Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
Trevor Perrin talked about Message Encryption from an historical point of view, from key directories to public key infrastructures and how to authenticate users to each other. Something interesting that Trevor talked about was CONIKS, some sort of Certificate Transparency-like protocol but for secure messaging (they call it key transparency).
when Alice wants to send a secure message to some other user, say Bob, her CONIKS client looks up Bob's key at the key directory, and verifies that this key has not changed unexpectedly over time. It also checks that this key is consistent with the key other clients are seeing for Bob. Only if these two consistency checks pass will the CONIKS client send Alice's message to Bob. The CONIKS client also performs these same checks for Alice's own key on a regular basis to ensure that the service provider is not tampering with Alice's key.
This sounds like an audit system (users can check what a key distribution server has been up to) + a gossip protocol (users can talk between them to verify consistency of the obtained public keys). Which seems like an excellent idea and makes me wonder why would Signal not use it.
djb mentioned the Self-Healing feature of ZRTP, similar to the recovery feature of Signal.
ZRTP caches symmetric key material used to compute secret session keys, and these values change with each session. If someone steals your ZRTP shared secret cache, they only get one chance to mount a MiTM attack, in the very next session. If they miss that chance, the retained shared secret is refreshed with a new value, and the window of vulnerability heals itself, which means they are locked out of any future opportunities to mount a MiTM attack. This gives ZRTP a "self-healing" feature if any cached key material is compromised.
Signal's self-healing property comes from the fact that an ephemeral Diffie-Hellman key agreement is continuously happening during communication. Like ZRTP it seems like it works out well only if the attacker is slow to act, thus it doesn't seem to be exactly comparable to backward secrecy (which might just be impossible in a protocol).
Later, someone (I don't know who from Felix Günther, Britta Hale, Tibor Jager and Sebastian Lauer because the program doesn't specify who the speaker is), presented on a 0-RTT system that would provide forward secrecy and anti-replayability. 0-RTT is one of the feature of TLS 1.3, which allows a client to start sending encrypted data to a server during its very first flight of messages. Unfortunately, and this was the topic of many discussions on TLS 1.3, these messages are replayable.
The work builds on top of Math Green's work with Puncturable Encryption where the server (and the client?) use some key derivation system and remove parts of it after a message has been sent using the 0-RTT feature. I am not sure if this system is really efficient though, especially since the point of 0-RTT is to be able to be fast. If this solution isn't faster or, worse, slower than doing a normal TLS 1.3 handshake (1.5 round trips) then the 0-RTT has no meaning in life anymore.
It also seems like this wouldn't be applicable to the "ticket" way of doing 0-RTT in TLS 1.3, which basically encrypts the whole state and hand up the opaque blob to the client, this way the server doesn't store anything.
Hugo Krawczyk (the HKDF guy) talked about passwords and leaks with some Comic Sans MS (and there was this handy website to check if your username/password/... had been compromised). Hugo then presented some of his recent work on SPHINX, PPSS, X-PAKE, ... everything is listed with link to papers here.
SPHINX is a client-focused and transparent-to-the-server password manager (like all of them really). The desktop password manager uses some derivation parameter stored online or on a user's mobile phone to derive any website key from a master password. The online service or the mobile phone never sees anything (thanks to a simple blinding technique, reminding me of what Ari Juel did last year's RWC with PASS). Because of that, no offline attack are possible. The slides are here and are pretty self explanatory. I have to admit that the design makes a lot of sense to me. I dozed off for the second part of the talk but it was about "How to store a secret" and his PPSS thing (Password Protected Secret Sharing), same for the third part of the talk that was about X-PAKE, which I can imagine was a mix of his ideas with the PAKE protocol.
There were two talks about memory-hardness and proving that password hashing functions are memory-hard. It seemed like some people think it's important that these functions be data-independent as well (probably because in some cases cache attacks might be an issue). Most of the techniques here seemed to make sure that a minimum amount of memory was to be used at all time, and that this couldn't be reduced. I would have liked to see a comparison between Argon2 (the winner of the PHC), Blake 2 (which seems to be the thing people like and use) and Balloon Hashing (which seems to be Dan Boneh's new thing).
George Tankersley and Filippo Valsorda finished the day with a talk on Cloudflare and their CAPTCHA problem. A lot of attacks/spam seems to come from TOR, which has deteriorated the reputation of the TOR nodes' IPs. This means that when Cloudflare sees some traffic coming from TOR, it will present the user with a CAPTCHA to make sure they are dealing with a human. TOR users tend to strongly dislike Cloudflare because these CAPTCHA are shown for every different website, and for every time the TOR path is changed (10 minutes?). This, in addition to TOR already slowing down your browsing efficiency, has annoyed more than one person. Cloudflare is trying to remediate the problem by giving not one, but N tokens to the user for one CAPTCHA solved. By using blind signatures Cloudflare hopes to demonstrate its inability to deanonymize users by using a CAPTCHA token as a tracking cookie.
(I have been made aware of this problem in the past and have manually added TOR visitors as an "allowed country" in my Cloudflare's setup for cryptologie.net., which is one of the solution given to Cloudflare's customers.)
The Lechvin prize was given to Joan Daemen, co-inventor of AES and SHA3, and to Moxie Marlinspike and Trevor Perrin for their work on the development on secure messaging.
Daemen talked about how block cipher might become a thing from the past, replaced by more efficient and faster permutation constructions (like the permutation-baed sponge construction they developed for SHA3).
Moxie Marlinspike gave an brilliant speech. Putting that into words would only uglify whatever was said, you will have to take my words for it.
Rich Salz gave a touching talk about the sad history of OpenSSL.
Thai Duong presented his Project Wycheproof that test java cryptographic libraries for common cryptographic pitfalls. They have something like 80 test vectors (easy to export to test other languages) and have uncovered 40+ vulnerabilities. One is being commented here.
L Jean Camp gave a talk on some X.509 statistics across phishing websites and the biggest websites (according to some akamai ranking). No full ipv4 range stats. Obviously the phishing websites were not bothering with TLS. And the speaker upset several people by saying that phishing websites should not be able to obtain certificates for similar-looking domains. Adam Langley took the mic to explain to her how orthogonal these issues were, and dropped the mic with a "we will kill the green lock".
Quan Nguyen gave a nice talk about some fun crypto vulns. Unfortunately I was dozing off, but everyone seemed to have appreciated the talk and I will be checking these slides as soon as they come up. (Some "different" ways to retrieve the authentication key from AES-GCM)
Daniel Franke presented the NTS (Network Time Security) protocol. It looks like it could protect NTP. Is it a competitor of roughtime? On the roughtime page we can read:
The obvious answer to this problem is to authenticate NTP replies. Indeed, if you want to do this there‘s NTPv4 Autokey from six years ago and NTS, which is in development. A paper at USENIX Security this year detailed how to do it so that it’s stateless at the server and still mostly using fast, symmetric cryptography.
But that's what NTP should have been, 15 years ago—it just allows the network to be untrusted. We aim higher these days.
So I guess NTS is not coming fast enough, hence the creation of roughtime. I personally like how anyone can audit roughtime servers.
Tancrède Lepoint presented on CRYSTAL, a lattice-based key exchange that seems like a competitor to New Hope. He also talked about Open Quantum Safe that contains a library of post quantum primitives as well as a fork of OpenSSL making use of this library. Someone from the public appeared to be pretty angry not to be cited first in the research, but the session chair (Dan Boneh) smoothly saved us from an awkward Q/A.
Mike Hamburg came up with STROBE, a bespoke TLS-like protocol based on one sponge construction. It targets embedded devices but isn't really focusing on speed (?) It's also heavily influenced by BLINKER and tries to improve it. It kinda felt like a competitor of the Noise Protocol Framework but looking at the paper it seems more confusing than that and much more interesting as well. From the paper:
Strobe is a framework for building cryptographic two-party protocols. It can also be used for symmetric cryptosystems such as hashing, AEAD, MACs, PRFs and PRNGs. It is also useful as the symmetric part of a Schnorr-style signature scheme.
That's it. If anyone can point me to other notes on the talks I'd gladly post a list of links in here as well:
I've been thinking a lot about sweet32 recently. And I decided to try to reproduce their results.
First let me tell you that the attack is highly impractical. It requires the user to execute some untrusted javascript for dozens of hours without interruption. The other problem that I encountered was that I couldn't reach the amount of requests they were able to make a client send. In their paper, they claim to be able to reach up to 2,000 requests per second.
I tried to achieve such good numbers with "normal" browsers, and the amount of requests I was able to make was ridiculously low. Then I realized that they used a specific browser: Firefox Developer Edition. A browser made for developing websites. For some unknown reason, it was true that this specific browser was able to send an impressive amount of requests per second. Although I was never able to reach that magical number of 2,000. And even then, who really uses Firefox Developer Edition?
It should be noted that their attack was done in a lab, with a small distance between the client and the server, under perfect condition, when no other traffic was slowing down the attack, etc... I can't imagine this attack being practical at all in real settings.
Note that I can imagine different settings than TLS, at a different point in time in the future, being able to send enough requests per second that this attack would be deemed practical. And in that sense, Sweet32 should be taken seriously. But for now, and especially in the case of TLS, I wouldn't freak out if I see a 64-bit block cipher being used.
A lot of attacks are theorized only to become practical years or decades later. This was the case with Bleichenbacher's and Vaudenay's padding oracle attacks, but also BEAST.
Realizing that Chosen-plaintext attacks were do-able on TLS -- because browsers would execute untrusted code on demand (javascript) -- a myriad of cryptanalysts decided to knock down on TLS.
POODLE was the first vulnerability that made us deprecate SSL 3.0. It broke the protocol in such a critical way that even a RFC was published about it.
BEAST was the one that made us move away from TLS 1.0. But a lot of embedded devices and products still use these lower versions and it would be unfair not to say that an easy patch can be applied to implementations of TLS 1.0 to counter this vulnerability.
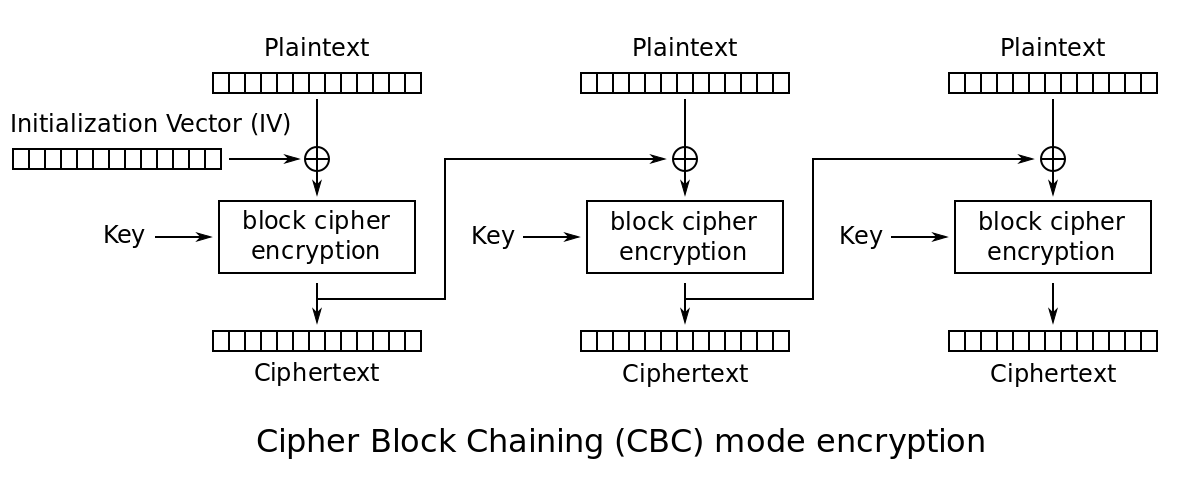
BEAST comes from the fact that in TLS 1.0 the next message being encrypted with CBC will use the previous ciphertext's last block as IV. This makes the IV predictable and allow you to decrypt ciphertexts by sending many chosen plaintexts.
the diagram of CBC for encryption taken from wikipedia. Here imagine that the IV is the previous ciphertext's last block.
The counter measures server-side are well known: move to greater versions of TLS. But if the server cannot fix this, one simple counter measure can be applied on the client-side (remember, this is a client-side vulnerability, it allows a MITM attacker to recover session IDs, cookies, etc...).
Again: BEAST works because the MITM attacker can predict the next IV. He can just observe the previous ciphertext block and craft the plaintext based on it. It's an interactive attack.
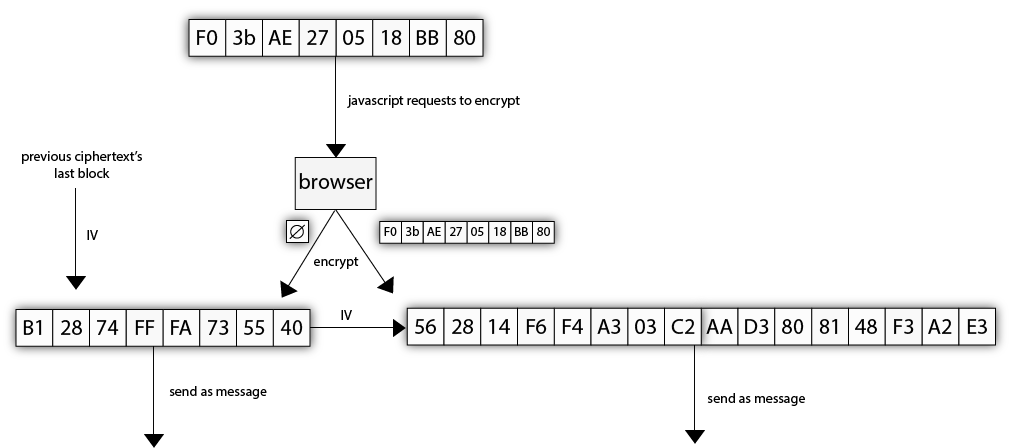
One way of preventing this is to send an empty message before sending each message. The empty message will produce a ciphertext (of essentially the MAC), which the attacker will not be able to predict. The message that the attacker asked the browser to encrypt will thus be encrypted with this unpredictable IV. The attacked is circumvented.
This counter measure is called a 0/n split.
Unfortunately a lot of servers did not like this countermeasures too much. Chrome pushed that first and kind of broke the web for some users. Adam Langley talks about them paying the price for fixing this "too soon". Presumably this "no data" message would be seen by some implementations as a EOF (End Of File value).
One significant drawback of the current proposed countermeasure (sending empty application data packets) is that the empty packet might be rejected by the TLS peer (see comments #30/#50/others: MSIE does not accept empty fragments, Oracle application server (non-JSSE) cannot accept empty fragments, etc.)
To fix this, Firefox pushed a patch called a 1/n-1 split, where the message to be sent would be split into two messages, the first one containing only 1 byte of the plaintext, and the second one containing the rest.
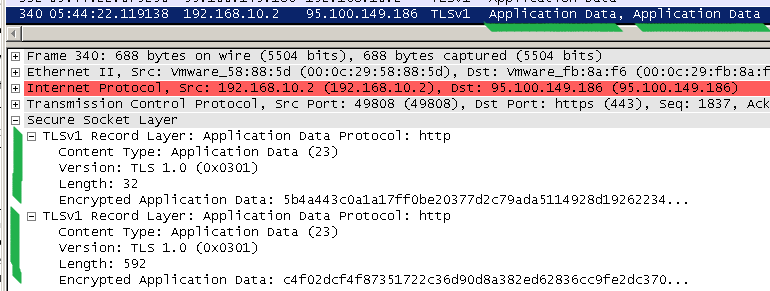
If you look at a fixed client implementation sending messages over a negotiated TLS 1.0 connection, you will see that first it will send the first byte (in the screenshot below, the "G" letter), and then send the rest in a different TLS message.
If you're curious, you can see that being done in code in the recent BearSSL TLS library of Thomas Porning.
static unsigned char *
cbc_encrypt(br_sslrec_out_cbc_context *cc,
int record_type, unsigned version, void *data, size_t *data_len)
{
unsigned char *buf, *rbuf;
size_t len, blen, plen;
unsigned char tmp[13];
br_hmac_context hc;
buf = data;
len = *data_len;
blen = cc->bc.vtable->block_size;
/*
* If using TLS 1.0, with more than one byte of plaintext, and
* the record is application data, then we need to compute
* a "split". We do not perform the split on other record types
* because it turned out that some existing, deployed
* implementations of SSL/TLS do not tolerate the splitting of
* some message types (in particular the Finished message).
*
* If using TLS 1.1+, then there is an explicit IV. We produce
* that IV by adding an extra initial plaintext block, whose
* value is computed with HMAC over the record sequence number.
*/
if (cc->explicit_IV) {
/*
* We use here the fact that all the HMAC variants we
* support can produce at least 16 bytes, while all the
* block ciphers we support have blocks of no more than
* 16 bytes. Thus, we can always truncate the HMAC output
* down to the block size.
*/
br_enc64be(tmp, cc->seq);
br_hmac_init(&hc, &cc->mac, blen);
br_hmac_update(&hc, tmp, 8);
br_hmac_out(&hc, buf - blen);
rbuf = buf - blen - 5;
} else {
if (len > 1 && record_type == BR_SSL_APPLICATION_DATA) {
/*
* To do the split, we use a recursive invocation;
* since we only give one byte to the inner call,
* the recursion stops there.
*
* We need to compute the exact size of the extra
* record, so that the two resulting records end up
* being sequential in RAM.
*
* We use here the fact that cbc_max_plaintext()
* adjusted the start offset to leave room for the
* initial fragment.
*/
size_t xlen;
rbuf = buf - 4 - ((cc->mac_len + blen + 1) & ~(blen - 1));
rbuf[0] = buf[0];
xlen = 1;
rbuf = cbc_encrypt(cc, record_type, version, rbuf, &xlen);
buf ++;
len --;
} else {
rbuf = buf - 5;
}
}
/*
* Compute MAC.
*/
br_enc64be(tmp, cc->seq ++);
tmp[8] = record_type;
br_enc16be(tmp + 9, version);
br_enc16be(tmp + 11, len);
br_hmac_init(&hc, &cc->mac, cc->mac_len);
br_hmac_update(&hc, tmp, 13);
br_hmac_update(&hc, buf, len);
br_hmac_out(&hc, buf + len);
len += cc->mac_len;
/*
* Add padding.
*/
plen = blen - (len & (blen - 1));
memset(buf + len, (unsigned)plen - 1, plen);
len += plen;
/*
* If an explicit IV is used, the corresponding extra block was
* already put in place earlier; we just have to account for it
* here.
*/
if (cc->explicit_IV) {
buf -= blen;
len += blen;
}
/*
* Encrypt the whole thing. If there is an explicit IV, we also
* encrypt it, which is fine (encryption of a uniformly random
* block is still a uniformly random block).
*/
cc->bc.vtable->run(&cc->bc.vtable, cc->iv, buf, len);
/*
* Add the header and return.
*/
buf[-5] = record_type;
br_enc16be(buf - 4, version);
br_enc16be(buf - 2, len);
*data_len = (size_t)((buf + len) - rbuf);
return rbuf;
}
Note that this does not protect the very first byte we send. Is this an issue? Not for browsers. But the next time you encounter this in a different setting, think about it.
I see some discussions on some mailing lists about what parameters to use for Diffie-Hellman (DH).
It seems like the recent line of papers about weak Diffie-Hellman parameters (Logjam) and Diffie-Hellman backdoors (socat, the RFC 5114, the special primes, ...) has troubled more than one.
This is a non-problem. We don't need a RFC to choose Diffie-Hellman groups. A simple openssl gendh -out keyfile -2 2048 will generate a 2048-bit safe prime along with correct DH parameters for you to use. If you're worried about "special primes" issues, either make it yourself with this command, or pick a larger (let's say 4096-bit safe prime) from a list and verify that it's a safe prime. You can use this tool for that.
But since some people really don't want to do the work, here are some safe parameters you can use.
2048-bit parameters for Diffie-Hellman
Here's is the .pem file containing the parameters:
The Cryptography Services team of NCC Group is looking for a summer 2017 intern!
We are looking for you if you're into cryptography and security! The internship would allow you to follow consultants on the job as well as lead your own research project.
Who are we? We are consultants! Big companies come to us and ask us to hack their stuff (legally), review their code and advise on their design. If we're not doing that, we spend our time reading papers, researching, attending conferences, giving talks and teaching classes, ... whatever floats our boat. Not one week is like the other! If you've spent some time doing cryptopals challenges you will probably like what we are doing.
We can't say much about who are the clients we work for, except for the public audits we sometimes do. For example we've performed public audits for TrueCrypt, OpenSSL, Let's Encrypt, Docker and more recently Zcash.
I was myself the first intern of Cryptography Services and I'd be happy to answer any question you might have =)
I wrote a gist here on certificate validation/creation pitfalls. I don't know if it is up for release but I figured I would get more input, and things to add to it, if I would just released it. So, go check it out and give me your feedback here!
Here's a copy of the current version:
Certificate validation/creation pitfalls
A x509 certificate, and in particular the latest version 3, is the standard for authentication in Public Key Infrastructures (PKIs). Think about Google proving that he's Google before you can communicate with him.
So. Heh. This x509 thing is a tad complicated. Trying to parse such a thing usually end up in the creation of a lot of different vulnerabilities. I won't talk about that here. I will talk about the other complicated thing about them: using them correctly!
So here's a list of pitfalls in the creation of such certificates, but also in the validation and use of them when encountering them in the wild wild web (or in your favorite infrastructure).
explanation: keyUsage is a field inside a x509 v3 certificate that limits the power of the public key inside the certificate. Can you only use it to sign? Or can it be used as part of a key Exchange as well (ECDH)? etc...
best practice: Specify the KeyUsage at creation, verify the keyUsage when encountering the certificate. keyCertSign should be used if the certificate is a CA, keyAgreement should be used if a key exchange can be done with the public key of the certificate.
Validity ::= SEQUENCE {
notBefore Time,
notAfter Time }
best practice: Reject certificates that have a notBefore date posterior to the current date, or that have a notAfter date anterior to the current date.
Critical extensions
explanation: x509 certificate is an evolving standard, exactly like TLS, through extensions. To preserve backward compatibility, not being able to parse an extension is often considered OK, that is unless the extension is considered critical (important).
Extension ::= SEQUENCE {
extnID OBJECT IDENTIFIER,
critical BOOLEAN DEFAULT FALSE,
extnValue OCTET STRING
-- contains the DER encoding of an ASN.1 value
-- corresponding to the extension type identified
-- by extnID
}
best practice: at creation mark every important extensions as critical. At verification make sure to process every critical extensions. If a critical extension is not recognized, the certificate MUST be rejected.
Hostname Validation
explanation:
Knowing who you're talking to is really important. A x509 certificate is tied to a specific domain/organization/email/... if you don't check who it is tied to, you are prone to impersonation attacks. Because of reasons, these things can be seen in different places in the subject field or in the Subject Alternative Name (SAN) extension. For TLS, things are standardized differently and it will always need to be checked in the latter field.
This is one of the trickier issues in this list as hostname validation is protocol specific (as you can see TLS does things differently) and left to the application. To quote OpenSSL:
One common mistake made by users of OpenSSL is to assume that OpenSSL will validate the hostname in the server's certificate
Often, implementations will just check if the subject Name contains the string mywebsite.com, or will use a vulnerable regex that either accept mywebsite.com.evil.com or evil subdomains. Check moxie's presentation (null bytes) to hear more about hostname validation failures.
best practice: During creation, check for the subject as well as the subject alternative name fields. During verification, check that the leaf certificate matches the domain/person you are talking to. If TLS is the protocol being used, check that in the subject alternative name field, only one level of wildcard is allowed and it must be on the leftmost position (*.domain.com is allowed, sub.*.domain.com is forbidden). Consult RFC 6125 for more information.
explanation: the BasicConstraints extension dictates if a certificate is a CA (can sign others) or not. If it is, it also says how many CAs can follow it before a leaf certificate.
best practice: set this field to the relevant value when creating a certificate. When validating a certificate chain, make sure that the pathLen is valid and the cA field is set to TRUE for each non-leaf certificate.
Name Constraints
explanation: the NameConstraints extension contains a set of limitations for CA certificates, on what kind of certificates can follow them in the chain.
best practice: when creating a CA certificate, be aware of the constraints chained certificates should have and document it in the NameConstraints field. When verifying a CA certificate, verify that each certificate in the certificate chain is valid according to the requirements of upper certificates.