Quick access to articles on this page:
more on the next page...
There seem to be a few interesting trends in “security via hardware” these days.
The first trend is root-of-trust chips. Integrated TPM-like chips that are like crypto Swiss Army knives as they offer many functionalities out of the box. They resemble discrete TPMs but are instead implemented as coprocessor to the main processor. This makes these newer chips more resistant to physical MITM attacks (as discrete TPMs simply use a bus to communicate with other components). If you don’t know what a TPM is, it’s just a device that performs cryptographic operations and generally sits somewhere on your motherboard. Examples of these integrated security chips are Microsoft’s Pluton and Apple’s secure enclave.
The second trend is confidential computing. There are two types of specialized hardware here:
- Programmable integrated secure processors; these are similar to the root-of-trust chips, except that they are programmable: you can push code there and run it in a separate trusted execution environment (TEE). It’s pretty useful for applications that require a trusted computing base (TCB); a core program whose security is critical and that does not need to trust the rest of the system. It’s also useful in “cloud scenarios” where you want to run some computation on a remote machine but want to make sure it runs it correctly. Think about Intel SGX, or ARM TrustZone.
- Confidential VMs; imagine a hardware hypervisor that can run VMs as enclaves. This is usually much more practical than the enclave created by SGX, as you don’t need to write custom code and there are no memory limitation. But it is not clear to me how much security you lose against physical attacks by doing this (especially when papers like this one seem alarming). AMD SEV does this, and both Azure and GCP have started offerings to leverage this technology.
It can be hard to understand the difference between all these types of specialized hardware, the attacks they prevent, and the features they unlock. But essentially, here’s how I think about the two kinds: they all do great against software attacks (minus complex cryptographic attacks), they both aren’t the best tool in the box against a motivated physical attacker (HSMs are “better”), and only confidential computing cares about custom user code.
But it’s easier to understand the difference by looking at some examples. As I only touch on protocols, you can simply imagine these chips as creating a blackbox for code and data that others can’t see and touch (even with a debugger).
Protecting keys and data with a secure enclave
The simplest use case for hardware security chips is to protect data.
To protect keys, it’s easy: just generate them in the secure chip and disallow extraction.
If you need ‘em, just ask the secure enclave to perform crypto operations with them.
To protect data? Encrypt it! That concept is called file-based encryption (FBE) if you’re encrypting individual files, and full-disk encryption (FDE) if it’s the whole disk.
FDE sounds much better, as it’s all or nothing. If you're under the shower and you wet your hair a little, you know you'll have to wash them. That’s what most laptops and desktops use.
In practice, FDE is not that great though: it doesn't take into account how we, human beings, use our devices.
We often leave them locked, as opposed to turned off, so that background functionalities can keep running.
Computers deal with this by just keeping the data-encryption key (DEK) around, even if your computer is locked.
Think about that the next time you go to the restroom at Starbucks, leaving your locked computer unattended.
Phones do it a bit better by encrypting different types of files depending on if your phone is locked or turned off. It sounds like a good solution, but Zinkus et al. showed that it’s not that great either.
If done well, this is how you typically hear about disk encryption in the news:
A couple of months ago the highly-publicised case of Apple vs. FBI brought attention to the topic of privacy - especially in the context of mobile devices. Following the 2015 San Bernardino terrorist attack, the FBI seized a mobile phone belonging to the shooter, Syed Farook, with the intent to search it for any additional evidence or leads related to the ongoing investigation. However, despite being in possession of the device, the FBI were unable to unlock the phone and access its contents.
Of course, the user should be authenticated before data can be decrypted.
This is often done by asking the user for a PIN or password.
A PIN or password is not enough though, as it would allow simple brute-force attacks (especially on 4 or 6-digit PINs).
In general, solutions try to tie the DEK to both a user credential and a symmetric key kept on the enclave.
What’s that symmetric key?
We all know that you can’t hardcode the same key in every device you produce. This is dumb. You end up with attacks like DUHK where thousands of devices are found hardcoding the same secret (and pwning one device breaks all of them).
The solution is a per-device key that is either burned into the chip during manufacturing, or created by the chip itself (so-called physically unclonable functions).
For example, each Apple secure enclave have a UID, each TPM has a unique endorsement key and attestation key, each OpenTitan chip has a creator root key and an owner root key, etc.
A randomly generated UID is fused into the SoC at manufacturing time. Starting with A9 SoCs, the UID is generated by the Secure Enclave TRNG during manufacturing and written to the fuses using a software process that runs entirely in the Secure Enclave. This process protects the UID from being visible outside the device during manufacturing and therefore isn’t available for access or storage by Apple or any of its suppliers.
sepOS uses the UID to protect device-specific secrets. The UID allows data to be cryptographically tied to a particular device. For example, the key hierarchy protecting the file system includes the UID, so if the internal SSD storage is physically moved from one device to another, the files are inaccessible.
To prevent brute-force attacks, Apple’s secure enclave mixes both the UID key and the user PIN with a password-based KDF (password-hashing function) to derive the DEK.
Except that I lied: to allow user to change their PIN quickly, the DEK is actually not derived directly, but instead encrypted by a key-encryption key (KEK).
Secure boot with a root-of-trust secure chip
When booting your computer, there are different “stages” that will run until you finally get to the screen you want.
One problem users face are viruses and malwares, and these can infect the boot process.
You then run on an evil operating system…
To protect the integrity of boot, our integrated secure chips provide a “root of trust”, something that we trust 100% and that allows us to trust other stuff down the line.
This root of trust is generally some read-only memory (ROM) that cannot be overwritten, and it’s also called one-time programmable memory as it was written during manufacturing and can’t be changed anymore.
For example, when powering up a recent Apple device, the very first code that gets executed is inside the Apple’s secure enclave ROM (called Boot ROM).
That boot rom is tiny, so usually the only thing it does is:
- Prepare some protected memory and loads the next image there (so-called "boot code").
- Hash the image and verify its signature against the hardcoded public key in the ROM.
- Execute that code.
The next boot loader does the same thing, and so on until it gets to the device’s operating system. This is how updates that are not signed by Apple can’t be installed on your phone.
Confidential Computing with a programmable secure processor
There’s been a new paradigm for the last years: the cloud; big companies running servers to host your stuff. Amazon has AWS, Google has GCP, and Microsoft has Azure. Another way to put this is that people are moving from running things themselves, to running things on someone else’s computer. This of course create some issues in some scenarios where privacy is important. To fix that, confidential computing attempts at offering solutions to run client code without being able to see it or modify its behavior.
SGX primary use case seems to be exactly that these days: clients running code that the servers can’t see or tamper with.
One interesting problem that arise is: how can I trust that the response I got from my request indeed came from SGX, and not some impersonator. This is what attestation tries to solve. There are two kinds of attestation:
- local attestation, when two enclaves running on the same platform need to communicate and prove to each other that they are secure enclaves
- remote attestation, when a client queries a remote enclave and need to make sure that it was a legit enclave that produced the result from the request.
Each SGX chip is provided with unique keypairs at manufacturing time: the Root Sealing Keys.
The public key part is then signed by some Intel certificate authority. So the first assumption, if we ignore the assumption that the hardware is secure, is that Intel is correctly signing public keys of secure SGX chips only.
With that in mind, you can now obtained a signed attestation, from Intel's CA, that you're talking to a real SGX enclave, and that it is running some code (at least a proof of its digest), etc.
It’s 2020, most people have a computer in their pocket: a smart phone.
What is the point of a credit card anymore?
Well, not much. Nowadays more and more payment terminals support contactless payment via the near-field communication (NFC) protocol, and more and more smartphones ship with an NFC chip that can act as a credit card.
NFC for payment is specified as Card Emulation. Literally: it emulates a bank card.
But not so fast, banks will prevent you from doing this unless you have a secure element.
Since Apple has full control over its hardware, it can easily add a secure element to its new iPhones to support payment, and this is what Apple did with an embedded secure element bonded onto the NFC chip since the iPhone 6.
The secure element communicates directly with the NFC chip, and in turn to NFC readers; thus a compromise of the phone operating system does not impact the secure element.
Google went a different route, creating the concept of a cloud-based secure element, named Host Card Emulation (HCE), and introduced in 2013 in Android 4.4.
How does it work? Google stores your credit card information in a secure element in the cloud (instead of your phone), and only gives your phone access to a short-lived single-use account number.
This concept of replacing sensitive long-term information with short-lived tokens is called tokenization.
Sending a random card number that can be linked to your real one is great for privacy: merchants can’t track you as it’ll look like you’re always using a new card number.
If your phone gets compromised, the attacker only gets access to a short-lived secret that can only be used for a single payment.
Tokenization is a common concept in security: replace the sensitive data with some random stuff, and have a table secured somewhere safe that maps the random stuff to the real data.
Although Apple theoretically doesn't have to use tokenization, since iPhones have secure elements that can store the real Primary Account Number (PAN), they do use it in order to gain more privacy (it's after all their new bread and butter).
Password reuse is bad, what can we do about it?
Naively, users could use different passwords for different websites, but there are two problems with this approach:
- Users are bad at creating many different passwords.
- The mental load required to remember multiple passwords is impractical.
To alleviate these concerns, two solutions have been widely adopted:
- Single-sign on (SSO). The idea of SSO is to allow users to connect to many different services by proving that they own the account of a single service. This way the user only has to remember the password associated with that one service in order to be able to connect to many services. Think "connect with Facebook" type of buttons, as illustrated below.
- Password Managers. The previous SSO approach is convenient if the different services you use all support it, but this is obviously not scalable for scenarios like the web. A better approach in these extreme cases is to improve the clients as opposed to attempting to fix the issue on the server side. Nowadays, modern browsers have built-in password managers that can suggest complex passwords when you register on new websites, and can remember all of these passwords as long as you remember one master password.
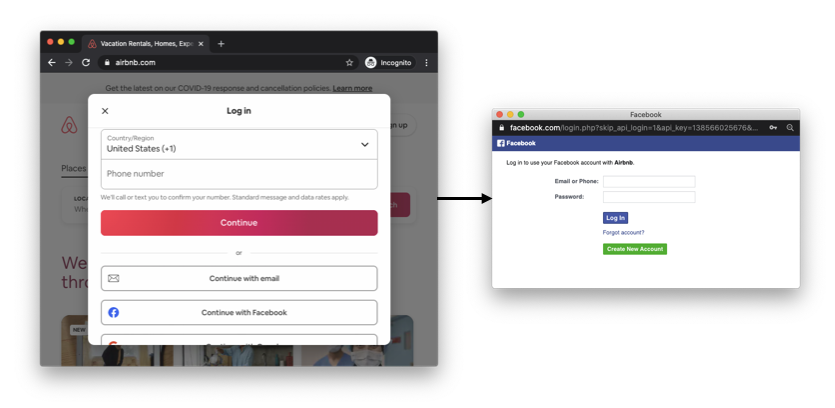
An example of single-sign on (SSO) on the web. By having an account on Facebook or Google, a user can connect to new services (in this example Airbnb) without having to think about a new password.
The concept of SSO is not new in the enterprise world, but its success with normal end-users is relatively recent.
Today, two protocols are the main competitors when it comes to setting up SSO:
- Security Assertion Markup Language 2.0 (SAML). A protocol using the Extensible Markup Language (XML) encoding.
- OpenID Connect (OIDC). An extension to the OAuth 2.0 (RFC 6749) authorization protocol using the JavaScript Object Notation (JSON) encoding.
SAML is still widely used, mostly in an enterprise setting, but it is at this point a legacy protocol.
OpenID Connect, on the other hand, can be seen everywhere on web and mobile applications. You most likely already used it!
While OpenID Connect allows for different types of flows, let's see the most common use case for user authentication on the web via the authorization code flow:
- Alice wants to log into some application, let's say
example.com, via an account she owns on cryptologie.net (that's just my blog, but let's pretend that you can register an account on it).
example.com redirects her browser to a specific page of cryptologie.net to request an "authorization code." If she is not logged-in in cryptologie.net, the website will first ask her to log in. If she is already logged-in, the website will still confirm with the user that they want to connect to example.com using their identity on cryptologie.net (it is important to confirm user intent).cryptologie.net redirects Alice back to example.com which then learns the authorization code.example.com can then query cryptologie.net with this authorization code to confirm Alice's claim that she owns an account on cryptologie.net, and potentially retrieve some additional profile information about that user.
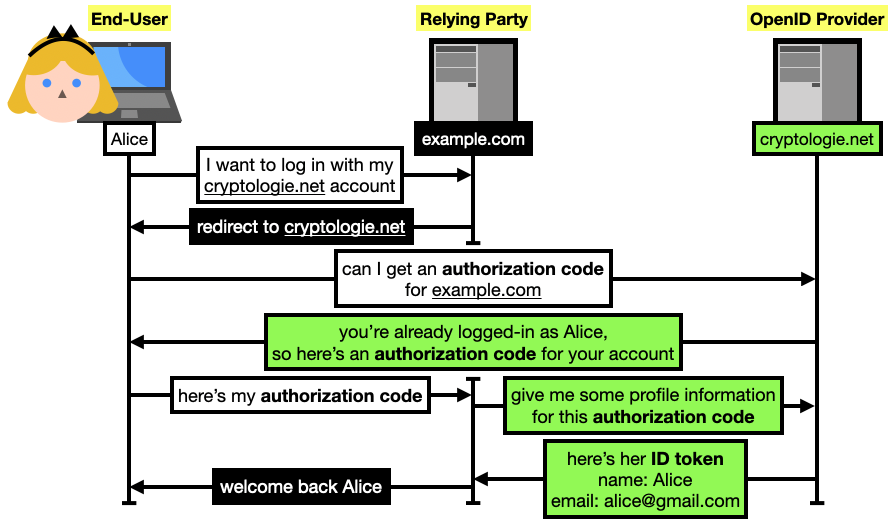
In OpenID Connect (OIDC), Alice (the end-user in OIDC terms) can authenticate to a service example.com (the relying party) using her already existing account on cryptologie.net (the OpenID provider). For the web, the authorization code flow of OIDC is usually used. It starts by having Alice request an "authorization code" from cryptologie.net (and that can only be used by example.com). example.com can then use it to query cryptologie.net for Alice's profile information (encoded as an ID token), and then associate her cryptologie.net identity with an account on their own platform.
There are many important details that I am omitting here.
For example, the authorization token that Alice receives in step 2 must be kept secret, as it can be used to log in as her on example.com.
Another example: so that example.com cannot reuse the authorization token to connect as Alice on a different website, the OpenID provider cryptologie.net retains an association between this authorization token and the intended audience (example.com).
This can be done by simply storing this association in a database, or by having the authorization code contain this information authenticated (I explained a similar technique with cookies in chapter 3).
By the way, the proof given to example.com in step 4 is called an ID token in OpenID Connect, and is represented as a JSON Web Token (JWT) which is just a list of JSON-encoded data.
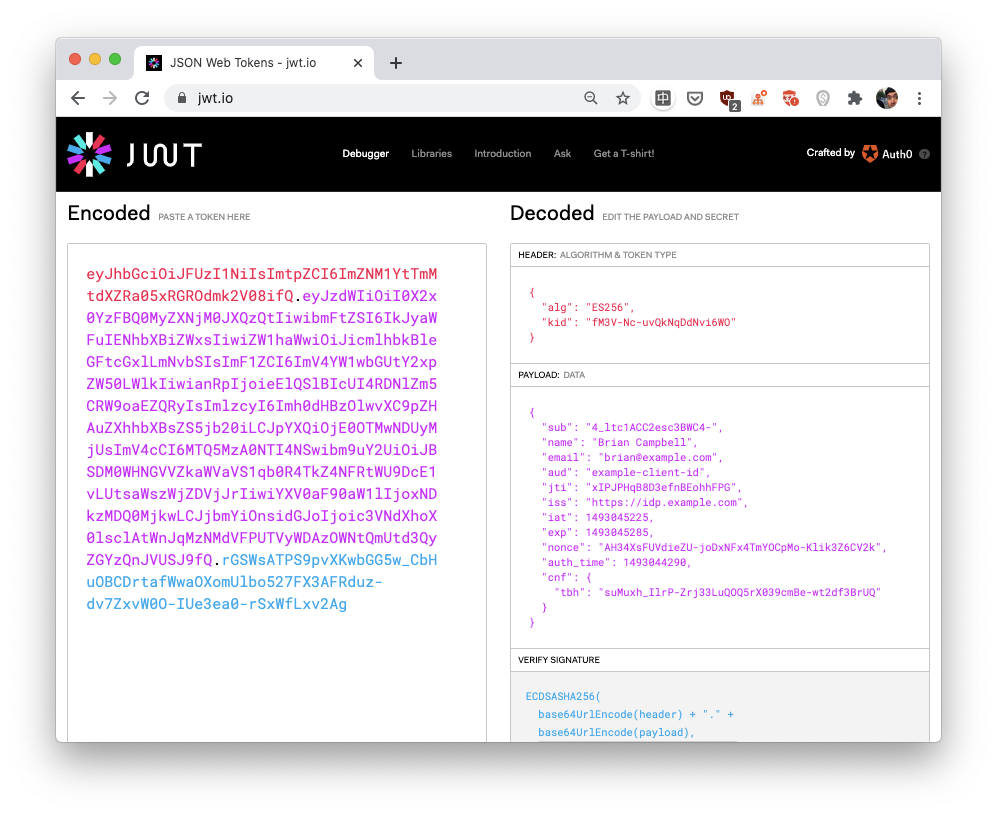
In OpenID Connect, if Alice wants to log in on example.com via her account on another website (an OpenID provider), example.com eventually needs to obtain what is called an "ID token." An ID token is some user information encoded via the JSON Web Token (JWT) standard. a JWT is simply the concatenation of three JSON-encoded objects. In the picture, the website https://jwt.io lets you decode a JWT and learn what every field stands for. In our browser-based example, example.com uses TLS to communicate with (and authenticate) the OpenID provider. Thus, the ID token it receives can be trusted. In other OpenID Connect flows (used, for example, by mobile applications) the ID token can be provided directly by the user, and can thus be tampered with. In this case, an ID token contains a signature which can be verified using the OpenID provider's public key.
Authentication protocols are often considered hard to get right.
OAuth2, the protocol OpenID Connect relies on, is notorious for being easy to mis-use (see RFC 6819: OAuth 2.0 Threat Model and Security Considerations).
On the other hand, OpenID Connect is very well specified.
Make sure that you follow the standards and that you look at best practices, this can save you from a lot of trouble.
Here's another example of a pretty large company deciding not to follow this advice.
In May 2020, the "Sign-in with Apple" SSO flow that took a departure from OpenID Connect was found to be vulnerable.
Anyone could have obtained a valid ID token for any Apple account, just by querying Apple's servers.
SSO is great for users, as it reduces the number of passwords they have to manage, but it does not remove passwords altogether.
The user still has to use passwords to connect to OpenID providers.
If you're interested to know how cryptography can help to hide passwords, read the rest of this content in my book real-world cryptography.
Thanks to filippo streaming his adventures rewriting Golang assembly code into "cleaner" Golang assembly code, I discovered the Avo assembly generator for Golang.
This post is not necessarily about Golang, but Golang is a good example as its standard library is probably the best cryptographic standard library of any programming language.
At dotGo 2019, Michael McLoughlin presented on his Avo tool.
In the talk he mentions that there's 24,962 x86 assembly lines in Golang's standard library, and most of it is in the crypto package. A very "awkward" place where "we need very high performance, and absolute correctness". He then shows several example that he describes as "write-once code".
The talk is really interesting and I recommend you to check it.
I personally spent days trying to understand Golang's SHA-3 assembly implementation. I even created a Go Assembly by Example page to help me in this journey. And I ended up giving up. I just couldn't understand how it worked, the thing didn't make sense. Someone had written it with their own mental model of how they wanted to pass data around. It was horrible.
It's not just a problem of Golang. Look at OpenSSL, for example, which most cryptographic applications and libraries rely on. It contains a huge amount of assembly code to implement cryptography, and that assembly code is sometimes generated by unintelligible perl code.
There are many more good examples out there. the BearSSL TLS implementation by Thomas Pornin, the libsodium cryptographic library by Frank Denis, the extended keccak code package by the Keccak team, all use assembly code to produce fast cryptography.
We're making such a fuss about readable, auditable, simple and clear cryptographic implementations, but most of that has been thrown out of the window in the quest for performance.
The real problem, from a reviewer perspective is that assembly is getting us much further away from the specification. As the role of a reviewer is to match the implementation to the specification, it makes the job hard, perhaps impossible.
Food for thoughts...
If you know about authenticated encryption, you could stop reading here, understand that you can just use AES-GCM or Chacha20-Poly1305 whenever you need to encrypt something, and move on with your life. Unfortunately real-world cryptography is not always about the agreed standard, it is also about constraints. Constraints in size, constraints in speed, constraints in format, and so on. For this reason, we need to look at scenarios where these AEADs won't fit, and what solutions have been invented by the field of cryptography.
Wrapping keys: how to encrypt secrets
One of the problem of nonce-based AEADs is that they all require a nonce, which takes additional space. In worse scenarios, the nonce to-be-used for encryption comes from an untrusted source and can thus lead to nonce repetition that would damage the security of the encryption. From these assumptions, it was noticed that encrypting a key might not necessarily need randomization, since what is encrypted is already random.
Encrypting keys is a useful paradigm in cryptography, and is used in a number of protocol as you will see in the second part of this book.
The most widely adopted standard is NIST Special Publication 800-38F, Recommendation for Block Cipher Modes of Operation: Methods for Key Wrapping.
It specifies two key wrapping algorithms based on AES: the AES Key Wrap (KW) mode and the AES Key Wrap With Padding (KWP) mode.
These two algorithms are often implemented in Hardware Security Modules (HSM). HSMs are devices that are capable of performing cryptographic operations while ensuring that keys they store cannot be extracted by physical attacks. That's at least if you're under a certain budget.
These key-wrapping algorithms do not take an additional nonce or IV, and randomize their encryption based on what they are encrypting. Consequently, they do not have to store an additional nonce or IV next to the ciphertexts.
AES-GCM-SIV and nonce-misuse resistance authenticated encryption
In 2006, Rogaway published a new key-wrapping algorithm called Synthetic initialization vector (SIV), as part of Deterministic Authenticated-Encryption: A Provable-Security Treatment of the Key-Wrap Problem.
In the white paper, Rogaway notes that the algorithm is not only useful to encrypt keys, but as a general AEAD algorithm as well that is resistant to nonce repetitions.
As you probably know, a repeating nonce in AES-GCM or Chacha20-Poly1305 has catastrophic consequences. It not only reveals the XOR of the two plaintexts, but it also allows an attacker to recover an authentication key and to forge more messages. In Nonce-Disrespecting Adversaries: Practical Forgery Attacks on GCM in TLS, a group of researchers found 184 HTTPS servers being guilty of reusing nonces. (I even wrote here about their super-cool live demo.)
The point of a nonce-misuse resistant algorithm is that encrypting two plaintexts with the same nonce will only reveal if the two plaintexts are equal or not.
It is sometimes hard to obtain good randomness on constrained devices or mistakes can be made. In this case, nonce-misuse resistant algorithms solve real problems.
In the rest of this section, I describe the scheme standardized by Google in RFC 8452, AES-GCM-SIV: Nonce Misuse-Resistant Authenticated Encryption.
The idea of AES-GCM-SIV is to generate the encryption and authentication keys separately via a main key every time a message has to be encrypted (or decrypted). This is done by producing a keystream long enough with AES-CTR, the main key and a nonce:
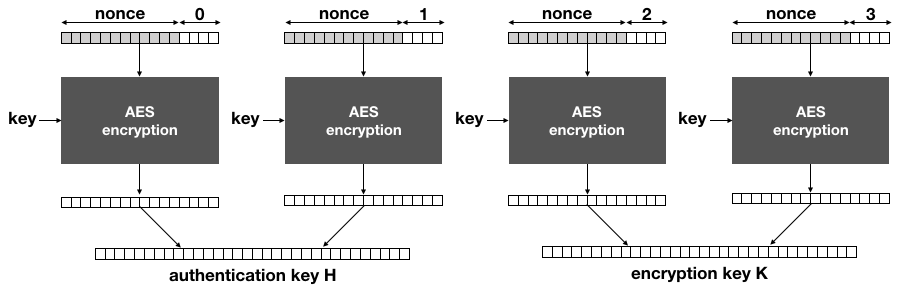
The main key of AES-GCM-SIV is used solely with AES-CTR to derive the encryption key K and the authentication key H.
Notice that if the same nonce is used to encrypt two different messages, the same keys will be derived here.
Next, AES-GCM-SIV authenticates the plaintext, instead of the ciphertexts as we have seen in the previous schemes. This creates an authentication tag over the associated data and the plaintext (and their respective lengths). Instead of GMAC, AES-GCM-SIV defines a new MAC called Polyval. It is quite similar and only attempts to optimize some of GMAC's operations.
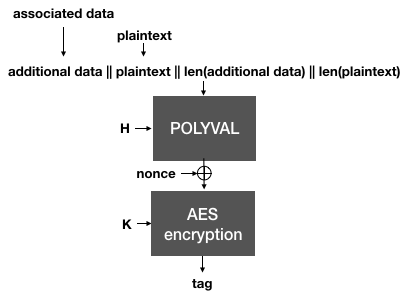
The Polyval function is used to hash the plaintext and the associated data. It is then encrypted with the encryption key K to produce an authentication tag.
Importantly, notice that if the same nonce is reused, two different messages will of course produce two different tags. This is important because in AES-GCM-SIV, the tag is then used as a nonce to AES-CTR in order to encrypt the plaintext.
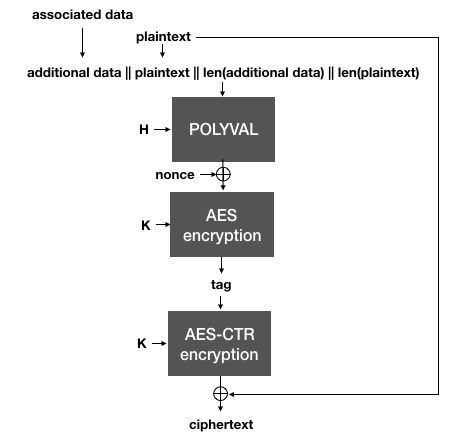
AES-GCM-SIV uses the authentication tag (created with Polyval over the plaintext and the associated data) as a nonce for AES-CTR to encrypt the plaintext.
This is the trick behind SIV: the nonce used to encrypt in the AEAD is generated from the plaintext itself, which makes it highly unlikely that two different plaintexts will end up being encrypted under the same nonce. To decrypt, the same process is done in reverse:
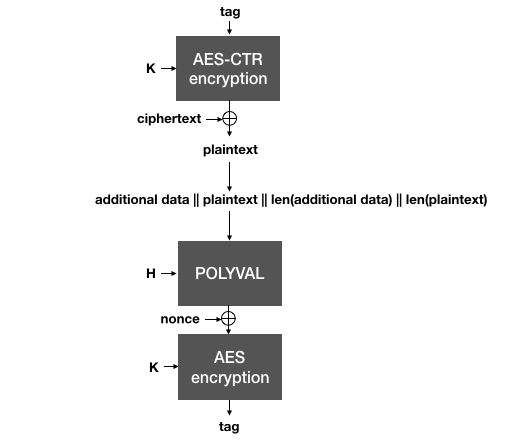
AES-GCM-SIV decrypts a ciphertext by using the authentication as a nonce for AES-CTR. The plaintext recovered is then used along with the associated data to validate the authentication tag. Both tags need to be compared (in constant-time) before releasing the plaintext to the application.
As the authentication tag is computed over the plaintext, the ciphertext must first be decrypted (using the tag as an effective nonce). Then, the plaintext must be validated against the authentication tag. Because of that, one must realize two things:
- The plaintext is released by the algorithm before it can be authenticated. For this reason it is extremely important that nothing is done with the plaintext, until it is actually deemed valid by the authentication tag verification.
- Since the algorithm works by decrypting the ciphertext (respectively encrypting the plaintext) as well as authenticating the plaintext, we say that it is two-pass -- it must go over the data twice. Because of this, it usually is slower than its counterpart AES-GCM.
SIV is a powerful concept that can be implemented for other algorithms as well.
Take a look at the following program that you can run in Golang's playground.
// sign a message
hash, _ := hex.DecodeString("ffffffff00000000ffffffffffffffffbce6faada7179e84f3b9cac2fc632552")
r, s, err := ecdsa.Sign(rand.Reader, privateKey, hash[:])
if err != nil {
panic(err)
}
// print the signature
signature := r.Bytes()
signature = append(signature, s.Bytes()...)
fmt.Println("signature:", hex.EncodeToString(signature))
// verify the signature
if !ecdsa.Verify(&privateKey.PublicKey, hash[:], r, s) {
panic("wrong signature")
} else {
fmt.Println("signature valid for", hex.EncodeToString(hash[:]))
}
// I modify the message, this should invalidate the signature
var hash2 [32]byte
hash2[31] = 1
if !ecdsa.Verify(&privateKey.PublicKey, hash2[:], r, s) {
panic("wrong signature")
} else {
fmt.Println("signature valid for", hex.EncodeToString(hash2[:]))
}
this should print out:
signature: 4f3e60dc53ab470d23e82567909f01557f01d521a0b2ae96a111d107741d8ebb885332d790f0691bdc900661bf40c595a07750fa21946ed6b88c61c43fbfc1f3
signature valid for ffffffff00000000ffffffffffffffffbce6faada7179e84f3b9cac2fc632552
signature valid for 0000000000000000000000000000000000000000000000000000000000000001
Can you tell what's the problem? Is ECDSA broken? Is Golang's standard library broken? Is everything fine?
On August 11th, 2015, Andrew Ayer sent an email to the IETF mailing list starting with the following words:
I recently reviewed draft-barnes-acme-04 and found vulnerabilities in the DNS, DVSNI, and Simple HTTP challenges that would allow an attacker to fraudulently complete these challenges.
The draft-barnes-acme-04 mentioned by Andrew Ayer is a document specifying ACME, one of the protocols behind the Let's Encrypt certificate authority.
A certificate authority is the thing that your browser trusts and that signs the public keys of websites you visit.
It is called a "certificate" authority due to the fact that it does not sign public keys, but certificates.
A certificate is just a blob of data bundling a website's public key, its domain name, and some other relevant metadata.
The attack was found merely 6 weeks before major browsers were supposed to start trusting Let's Encrypt's public key. The draft has since become RFC 8555: Automatic Certificate Management Environment (ACME),
mitigating the issues.
Since then no cryptographic attacks are known on the protocol.
This blog post will go over the accident, and explain why it happened, why it was a surprising bug, and what you should watch for when using signatures in cryptography.
How Let's Encrypt used signatures
Let's Encrypt is a pretty big deal. Created in 2014, it is a certificate authority run as a nonprofit, providing trust to hundreds of millions of websites.
The key to Let's Encrypt's success are twofold:
- It is free. Before Let's Encrypt most certificate authorities charged fees from webmasters who wanted to obtain certificates.
- It is automated. If you follow their standardized protocol, you can request, renew and even revoke certificates via a web interface. Contrast that to other certificate authorities who did most processing manually, and took time to issue certificates.
If a webmaster wants her website example.com to provide a secure connection to her users (via HTTPS), she can request a certificate from Let's Encrypt (essentially a signature over its domain name and public key), and after proving that she owns the domain example.com and getting her certificate issued, she will be able to use it to negotiate a secure connection with any browser trusting Let's Encrypt.
That's the theory.
In practice the flow goes like this:
- Alice registers on Let's Encrypt with an RSA public key.
- Alice asks Let's Encrypt for a certificate for
example.com.
- Let's Encrypt asks Alice to prove that she owns
example.com, for this she has to sign some data and upload it to example.com/.well-known/acme-challenge/some_file.
- Once Alice has signed and uploaded the signature, she asks Let's Encrypt to go check it.
- Let's Encrypt checks if it can access the file on
example.com, if it successfully downloaded the signature and the signature is valid then Let's Encrypt issues a certificate to Alice.
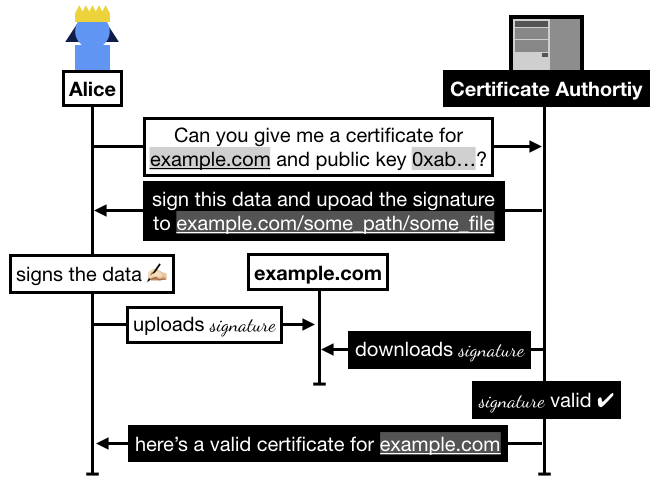
In 2015, Alice could request a signed certificate from Let's Encrypt by uploading a signature (from the key she registered with) on her domain. The certificate authority verifies that Alice owns the domain by downloading the signature from the domain and verifying it. If it is valid, the authority signs a certificate (which contains the domain's public key, the domain name example.com, and some other metadata) and sends it to Alice who can then use it to secure her website in a protocol called TLS.
Let's see next how the attack worked.
How did the Let's Encrypt attack work?
In the attack that Andrew Ayer found in 2015, Andrew proposes a way to gain control of a Let's Encrypt account that has already validated a domain (let's pick example.com as an example)
The attack goes something like this (keep in mind that I'm simplifying):
- Alice registers and goes through the process of verifying her domain
example.com by uploading some signature over some data on example.com/.well-known/acme-challenge/some_file. She then successfully manages to obtain a certificate from Let's Encrypt.
- Later, Eve signs up to Let's Encrypt with a new account and an RSA public key, and request to recover the
example.com domain
- Let's Encrypt asks Eve to sign some new data, and upload it to
example.com/.well-known/acme-challenge/some_file (note that the file is still lingering there from Alice's previous domain validation)
- Eve crafts a new malicious keypair, and updates her public key on Let's Encrypt. She then asks Let's Encrypt to check the signature
- Let's Encrypt obtains the signature file from
example.com, the signature matches, Eve is granted ownership of the domain example.com. She can then ask Let's Encrypt to issue valid certificates for this domain and any public key.
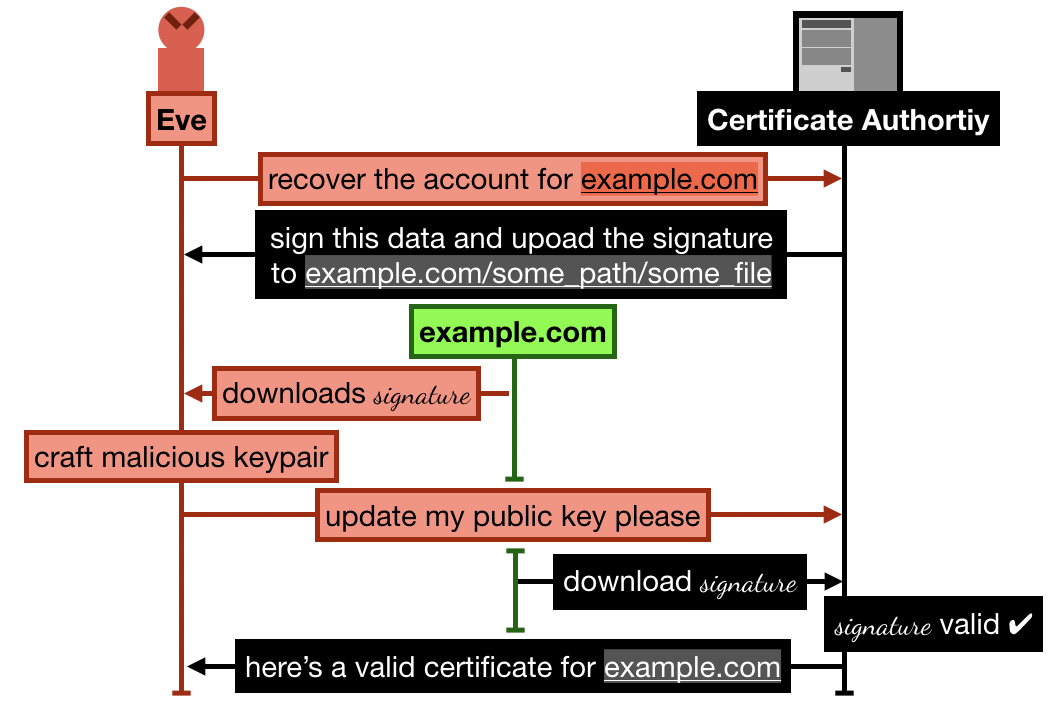
The 2015 Let's Encrypt attack allowed an attacker (here Eve) to successfully recover an already approved account on the certificate authority. To do this, she simply forges a new keypair that can validate the already existing signature and data from the previous valid flow.
Take a few minutes to understand the attack.
It should be quite surprising to you.
Next, let's see how Eve could craft a new keypair that worked like the original one did.
Key substitution attacks on RSA
In the previously discussed attack, Eve managed to create a valid public key that validates a given signature and message.
This is quite a surprising property of RSA, so let's see how this works.
A digital signature does not uniquely identify a key or a message. -- Andrew Ayer, Duplicate Signature Key Selection Attack in Let's Encrypt (2015)
Here is the problem given to the attacker:
for a fixed signature and (PKCS#1 v1.5 padded) message, a public key $(e, N)$ must satisfy the following equation to validate the signature:
$$signature = message^e \pmod{N}$$
One can easily craft a key pair that will (most of the time) satisfy the equation:
- a public exponent $e = 1$
- a private exponent $d = 1$
- a public modulus $N = \text{signature} - \text{message}$
You can easily verify that the validation works with this keypair:
$$\begin{align}
&\text{signature} = \text{message}^e \mod{N} \\
\iff &\text{signature} = \text{message} \mod{\text{signature} - \text{message}} \\
\iff &\text{signature} - \text{message} = 0 \mod{\text{signature} - \text{message}}
\end{align}$$
Is this issue surprising?
It should be.
This property called "key substitution" comes from the fact that there exists a gap between the theoretical cryptography world and the applied cryptography world, between the security proofs and the implemented protocols.
Signatures in cryptography are usually analyzed with the EUF-CMA model, which stands for Existential Unforgeability under Adaptive Chosen Message Attack.
In this model YOU generate a key pair, and then I request YOU to sign a number of arbitrary messages.
While I observe the signatures you produce, I win if I can at some point in time produce a valid signature over a message I hadn't requested.
Unfortunately, even though our modern signature schemes seem to pass the EUF-CMA test fine, they tend to exhibit some surprising properties like the key substitution one.
To learn more about key substitution attack and other signature shenanigans, take a look at my book Real-World Cryptography.
I've now spent 2 years writing my introduction on applied cryptography: Real-World Cryptography, which you can already read online here.
(If you're wondering why I'm writing another book on cryptography check this post.)
I've written all the chapters, but there's still a lot of work to be done to make sure that it's good (collecting feedback), that it's consistent (unification of diagrams, of style, etc.), and that it's well structured.
For the latter point, I thought I would leverage the fact that I'm an engineer and use a tool that's commonly used to measure performance: a flamegraph!
It looks like this, and you can click around to zoom on different chapters and sections:

How does this work?
The bottom layer shows all the chapter in order, and the width of the boxes show how lengthy they are.
The more you go up, the more you "nest" yourself into a section.
For example, clicking on the chapter 9: Secure transport, you can see that it is composed of several sections with the longest being "How does TLS work", which itself is composed of several subsections with the longest being "The TLS handshake".

What is it good for?
Using this flamegraph, I can now analyze how consistent the book is.
Distribution
The good news is that the chapters all seem pretty evenly distributed, for the exception of shorter chapters 3 (MACs), 6 (asymmetric encryption), and 16 (final remarks).
This is also expected are these chapters are much more straightforward than the rest of the book.
Too length
Looks like the bigger chapters are in order: post-quantum crypto, authenticated encryption, hardware cryptography, user authentication, secure transport.
This is not great, as post-quantum crypto is supposed to be a chapter for the curious people who get to the end of the book, not a chapter to make the book bigger...
The other chapters are also unnecessary long.
My goal is going to be to reduce these chapters' length in the coming weeks.
Too nested
This flamegraph is also useful to quickly see if there are sections that are way too nested. For example, Chapter 9 on secure transport has a lot of mini sections on TLS.
Also, look at some of the section in chapter 5: Key exchanges > Key exchange standards > ECDH > ECDH standard. That's too much.
Not nested enough
Some chapters have almost no nested sections at all. For example, chapter 8 (randomness) and 16 (conclusion) are just successions of depth-1 sections. Is this a bad thing? Not necessarily, but if a section becomes too large it makes sense to either split it into several sections, or have subsections in it.
I've noticed, for example, that the first section of chapter 3 on MACs titled "What is a MAC?" is quite long, and doesn't have subsections.

(Same for section 6.2 asymmetric encryption in practice and section 8.2 what is a PRNG)
Errors
I also managed to spot some errors in nested sections by doing this! So that was pretty cool as well :)
EDIT: If you're interested in doing something like this with your own project, I published the script here.

