some point agreed that things needed to get standardized, and thus the process of making QUIC an RFC (or RFCs) began.
Unfortunately QUIC Crypto did not make it and the IETF decided to replace it with TLS 1.3 for diverse reasons.
Why "Unfortunately" do you ask?
Well, as Adam Langley puts it in some of his slides. The protocol was dead simple:
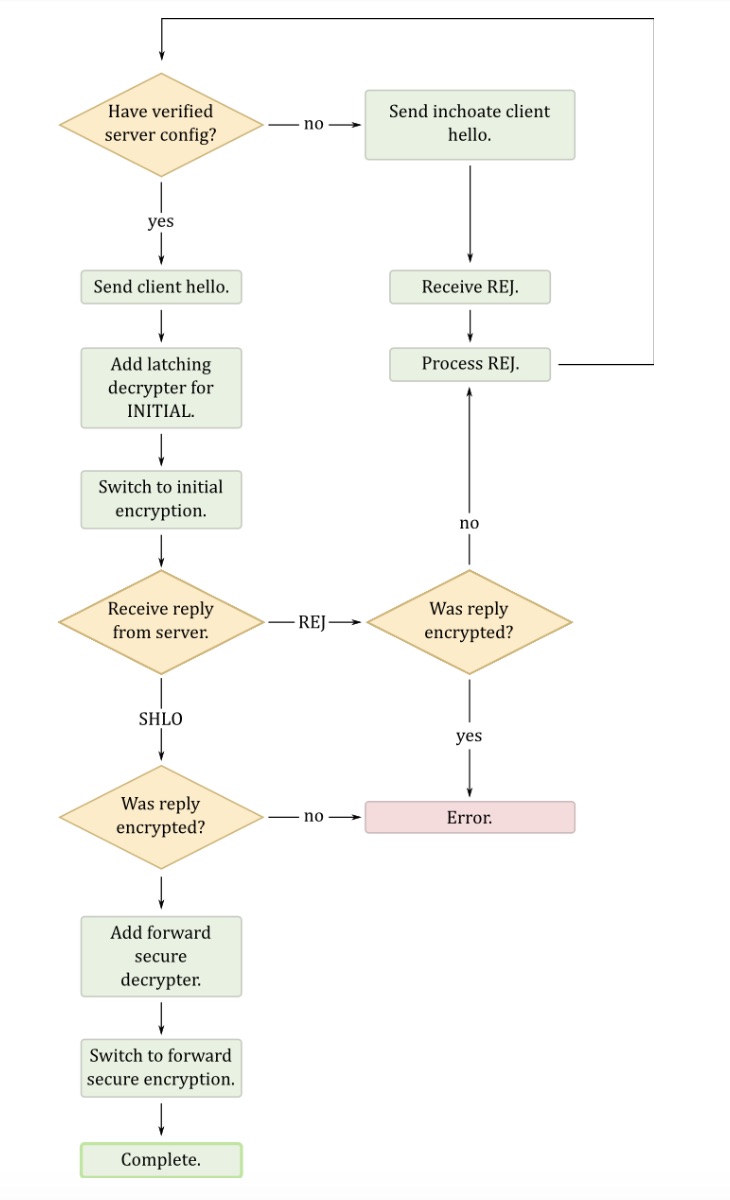
While the protocol had some flaws, in the end, it was still a beautiful and elegant protocol. At its core was an extremely straight forward and linear state machine summed up by this diagram:
A few things to help you read it:
a server config is just a blob that contains the server current semi-ephemeral keys. The server config is rotated every X days.
an inchoate client hello is just an empty client hello, which prompts the server to send a REJ(ect) message containing its latest config (after that the client can try again with a full client hello)
SHLO is a (encrypted) server hello which contains ephemeral keys
As you can see there isn't much going on, if you know the keys of the server you can do some 0-RTT magic, if you don't then request the keys and start the handshake again.
In the end, TLS 1.3 is a solid protocol, but I'd like to see more experimentation here instead of just relying on TLS. version 1.3 is built on top of numerous previous failed versions which means a great amount of complexity due to legacy and a multitude of use cases and extensions it needs to support. Simpler protocols should be better, simple state machines make for better analysis and more secure implementations. Just look at the Noise protocol framework and its 1k LOC implementations and its symbolic proofs done with ProVerif and Tamarin. Actually, why haven't we started using Noise for everything?
Did you know that a bitcoin transaction does not have a recipient field?
That's right! when crafting a transaction to send money on the bitcoin network, you actually do not include I am sending my BTC to _this address_. Instead, you include a script called a ScriptPubKey which dictates a set of inputs that are allowed to redeem the monies. The PubKey in the name surely refers to the main use for this field: to actually let a unique public key redeem the money (the intended recipient). But that's not all you can do with it! There exist a multitude of ways to write ScriptPubKeys! You can for example:
not allow anyone to redeem the BTCs, and even use the transaction to record arbitrary data on the blockchain (this is what a lot of applications built on top of bitcoin do, they "burn" bitcoins in order to create metadata transactions in their own blockchains)
allow someone who has a password to use the BTCs (but to submit the password, you would need to include it in clear inside a transaction which would inevitably be advertised to the network before actually getting mined. This is dangerous)
allow a subset of signatures from a fixed set of public keys to redeem the BTCs (this is what we call multi-sig transactions)
allow someone who can break a hash function (SHA-1) to redeem the BTCs (This is what Peter Todd did in 2013)
only allow the BTCs to be redeemed after some time in the future (via a timestamp)
etc.
On the other hand, if you want to use the money you need to prove that you can use such a transaction's output. For that you include a ScriptSig in a new transaction, which is another script that runs and creates a number of inputs to be used by the ScriptPubKey I talked about. And you guessed it, in our prime use-case this will include a signature (the Sig in the name)!
Recap: when you send BTCs, you actually send it to whoever can give you a correct input (created by a ScriptSig) to your program (ScriptPubKey). In more details, a Bitcoin transaction includes a set of input BTCs to spend and a set of output BTCs that are now redeemable by whoever can provide a valid ScriptSig. That's right, a transaction actually uses many previous transactions to collect money from, and spread them in possibly multiple pockets of money that other transactions can use. Each input of a transaction is associated to a previous transaction output, along with the ScriptSig to redeem it. Each output is associated with a ScriptPubKey. By the way, an output that hasn't been spent yet is called an UTXO for unspent transaction output.
The scripting language of Bitcoin is actually quite limited and easy to learn. It uses a stack and must return True at the end. The limitations actually bothered some people who thought it might be interesting to create something more turing-complete, and thus Ethereum was born.
You want to teach someone about a crypto concept, something 101 that could be explained in 1-2 pages with a lot of diagrams? Look no more, we need you.
Concept
The idea is to have a recurrent benevolent e-magazine (like POC||GTFO) that focuses on:
cryptography: duh! That being said, cryptography does include: implementations, cryptocurrencies, protocols, at scale, politics, etc. so there are more topics that we deem interesting than just theoretical cryptography.
pedagogy: heaps of diagrams and a focus on teaching. Taking an original writing style is a plus. We're looking not to bore readers.
101: we're looking for introductions to concepts, not deeply technical articles that require a lot of initial knowledge to grasp.
short: articles should be similar to a blog post, not a full-fledged paper. With that in mind articles should be around 1, 2 or 3 pages. We are not looking for something dense though, so no posters, rather a submission should be a light read that can be part of a series or influence the reader to read more about the topic.
Topics
Preferably, authors should write about something they are familiar with, but here is a list of topics that would likely be interesting for such a light magazine:
what is SSH?
what is SHA-3?
what is functional encryption?
what is TLS 1.3?
what is a linear differential attack?
what is a cache attack?
how does LLL work?
what are common crypto implementation tricks?
what is R-LWE?
what is a hash-based signature?
what is an RFC?
what is the IETF?
what is the IACR?
why are companies encrypting databases?
what is x509, .pem, asn.1 and base64?
etc...
Format
LaTeX if possible.
Deadline
No deadline at the moment.
How to submit
send me a dropbox link or something on the contact page, you can also send it to me via twitter
PS: I am going to annoy you if you don't use diagrams in your article
I will be at the Tamuro meetup in London tonight (at the George Inn pub). It's a meetup about security and cryptography. Feel free to join if you want to grab a beer and talk about supersingular isogenies.
I'm giving a talk about smart contract security at the IT Camp conference of Cluj Napoca, Romania on Thursday.
If anyone is there and wants to talk about crypto while drinking beer, contact me!
Last month I was in Singapore with Mason to talk about vulnerabilities in Ethereum smart contracts at Black Hat Asia. As part of the talk we released the DASP, a top 10 of the most damaging or surprising security vulnerabilities that we have observed in the wild or in private during audits we perform as part of our jobs.
The page is on github as well and we welcome contributions to the top 10 and the list of known exploits. In addition we're looking to host more projects related to the Ethereum space there, if you are looking for research projects or are looking to contribute on tools or anything that can make smart contracts development more secure, file an issue on github!
Note that I will be giving the talk again at IT Camp in Cluj-Napoca in a few months.