Quick access to articles on this page:
more on the next page...
I spent a lot of time reading this blogpost today and thought to myself: this is a great blog post. If there was a blogging award for security/crypto blogposts this would probably be the front runner for 2017.
But I can't really blog about it, because we're still waiting for a lot more good blog posts to come this year.
So what I decided to do instead, is to go through all the blog posts that I liked last year (it's easy, I have a list here) and find out which ones stood out from the rest.
please do not get offended if yours is not in there, I might have just missed it!
How does a blog post make it to the list? It has to be:
- Interesting. I need to learn something out of it, whatever the topic is. If it's only about results I'm generally not interested.
- Pedagogical. Don't dump your unfiltered knowledge on me, I'm dumb. Help me with diagrams and explain it to me like I'm 5.
- Well written. I can't read boring. Bonus point if it's funny :)
So here it is, a list of my favorite Crypto-y/Security blogposts for the year of 2016:
- The amazing series of Thai Duong's The Internet of Broken Protocols. Don't read the answer right away, try to solve them yourself, it's fun :)
- Crypto Classics: Wiener's RSA Attack. The explanation is top notch. If I could have something like that for every crypto attack I would know everything.
- The most incredible hiding-in-the wild backdoor found: OpenSSL key recovery attack on DH small subgroups (CVE-2016-0701) (it also merged into a paper and was nominated in the pwnie awards).
- Adam Langley on Cryptographic Agility which shows a lot of the arguments behind TLS 1.3's design.
- BearSSL and many of its documentation pages (yes I know, these are not blog posts but they read like blog posts).
- Filippo with his explanation (and finding) of the pen and paper Bleichenbacher 2006 signature forgery
- The hilarious Graphing when your Facebook friends are awake. (Not really crypto.)
- Another hilarious post: Playing games with an attacker: how I messed with someone trying to breach the CryptoWall tracker. (Again, more security than crypto.)
- All the blogposts on Matthew Green's blog. The one on Sweet32, the iMessage attack, the DROWN attack, ...
- The Goldreich–Goldwasser–Halevi (GGH) Cryptosystem and Nyguen’s Attack by Kelby Ludwig. Will teach you about lattices, a lattice-based cryptosystem and an attack while showing you how to see these things in Sage.
- The Hunting For Vulnerabilities in Signal series by Jean-Philippe Aumasson and Markus Vervier.
- The excellent Cloudflare blog has many crypto blog posts, for example this article by Filippo on TLS nonce-nse
- A Survival Guide to a PhD.
- Literally everything on the blog of Stephane Bortzmeyer (warning: it's in french).
- The crypto work of Quarkslab. Here's their analysis of Confide.
- Ransomware: Past, Present, and Future. I haven't read this one but it seems so complete I couldn't not include it :)
Did I miss one? Make me know in the comments :]
Tamarin will sometimes be unable to find the real source of a premise ([premise]-->[conclusion]) and will end up spinning until the scary words "partial deconstructions" will be flashed at the screen.

Raw sources is Tamarin trying to find the source of each of your rules. That's a bunch of pre-computation to help him prove things afterwards, because Tamarin works like that under the hood (or so I've heard): it searches for things backward.
(This might be a good reason to start designing your protocol from the end!)
Partial deconstructions can happen when for example you happen to have used a linear fact both in the premise and the conclusion of a rule:
rule creation:
[Fr(~a)]-->[Something(~a)]
rule loop:
[Something(a)]-->[Something(a), Out(a)]
This is bad, because when looking for the source of the loop rule, Tamarin will find the loop rule as a possible origin. This over and over and over.
Source lemmas are special lemmas that can be used during this pre-computation to get rid of such loops. They basically prove that for such loop rules, there is a beginning: a creation rule. Source lemmas are automatically proven using induction which is the relevant strategy to use when trying to prove such things.
Refined sources are the raw sources helped by the source lemmas. If your wrote the right source lemmas, you will get rid of the partial deconstructions in the refined sources and Tamarin will use the refined sources for its proofs instead of the raw sources.
Persistent Facts is the answer. Anytime we have a linear fact persisting across a rule, there is little reason (I believe) not to use a persistent fact (which also allows to model replays in the protocol). We can now rewrite our previous rules with a bang:
rule creation:
[Fr(~a)]-->[!Something(~a)]
rule loop:
[!Something(a)]-->[Out(a)]
This way Tamarin will always correlate this Fact to its very creation.
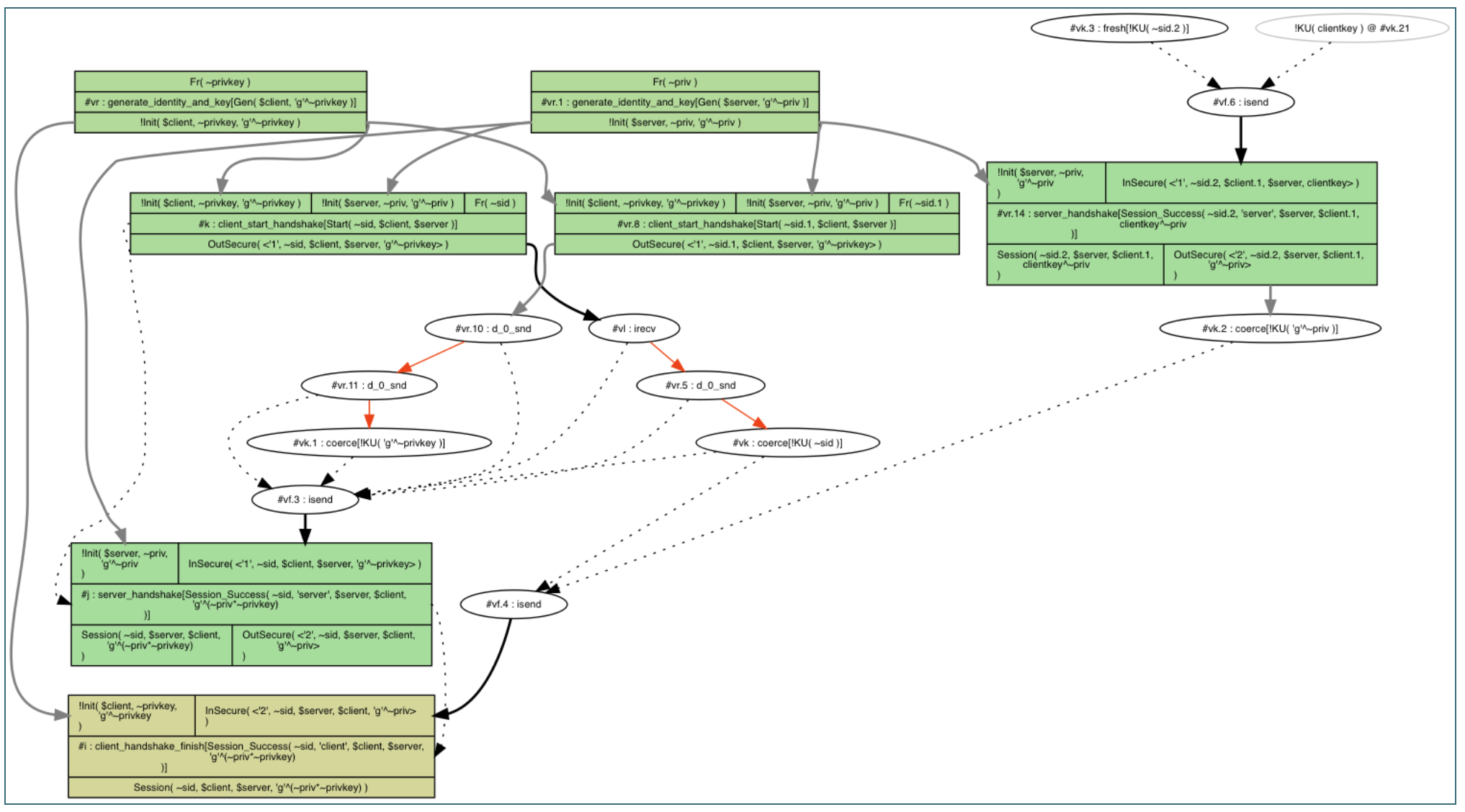
This is not a nice trace
Learning about the inners of Tamarin, I've came up to the point where I wanted to get a nice clean trace to convince myself that the protocol I wrote made sense.
The way to check for proper functioning is to create exist-trace lemmas.
Unfortunately, using Tamarin to prove such lemma will not always yield the nicest trace.
Here are some tricks I've used to obtain a simple trace. Note that these matter less when you're writing lemmas to "attack" the protocol (as you really don't want to impose too many restrictions that might not hold in practice).
1. Use a fresh "session id". A random session id can be added to different states and messages to identify a trace from another one.
rule client_start_handshake:
[!Init($client, ~privkey, pubkey), !Init($server, ~priv, pub), Fr(~sid)]
--[Start(~sid, $client, $server)]->
[Out(<'1', ~sid, $client, $server, pubkey>)]
2. Use temporals to make sure that everything happens in order.
Ex sid, client, server, sessionkey #i #j.
Start(sid, client, server) @ #i &
Session_Success(sid, 'server', server, client, sessionkey) @ #j &
#i < #j
3. Make sure your identities are different. Start by defining your lemma by making sure a server cannot communicate with itself.
Ex sid, client, server, sessionkey #i #j.
not(server = client) & ...
4. Use constraints to force peers to have a unique key per identity. Without that, you cannot force Tamarin to believe that one identity could create multiple keys. Of course you might want your model to allow many-keys per identity, but we're talking about a nice trace here :)
restriction one_key_per_identity: "All X key key2 #i #j. Gen(X, key) @ #i & Gen(X, key2) @ #j ==> #i = #j"
rule generate_identity_and_key:
let pub = 'g'^~priv
in
[ Fr(~priv) ]--[Gen($A, pub)]->[ !Init($A, ~priv, pub) ]
5. Disable the adversary. This might be the most important rule here, and it ended up being the breakthrough that allowed me to find a nice trace. Unfortunately you cannot disable the adversary, but you can force Ins and Outs to happen via facts (which are not seen by the adversary, and remove any possible interaction from the adversary). For this you can replace every In and Out with InSecure and OutSecure and have these rules:
#ifdef not_debug
[OutSecure(a)] -->[Out(a)]
[In(a)] -->[InSecure(a)]
#endif
#ifdef debug
[OutSecure(a)]-->[InSecure(a)]
#endif
You can now call tamarin like this:
tamarin interactive . -Dnot_debug
And we now have a nice trace!
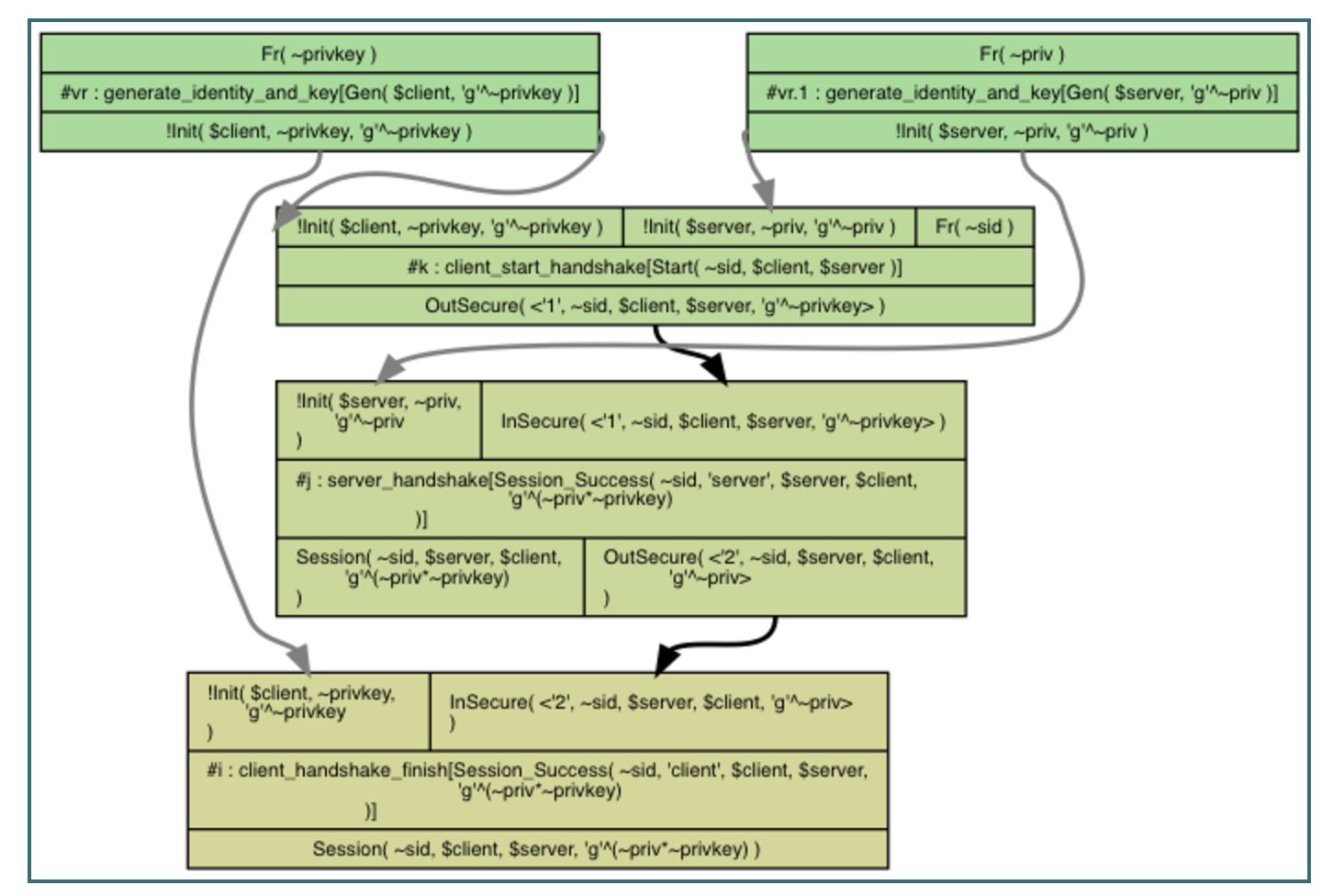
Our protocol is an opportunistic Diffie-Hellman. You can see the two generate_identity_and_key rules at the top that creates the two different identities: a client and a server.
The second rule client_start_handshake is used to start the handshake. The client sends the first message 1 with a fresh session id ~sid.
The third rule server_handshake propagates the received session id to the next message and to its action fact (so that the lemma can keep the session id consistent).
The protocol ends in the last rule client_handshake_finish being used.
Voila!
PS: thanks to Katriel Cohn-Gordon for answering ten thousands of my questions about Tamarin.
When playing around with KangarooTwelve I noticed that the python implementation's right_encode() function was not consistent with the C version:
python implementation of right_encode
λ python right_encode.py
right_encode(0): [0]
right_encode(1): [1][3]
right_encode(2): [2][3]
right_encode(255): [255][5]
right_encode(256): [1][0][6]
right_encode(257): [1][1][6]
C implementation of right_encode:
λ ./right_encode
right_encode(0): 00
right_encode(1): 0101
right_encode(2): 0201
right_encode(255): ff01
right_encode(256): 010002
right_encode(257): 010102
The problem was that the python implementation used the function bytes() to create byte strings, which has breaking behaviors between python2 and python3.
python2:
>>> bytes([1])
'[1]'
python3:
>>> bytes([1])
b'\x01'
The fix was to use bytearray() instead which is consistent across the two versions of Python.

In late 2008, 64 candidates took part in NIST's hashing competition, fighting to replace the SHA-2 family of hash functions.
Keccak won the SHA-3 competition, and became the FIPS 202 standard on August 5, 2015.
All the other contenders lost. The final round included Skein, JH, Grøstl and BLAKE.
Interestingly in 2012, right in the middle of the competition, BLAKE2 was released. Being too late to take part in the fight to become SHA-3, it just stood on its own awkwardly.
Fast forward to this day, you can now read an impressive list of applications, libraries and standards making use of BLAKE2. Argon2 the winner of the Password Hashing Competition, the Noise protocol framework, libsodium, ...
On their page you can read:
BLAKE2 is a cryptographic hash function faster than MD5, SHA-1, SHA-2, and SHA-3, yet is at least as secure as the latest standard SHA-3. BLAKE2 has been adopted by many projects due to its high speed, security, and simplicity.
And it is indeed for the speed that BLAKE2 is praised. But what exactly is BLAKE2?
BLAKE2 relies on (essentially) the same core algorithm as BLAKE, which has been intensively analyzed since 2008 within the SHA-3 competition, and which was one of the 5 finalists. NIST's final report writes that BLAKE has a "very large security margin", and that the the cryptanalysis performed on it has "a great deal of depth". The best academic attack on BLAKE (and BLAKE2) works on a reduced version with 2.5 rounds, whereas BLAKE2b does 12 rounds, and BLAKE2s does 10 rounds. But even this attack is not practical: it only shows for example that with 2.5 rounds, the preimage security of BLAKE2b is downgraded from 512 bits to 481 bits, or that the collision security of BLAKE2s is downgraded from 128 bits to 112 bits (which is similar to the security of 2048-bit RSA).
And that's where BLAKE2 shines. It's a modern and secure hash function that performs better than SHA-3 in software. SHA-3 is fast in hardware, this is true, but Intel does not have a good track record of quickly implementing cryptography in hardware. It is only in 2013 that SHA-2 joined Intel's set of instructions, along with SHA-1...
What is being done about it?
Some people are recommending SHAKE. Here is what the Go SHA-3 library says on the subject:
If you aren't sure what function you need, use SHAKE256 with at least 64 bytes of output. The SHAKE instances are faster than the SHA3 instances; the latter have to allocate memory to conform to the hash.Hash interface.
But why is SHA-3 slow in software? How can SHAKE be faster?
This is because SHA-3's parameters are weirdly big. It is hard to know exactly why. The NIST provided some vague explanations. Other reasons might include:
- Not to be less secure than SHA-2. SHA-2 had 256-bit security against pre-image attacks so SHA-3 had to provide the same (or at least a minimum of) 256-bit security against these attacks. (Thanks to Krisztián Pintér for pointing this out.)
- To be more secure than SHA-2. Since SHA-2 revealed itself to be more secure than we previously thought, there was no reason to develop a similar replacement.
- To give some credits to the NIST. In view of people's concerns with NIST's ties with the NSA, they could not afford to act lightly around security parameters.
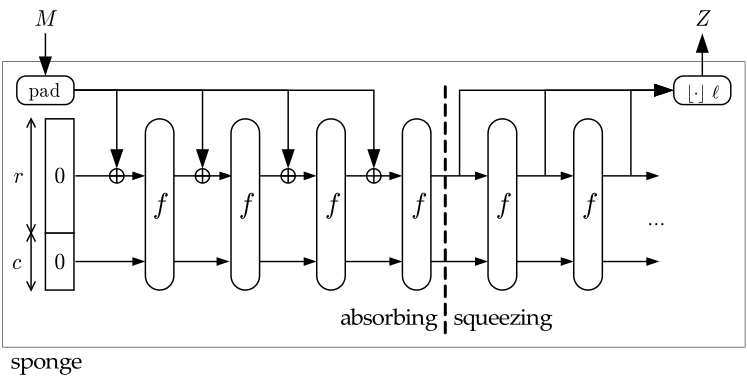
The following table shows the parameters of the SHAKE and SHA-3 constructions. To understand them, you need to understand two of the parameters:
- The rate (
r): it is the block size of the hash function. The smaller, the more computation will have to be done to process the whole input (more calls to the permutation (f)).
- The capacity (
c): it is the secret part of the hash function. You never reveal this! The bigger the better, but the bigger the smaller is your rate :)
| algorithm | rate | capacity | mode (d) | output length (bits) | security level (bits) |
| SHAKE128 | 1344 | 256 | 0x1F | unlimited | 128 |
| SHAKE256 | 1088 | 512 | 0x1F | unlimited | 256 |
| SHA3-224 | 1152 | 448 | 0x06 | 224 | 112 |
| SHA3-256 | 1088 | 512 | 0x06 | 256 | 128 |
| SHA3-384 | 832 | 768 | 0x06 | 384 | 192 |
| SHA3-512 | 576 | 1024 | 0x06 | 512 | 256 |
The problem here is that SHA-3's capacities is way bigger than it has to be.
512 bits of capacity (secret) for SHA3-256 provides the square root of security against (second pre-image attacks (that is 256-bit security, assuming that the output used is long enough). SHA3-256's output is 256 bits in length, which gives us the square root of security (128-bit) against collision attacks (birthday bound). We end up with the same theoretical security properties of SHA-256, which is questionably large for most applications.
Keccak even has a page to tune its security requirements which doesn't advise such capacities.
Is this really the end?
Of course not. In the end, SHA-3 is a big name, people will use it because they hear about it being the standard. It's a good thing! SHA-3 is a good hash function.
People who know what they are doing, and who care about speed, will use BLAKE2 which is equally as good of a choice.
But these are not the last words of the Keccak's team, and not the last one of this blog post either. Keccak is indeed a surprisingly well thought construction relying on a single permutation. Used in the right way it HAS to be fast.
Mid-2016, the Keccak team came back with a new algorithm called KangarooTwelve. And you might have guessed, it is to SHA-3 what BLAKE2 is to BLAKE.
It came with 12 rounds instead of 24 (which is still a huge number compared to current cryptanalysis) and some sane parameters: a capacity of 256 bits like the SHAKE functions.
Tree hashing, a feature allowing you to parallelize hashing of large files, was also added to the mix! Although sc00bz says that they do not provide a "tree hashing" construction but rather a" leaves stapled to a pole" construction.
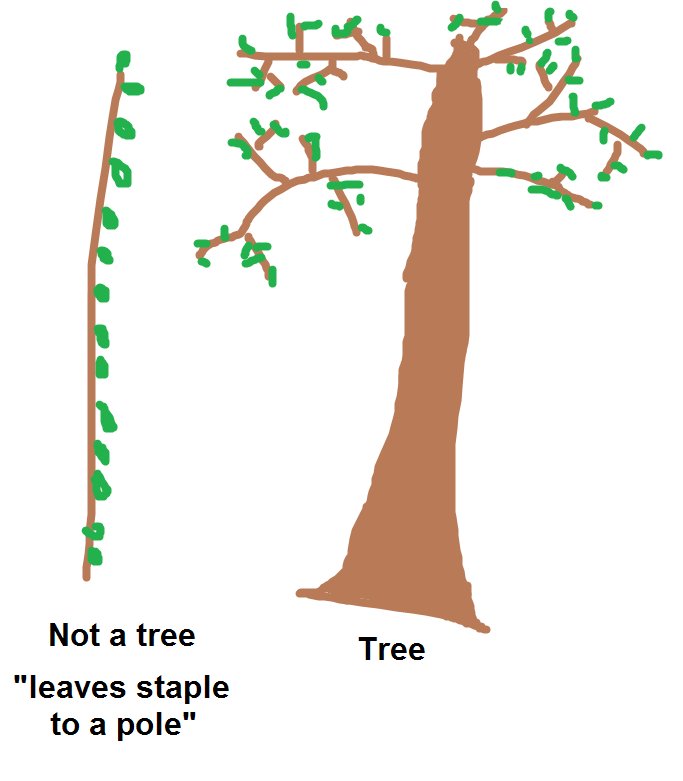
credit: sc00bz
Alright, how does KangarooTwelve work?
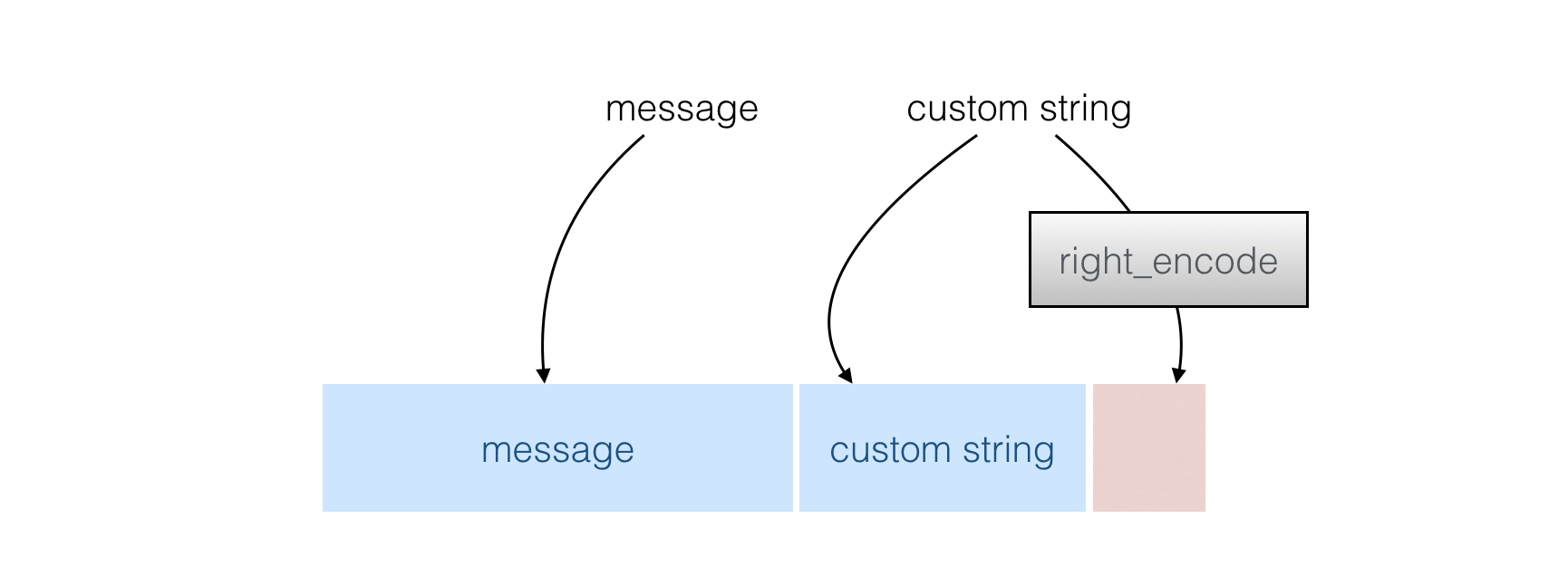
→ First your input is mixed with a "customization string" (which allows you to get different results in different contexts) and the encoding of the length of the customization string (done with right_encode())
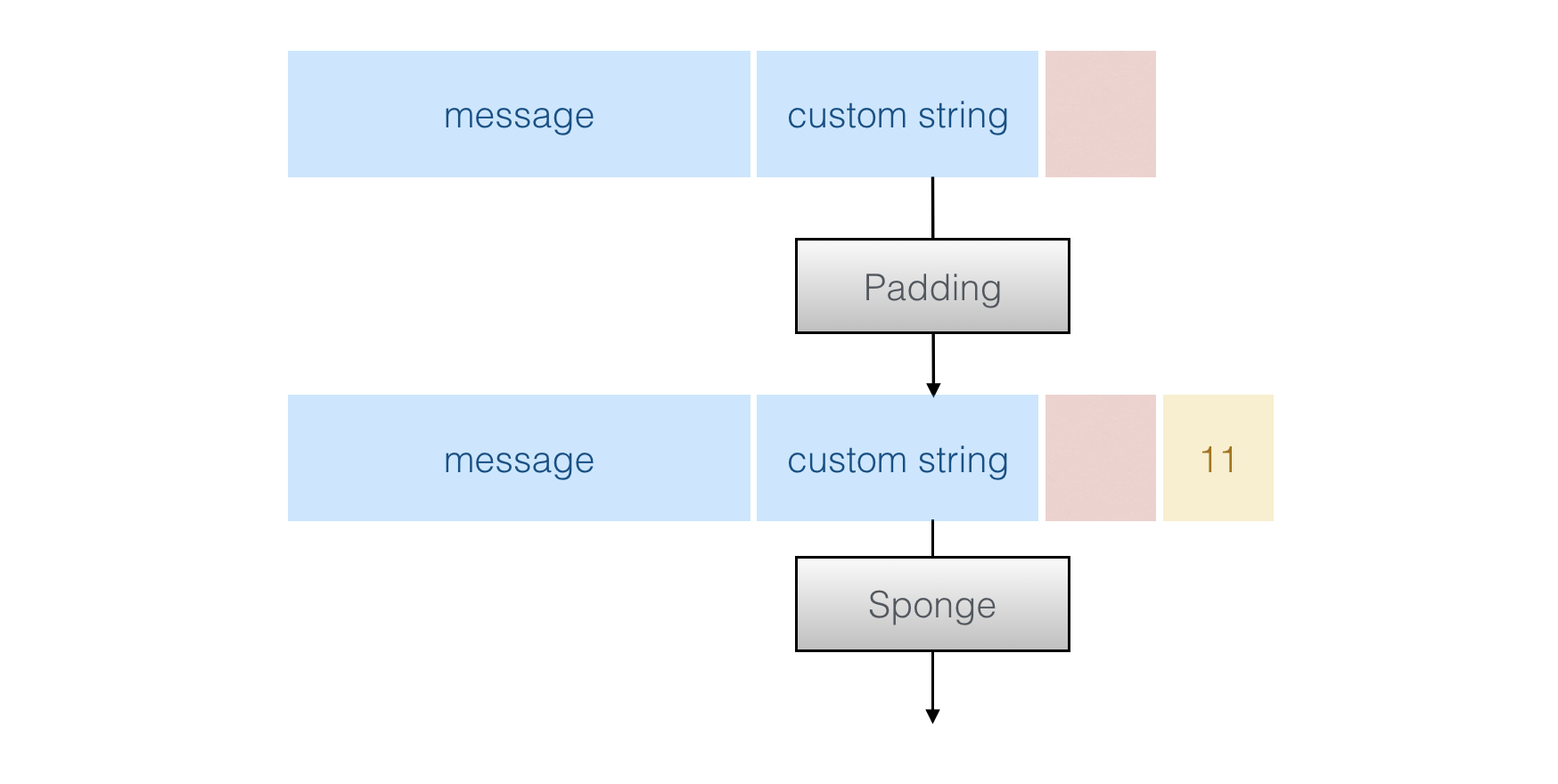
→ Second if the message is "short" (≤8192bytes), the tree hashing is not used. The previous blob is padded and permuted with the sponge. Here the sponge call is Keccak with its default multi-rate padding 101*. The output can be as long as you want like the SHAKE functions.
→ Third if the message is "long", it is divided into "chunks" of 8192 bytes. Each chunk (except the first one) is padded and permuted (so effectively hashed). The end result is structured/concatenated/padded and passed through the Sponge again.
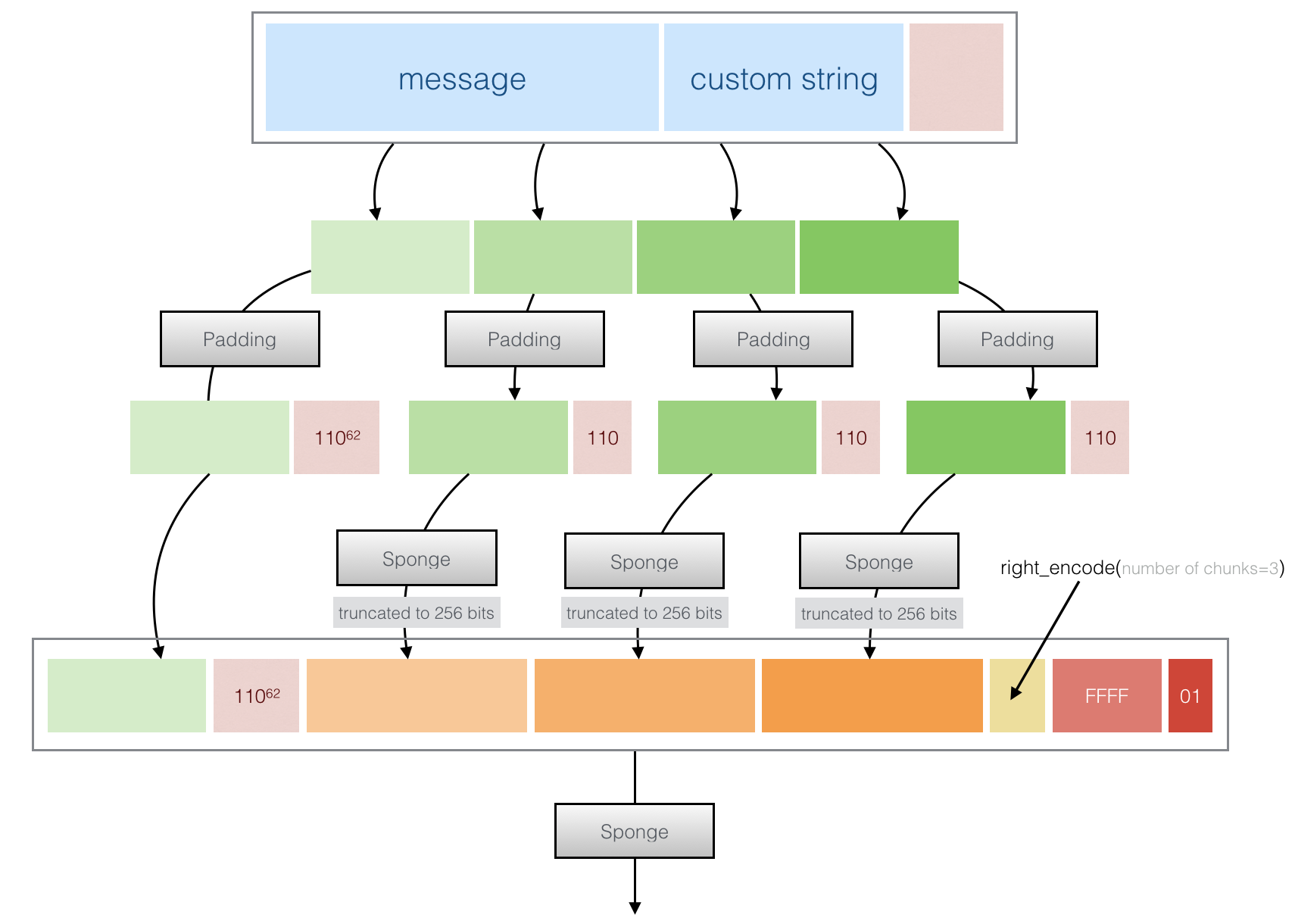
This allows each different chunk to be hashed in parallel on different cores or via some SIMD magic.
Before you go, here is a simple python implementation and the reference C implementation.
Daemen gave some performance estimations for KangarooTwelve during the rump session of Crypto 2016:
- Intel Core i5-4570 (Haswell) 4.15 c/b for short input and 1.44 c/b for long input
- Intel Core i5-6500 (Skylake) 3.72 c/b for short input and 1.22 c/b for long input
- Intel Xeon Phi 7250 (Knights Landing) 4.56 c/b for short input and 0.74 c/b for long input
Thank-you for reading!
Let me re-introduce STROBE: it's a protocol framework based on the Duplex construction. It's kind of the symmetric part of TLS if you will, where everything depends on what happened previously. Kind of like when Noise uses the hash of the entire transcript to derive new keys.
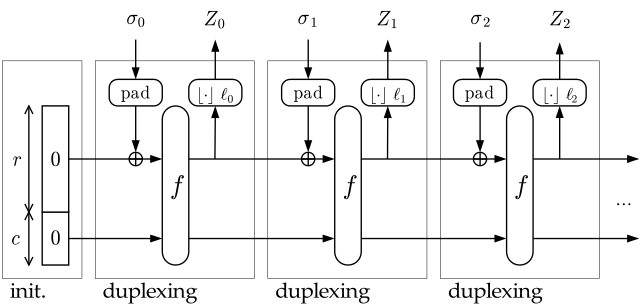
You can do different things with different "operations". Encrypt some plaintext, generate some MAC, generate some random numbers, etc...
These different operations can be combined to form a protocol, or can be used as stand-alone in your logic. This is one of the beautiful aspect of STROBE (heavily based on the beauty of Keccak): it provides you with numerous primitives with only a few APIs, and thus a very small source code: count 1,046 lines of code for the current reference implementation in C.
But like anything based on Keccak, you need a padding and it has to be complicated :)
Duplex Calls
The initialization of a Strobe object is done with cSHAKE by XOR'ing this data: [1,self.R,1,0,1,12*8, "STROBEv1.0.2"] then permuting the state.
After the initialization, for every duplex call (before a permutation happens) a padding is applied. This successfully allows series of duplex call to be seen as one cSHAKE call. The rest of this article explains how duplex calls work. These duplex calls are made of potentially multiple operations combined with a padding function, which in STROBE is a combination of cSHAKE's padding and STROBE's own padding.
if we just started an operation:
[old_begin, flag, data up until the block size (strobe.R)]
flag is one byte computed from:
- The direction of the message when sending or receiving data (I_0).
- The type of operation.
old_begin is the start of the last operation in the current block. It can be seen as the pos_begin of the previous operation. It is computed as:
- If we're starting an operation in a new block:
0. The older operation happened in a previous block.
- If we’re starting an operation in the same block as the previous operation: the starting position of the previous operation in the current block.
if we have already started an operation:
[data up until the block size (strobe.R)]
when a permutation is called (forced or because we reached the blocksize) append:
[pos_begin, cSHAKE's padding = 0x04, 0x00 ... 0x00, 0x80]
pos_begin is the start of our operation in the current block, it is computed as:
- If we're starting the operation on a fresh block:
1. (At index 0 is the value old_begin which can be seend as the padding of the previous operation.)
- If we've already started the operation and already ran F once:
0, indicating that the operation started in a previous block.
- if we're starting the operation, and we're in the same block of another operation: the position of the new operation (which starts at the flag, not the old_begin)
Examples
Example 1: the second operation starts on a new block
block1[old_begin=0, flag, data_1, ..., data_R-2, pos_begin=1, padding= 0x04, 0x80] // the first operation takes more than one block
block2[data_R-1, pos_begin=0, padding=0x04, 0, ..., 0, 0x80] // end of the first operation (and forced permutation)
block3[old_begin=0, flag, data_1, ..., data_R-3, pos_begin=1, padding=0x04, 0, 0x80] // start of the second operation
Example 2: the second operation starts on the same block as the previous operation
block1[old_begin=0, flag, data_1, ..., data_R-2, pos_begin=1, padding= 0x04, 0x80] // the first operation takes more than one block
block2[data_R-1, old_begin=1, flag, data2_1, pos_begin=2 , padding=0x04, 0, ..., 0, 0x80]
Example 3: three operations in the same block
block1[old_begin=0, flag, data_1, ..., data_R-2, pos_begin=1, padding= 0x04, 0x80] // the first operation takes more than one block
block2[data_R-1, old_begin=1, flag, data2_1, pos_begin=2 , old_begin=2, flag, data3_1, pos_begin=5, padding=0x04, 0, ..., 0, 0x80]
I was at Eurocrypt's workshop in Paris last week. One of the reason is because I really like workshops. It was good. Good because of the Tamarin workshop, less good because it ended up just being like a normal conference, but still good because it was incredibly close to Real World Crypto.
Tamarin is a "protocol" verification tool. You give it a protocol, a set of security properties it should respect and Tamarin gives you a formal proof (using constraints solving) that the security guarantees are indeed provided OR it gives you a counter example (an attack).
By default, the adversary is a Dolev-Yao adversary that controls the network and can delete, inject, modify and intercept messages on the network
The thing is realllyyyy easy to install.
In the morning, Cas Cremers gave us an intro to Tamarin and taught us how to read inputs and outputs of the tool. In the afternoon, Ralf Sasse told us about more complex concepts while forcing us to write some input for Tamarin.
It was a lot of fun. Way more fun than I expected. I have to admit that I came skeptical, and never really considered formal verification as "practical". But this day changed my mind.
In an afternoon I was capable of creating a pretty simple input to model an opportunistic ephemeral Diffie-Hellman key agreement. The input I wrote is available here. (I have made a better one here and Santiago Zanella made one here as well).
You can see a lot of rules describing the possible transitions of the state machine, and a final lemma which is saying "for any created session (where neither a key or a session key has been leaked) a man-in-the-middle attacker cannot influence the protocol to retrieve the session key". Of course this is ugly, and reading it again a week afterwards I see things I want to rewrite, and probably some "pros" are going to cringe... But it worked out! and Tamarin ended up finding the trivial man-in-the-middle attack.
If you want to play with it, check the online manual which is just great. It provides a few examples that quickly get you started. The hardest part, you must have guessed, is to translate your protocol into this Tamarin input language.

Ekr kick started the TLS:DIV workshop last Sunday. "The number of changes since draft 13 is too damn high" read one of the slide. Not wrong I said to myself. I did read draft 18 in its entirety when we had to review Cloudflare's TLS 1.3 implementation, and I tried to keep up with the changes ever since but I can honestly say that I completely failed.
So I thought, why not creating a nice diff that would allow me to go through all these changes just by reading the spec one more time. With the magic of git diff --color-words --word-diff=porcelain -U1000000 and some python I created a nice spec that shows up differences between draft 18 and the latest commit on the github spec.

You can find it here
If you want the same thing for a different draft version say something in the comment section!

