Hey! I'm David, cofounder of zkSecurity and the author of the Real-World Cryptography book. I was previously a crypto architect at O(1) Labs (working on the Mina cryptocurrency), before that I was the security lead for Diem (formerly Libra) at Novi (Facebook), and a security consultant for the Cryptography Services of NCC Group. This is my blog about cryptography and security and other related topics that I find interesting.
In the realm of multi-party computation (MPC) protocols, threshold signing is the protocol that address how multiple participants can sign something under a "shared" private key. In other words, instead of one guy signing something with a private key, we want $N$ guys doing the same thing and obtaining the same result without any of them actually knowing the private key (each of them holds a share of the private key, revealing nothing about the private key itself).
The threshold part means that not every participant who has a share has to participate. If there's $N$ participants, then only $t < N$ has to participate for the protocol to succeed. The $t$ and $N$ depend on the protocol you want to design, on the overhead you're willing to eat, the security you want to attain, etc.
Threshold protocols are not just for signing, they're everywhere. The NIST has a Multi-Party Threshold Cryptography competition, in which you can see proposals for threshold signing, but also threshold decryption, threshold key exchanges, and others.
This post is about threshold signatures for ECDSA specifically, as it is the most commonly used signature scheme and so has attracted a number of researchers.
In addition, I'm only going to talk about the history of it, because I haven't written an actual explainer on how these works, and because the history of threshold signing for ECDSA is really messy and confusing and understanding what constructions exist out there is near impossible due to the naming collisions and the number of papers released without proper nicknames (unlike FROST, which is the leading threshold signing algorithm for schnorr signatures).
So here we are, the main line of work for ECDSA threshold signatures goes something like this, and seems to mainly involve two Gs (Gennaro and Goldfeder):
GG19. This has the same name as GG18, but fixes some of the issues in GG18. I think this is because GG18 was published in a journal, so they couldn't update it. But GG18 on eprint is the updated GG19 one. (Yet few people refer to it as GG19.) It fixes a number of bugs, including the ones brought by the Alpha-Rays attack, and A note about the security of GG18.
GG20. This paper is officially called "One Round Threshold ECDSA with Identifiable Abort" and builds on top of GG18/GG19 to introduce the ability to identify who caused the abort. (In other words, who messed up if something was messed up during the multi-party computation.) Note that there are still some bugs in this paper.
CGGMP21. This one combines GG20 with CMP20 (another work on threshold signatures). This is supposed to be the latest work in this line of work and is probably the only version that has no known issues.
I haven't seen much ink being spewed on the ZK update conflict issue so I'll write a short note here.
Let's take a step back. Zero-knowledge proofs allow you to prove the result of the execution of some logic. Like signatures attached to data you receive, ZK proofs can be attached to a computation result. This means that with ZK, internet protocols can be rethought and redesigned. If execution of the protocol logic had to happen somewhere trusted, now some of it can be moved around and delegated to untrusted places, or for privacy-reasons some of it can be moved to places where private data should remain.
How do we design protocols using ZK? It's easy, assume that when a participant of your protocol computes something, they will do it honestly. Then, when you implement the protocol, use ZK proofs to enforce that they behave as intended.
The problem of update conflicts comes when one designs a protocol in which multiple participants decide to update the same value, and do so using local execution. That is, instead of having a central service that executes some update logic sequentially, participants can submit the result of their updates in parallel. In this situation, each participant locally executes the logic on the current state assuming that it will not have changed. But this doesn't work as soon as someone else updates the shared value. In practice, someone's update will invalidate someone else's.
This issue is not just a ZK issue, if you know anything about databases then how to perform conflict resolution has been an issue for a very long time. For example, in distributed databases with more than one writer, conflicts could happen as two nodes attempt to update the same value at the same time. Conflict can also happen in the same way in applications where multiple users want to update the same data, think Google Docs.
The solutions as far as I know can be declined in the following categories:
Resolve conflicts automatically. The simplest example is the Thomas write rule which discards any outdated update. In situations were discarding updates is unacceptable more algorithm can take over. For example, Google Docs uses an algorithm called Operational Transformation to figure out how to merge two independent updates.
Ask the user for help if needed. For example, the git merge command that can sometimes ask for your help to resolve conflicts.
Refuse to accept any conflicts. This often means that the application is written in such a way that conflicts can't arise, and in distributed databases this always mean that there can only be a single node that can write (with all other nodes being read-only). Although applications can also decide to simply deny updates that lead to conflicts, which would lead to poor performance in concurrency-heavy scenarios, as well as poor user experience.
As one can see, the barrier between application and database doesn't matter too much, besides the fact that a database has poor ways of prompting a user: when conflict resolution must be done by a user it is generally the role of the application to reach out.
What about ZK though? From what I've seen, the last "avoid conflicts" solution is always chosen. Perhaps this is because my skewed view has only been within the blockchain world, which can't afford to play conflict resolution with $$$.
For example, simpler ZK protocols like Zcash will often massage their protocol such that proofs are only computed on immutable data. For example, arguments of a function cannot be the latest root of a merkle tree (as it might get updated before we can publish the result of running the function) but it can easily be the root of a merkle tree that was seen previously (we're using a previous state, not the latest state, that's fine).
Another technique is to extract the parts of updates that occur on a shared data structure, and sequence them before running them. For example, the set of nullifiers in zcash is updated outside of a ZK execution by the network, according to some logic that only gets executed sequentially. More complicated ZK platforms like Aleo and Mina do that as well. In Aleo's case, the user can split the logic of its smart contracts by choosing what can be executed locally (provided a proof) and what has to be executed serially by the network (Ethereum-style). In Mina's case, updates that have the potential to lead to conflicts are queued up and later on a single user can decide (if authorized) to process the queued updates serially but in ZK.
Here are some notes on how the Cairo zkVM encodes its (public) memory in the AIR (arithmetization) of the STARK.
If you'd rather watch a 25min video of the article, here it is:
The AIR arithmetization is limited on how it can handle public inputs and outputs, as it only offer boundary constraints.
These boundary constraints can only be used on a few rows, otherwise they're expensive to compute for the verifier.
(A verifier would have to compute $\prod_{i \in S} (x - g^i)$ for some given $x$, so we want to keep $|S|$ small.)
For this reason Cairo introduce another way to get the program and its public inputs/outputs in: public memory. This public memory is strongly related to the memory vector of cairo which a program can read and write to.
Cairo's memory layout is a single vector that is indexed (each rows/entries is assigned to an address starting from 1) and is segmented. For example, the first $l$ rows are reserved for the program itself, some other rows are reserved for the program to write and read cells, etc.
Cairo uses a very natural "constraint-led" approach to memory, by making it write-once instead of read-write. That is, all accesses to the same address should yield the same value. Thus, we will check at some point that for an address $a$ and a value $v$, there'll be some constraint that for any two $(a_1, v_1)$ and $(a_2, v_2)$ such that $a_1 = a_2$, then $v_1 = v_2$.
Accesses are part of the execution trace
At the beginning of our STARK, we saw in How STARKs work if you don't care about FRI that the prover encodes, commits, and sends the columns of the execution trace to the verifier.
The memory, or memory accesses rather (as we will see), are columns of the execution trace as well.
The first two columns introduced in the paper are called $L_1.a$ and $L_1.v$. For each rows in these columns, they represent the access made to the address $a$ in memory, with value $v$. As said previously, we don't care if that access is a write or a read as the difference between them are blurred (any read for a specific address could be the write).
These columns can be used as part of the Cairo CPU, but they don't really prevent the prover from lying about the memory accesses:
First, we haven't proven that all accesses to the same addresses $a_i$ always return the same value $v_i$.
Second, we haven't proven that the memory contains fixed values in specific addresses. For example, it should contain the program itself in the first $l$ cells.
Let's tackle the first question first, and we will address the second one later.
Another list to help
In order to prove that the two columns in the $L_1$ part of the execution trace, Cairo adds two columns to the execution trace: $L_2.a'$ and $L_2.v'$. These two columns contain essentially the same things as the $L_1$ columns, except that these times the accesses are sorted by address.
One might wonder at this point, why can't L1 memory accesses be sorted? Because these accesses represents the actual memory accesses of the program during runtime, and this row by row (or step by step). The program might read the next instruction in some address, then jump and read the next instruction at some other address, etc. We can't force the accesses to be sorted at this point.
We will have to prove (later) that $L_1$ and $L_2$ represent the same accesses (up to some permutation we don't care about).
So let's assume for now that $L_2$ correctly contains the same accesses as $L_1$ but sorted, what can we check on $L_2$?
The first thing we want to check is that it is indeed sorted. Or in other words:
each access is on the same address as previous: $a'_{i+1} = a'_i $
or on the next address: $a'_{i+1} = a'_i + 1$
For this, Cairo adds a continuity constraint to its AIR:
The second thing we want to check is that accesses to the same addresses yield the same values. Now that things are sorted its easy to check this! We just need to check that:
either the values are the same: $v'_{i+1} = v'_i$
or the address being accessed was bumped so it's fine to have different values: $a'_{i+1} = a'_i + 1$
For this, Cairo adds a single-valued constraint to its AIR:
And that's it! We now have proven that the $L_2$ columns represent correct memory accesses through the whole memory (although we didn't check that the first access was at address $1$, not sure if Cairo checks that somewhere), and that the accesses are correct.
That is, as long as $L_2$ contains the same list of accesses as $L_1$.
A multiset check between $L_1$ and $L_2$
To ensure that two list of elements match, up to some permutation (meaning we don't care how they were reordered), we can use the same permutation that Plonk uses (except that plonk fixes the permutation).
The check we want to perform is the following:
$$
{ (a_i, v_i) }_i = { (a'_i, v'_i) }_i
$$
But we can't check tuples like that, so let's get a random value $\alpha$ from the verifier and encode tuples as linear combinations:
Now, let's observe that instead of checking that these two sets match, we can just check that two polynomials have the same roots (where the roots have been encoded to be the elements in our lists):
Finally, we observe that we can use Schwartz-Zippel to reduce this claim to evaluating the LHS at a random verifier point $z$. If the following is true at the random point $z$ then with high probability it is true in general:
The next question to answer is, how do we check this thing in our STARK?
Creating a circuit for the multiset check
Recall that our AIR allows us to write a circuit using successive pairs of rows in the columns of our execution trace.
That is, while we can't access all the $a_i$ and $a'_i$ and $v_i$ and $v'_i$ in one shot, we can access them row by row.
So the idea is to write a circuit that produces the previous section's ratio row by row. To do that, we introduce a new column $p$ in our execution trace which will help us keep track of the ratio as we produce it.
There are two additional (boundary) constraints that the verifier needs to impose to ensure that the multiset check is coherent:
the initial value $p_0$ should be computed correctly ($p_0 = \frac{z - (a_0 + \alpha \cdot v_0)}{z - (a'_0 + \alpha \cdot v'_0)}$)
the final value $p_{-1}$ should contain $1$
Importantly, let me note that this new column $p$ of the execution trace cannot be created, encoded to a polynomial, committed, and sent to the verifier in the same round as other columns of the execution trace. This is because it makes uses of two verifier challenges $z$ and $\alpha$ which have to be revealed after the other columns of the execution trace have been sent to the verifier.
Note: a way to understand this article is that the prover is now building the execution trace interactively with the help of the verifier, and parts of the circuits (here a permutation circuit) will need to use these columns of the execution trace that are built at different stages of the proof.
Inserting the public memory in the memory
Now is time to address the second half of the problem we stated earlier:
Second, we haven't proven that the memory contains fixed values in specific addresses. For example, it should contain the program itself in the first $l$ cells.
To do this, the first $l$ accesses are replaced with accesses to $(0,0)$ in $L_1$. $L_2$ on the other hand uses acceses to the first parts of the memory and retrieves values from the public memory $m^*$ (e.g. $(1, m^*[0]), (2, m^*[1]), \cdots$).
This means two things:
the nominator of $p$ will contain $z - (0 + \alpha \cdot 0) = z$ in the first $l$ iterations (so $z^l$). Furthermore, these will not be cancelled by any values in the denominator (as $L_2$ is supposedly using actual accesses to the public memory)
the denominator of $p$ will contain $\prod_{i \in [[0, l]]} [z - (a'_i + \alpha \cdot m^*[i])]$, and these values won't be canceled by values in the nominator either
As such, the final value of the accumulator should look like this if the prover followed our directions:
Here's some notes on how STARK works, following my read of the ethSTARK Documentation (thanks Bobbin for the pointer!).
Warning: the following explanation should look surprisingly close to PlonK or SNARKs in general, to anyone familiar with these other schemes. If you know PlonK, maybe you can think of STARKs as turboplonk without preprocessing and without copy constraints/permutation. Just turboplonk with a single custom gate that updates the next row, also the commitment scheme makes everything complicated.
The execution trace table
Imagine a table with $W$ columns representing registers, which can be used as temporary values in our program/circuit. The table has $N$ rows, which represent the temporary values of each of these registers in each "step" of the program/circuit.
For example, a table of 4 registers and 3 steps:
r0
r1
r2
1
0
1
534
2
4
1
235
3
3
4
5
The constraints
There are two types of constraints which we want to enforce on this execution trace table to simulate our program:
boundary constraints: if I understand correctly this is for initializing the inputs of your program in the first rows of the table (e.g. the second register must be set to 1 initially) as well as the outputs (e.g. the registers in the last two rows must contain $3$, $4$, and $5$).
state transitions: these are constraints that apply to ALL contiguous pairs of rows (e.g. the first two registers added together in a row equal the value of the third register in the next row). The particularity of STARKs (and what makes them "scallable" and fast in practice) is that the same constraint is applied repeatidly. This is also why people like to use STARKs to implement zkVMs, as VMs do the same thing over and over.
This way of encoding a circuit as constraints is called AIR (for Algebraic Intermediate Representation).
Straw man 1: Doing things in the clear coz YOLO
Let's see an example of how a STARK could work as a naive interactive protocol between a prover and verifier:
the prover constructs the execution trace table and sends it to the verifier
the verifier checks the constraints on the execution trace table by themselves
This protocol works if we don't care about zero-knowledge, but it is obviously not very efficient: the prover sends a huge table to the verifier, and the verifier has to check that the table makes sense (vis a vis of the constraints) by checking every rows involved in the boundary constraints, and checking every contiguous pair of rows involved in the state transition constraints.
Straw man 2: Encoding things as polynomials for future profit
Let's try to improve on the previous protocol by using polynomials. This step will not immediately improve anything, but will set the stage for the step afterwards. Before we talk about the change to the protocol let's see two different observations:
First, let's note that one can encode a list of values as a polynomial by applying a low-degree extension (LDE). That is, if your list of values look like this: $(y_0, y_1, y_2, \cdots)$, then interpolate these values into a polynomial $f$ such that $f(0) = y_0, f(1) = y_1, f(2) = y_2, \cdots$
Usually, as we're acting in a field, a subgroup of large-enough size is chosen in place of $0, 1, 2$ as domain. You can read why's that here. (This domain is called the "trace evaluation domain" by ethSTARK.)
Second, let's see how to represent a constraint like "the first two registers added together in a row equal the value of the third register in the next row" as a polynomial. If the three registers in our examples are encoded as the polynomials $f_1, f_2, f_3$ then we need a way to encode "the next row". If our domain is simply $(0, 1, 2, \cdots)$ then the next row for a polynomial $f_1(x)$ is simply $f_1(x + 1)$. Similarly, if we're using a subgroup generated by $g$ as domain, we can write the next row as $f_1(x \cdot g)$. So the previous example constraint can be written as the constraint polynomial $c_0(x) = f_1(x) + f_2(x) - f_3(x \cdot g)$.
If a constraint polynomial $c_0(x)$ is correctly satisfied by a given execution trace, then it should be zero on the entire domain (for state transition constraints) or on some values of the domain (for boundary constraints). This means we can write it as $c_0(x) = t(x) \cdot \sum_i (x-g^i)$ for some "quotient" polynomial $t$ and the evaluation points $g^i$ (that encode the rows) where the constraint should apply. (In other words, you can factor $c_0$ using its roots $g^i$.)
Note: for STARKs to be efficient, you shouldn't have too many roots. Hence why boundary constraints should be limited to a few rows. But how does it work for state transition constraints that need to be applied to all the rows? The answer is that since we are in a subgroup there's a very efficient way to compute $\sum_i (x - g^i)$. You can read more about that in Efficient computation of the vanishing polynomial of the Mina book.
At this point, you should understand that a prover that wants to convince you that a constraint $c_1$ applies to an execution trace table can do so by showing you that $t$ exists. The prover can do so by sending the verifier the $t$ polynomial and the verifier computes $c_1$ from the register polynomials and verifies that it is indeed equal to $t$ multiplied by the $\sum_i (x-g^i)$. This is what is done both in Plonk and in STARK.
Note: if a constraint doesn't satisfy the execution trace, then you won't be able to factor it with $\sum_i (x - g^i)$ as not all of the $g^i$ will be roots. For this reason you'll get something like $c_1(x) = t(x) \cdot \sum_i (x - g^i) + r(x)$ for $r$ some "rest" polynomial. TODO: at this point can we still get a $t$ but it will have a high degree? If not then why do we have to do a low-degree test later?
Now let's see our modification to the previous protocol:
Instead of sending the execution trace table, the prover encodes each column of the execution trace table (of height $N$) as polynomials, and sends the polynomials to the verifier.
The prover then creates the constraint polynomials $c_0, c_1, \cdots$ (as described above) for each constraint involved in the AIR.
The prover then computes the associated quotient polynomials $t_0, t_1, \cdots$ (as described above) and sends them to the verifier. Note that the ethSTARK paper call these quotient polynomials the constraint polynomials (sorry for the confusion).
The verifier now has to check two things:
low-degree check: that these quotient polynomials are indeed low-degree. This is easy as we're doing everything in the clear for now (TODO: why do we need to check that though?)
correctness check: that these quotient polynomials were correctly constructed. For example, the verifier can check that for $t_0$ by computing $c_0$ themselves using the execution trace polynomials and then checking that it equals $t_0 \cdot (x - 1)$. That is, assuming that the first constraint $c_0$ only apply to the first row $g^0=1$.
Straw man 3: Let's make use of the polynomials with the Schwartz-Zippel optimization!
The verifier doesn't actually have to compute and compare large polynomials in the correctness check. Using the Schwartz-Zippel lemma one can check that two polynomials are equal by evaluating both of them at a random value and checking that the evaluations match. This is because Schwartz-Zippel tells us that two polynomials that are equal will be equal on all their evaluations, but if they differ they will differ on most of their evaluations.
So the previous protocol can be modified to:
The prover sends the columns of the execution trace as polynomials $f_0, f_1, \cdots$ to the verifier.
The prover produces the quotient polynomials $t_0, t_1, \cdots$ and sends them to the verifier.
The verifier produces a random evaluation point $z$.
The verifier checks that each quotient polynomial has been computed correctly. For example, for the first constraint, they evaluate $c_0$ at $z$, then evaluate $t_0(z) \cdot (z - 1)$, then check that both evaluations match.
Straw man 4: Using commitments to hide stuff and reduce proof size!
As the title indicates, we eventually want to use commitments in our scheme so that we can add zero-knowledge (by hiding the polynomials we're sending) and reduce the proof size (our commitments will be much smaller than what they commit).
The commitments used in STARKs are merkle trees, where the leaves contain evaluations of a polynomial. Unlike the commitments used in SNARKs (like IPA and KZG), merkle trees don't have an algebraic structure and thus are quite limited in what they allow us to do. Most of the complexity in STARKs come from the commitments. In this section we will not open that pandora box, and assume that the commitments we're using are normal polynomial commitment schemes which allow us to not only commit to polynomials, but also evaluate them and provide proofs that the evaluations are correct.
Now our protocol looks like this:
The prover commits to the execution trace columns polynomials, then sends the commitments to the verifier.
The prover commits to the quotient polynomials, the sends them to the verifier.
The verifier sends a random value $z$.
The prover evaluates the execution trace column polynomials at $z$ and $z \cdot g$ (remember the verifier might want to evaluate a constraint that looks like this $c_0(x) = f1(x) + f2(x) - f3(x \cdot g)$ as it also uses the next row) and sends the evaluations to the verifier.
The prover evaluates the quotient polynomials at $z$ and sends the evaluations to the verifier (these evaluations are called "masks" in the paper).
For each evaluation, the prover also sends evaluation proofs.
The verifier verifies all evaluation proofs.
The verifier then checks that each constraint is satisfied, by checking the $t = c \cdot \sum_i (x - g^i)$ equation in the clear (using the evaluations provided by the prover).
Straw man 5: a random linear combination to reduce all the checks to a single check
If you've been reading STARK papers you're probably wondering where the heck is the composition polynomial. That final polynomial is simply a way to aggregate a number of checks in order to optimize the protocol.
The idea is that instead of checking a property on a list of polynomial, you can check that property on a random linear combination. For example, instead of checking that $f_1(z) = 3$ and $f_2(z) = 4$, and $f_3(z) = 8$, you can check that for random values $r_1, r_2, r_3$ you have:
Often we avoid generating multiple random values and instead use powers of a single random value, which is a tiny bit less secure but much more practical for a number of reasons I won't touch here. So things often look like this instead, with a random value $r$:
$$f_1(z) + r \cdot f_2(z) + r^2 \cdot f_3(z) = 3 + 4 r + 8 r^2$$
Now our protocol should look like this:
The prover commits to the execution trace columns polynomials, then sends the commitments to the verifier.
The verifier sends a random value $r$.
The prover produces a random linear combination of the constraint polynomials.
The prover produces the quotient polynomial for that random linear combination, which ethSTARK calls the composition polynomial.
The prover commits to the composition polynomial, then sends them to the verifier.
The protocol continues pretty much like the previous one
Note: in the ethSTARK paper they note that the composition polynomial is likely of higher degree than the polynomials encoding the execution trace columns. (The degree of the composition polynomial is equal to the degree of the highest-degree constraint.) For this reason, there's some further optimization that split the composition polynomial into several polynomials, but we will avoid talking about it here.
We now have a protocol that looks somewhat clean, which seems contradictory with the level of complexity introduced by the various papers. Let's fix that in the next blogpost on FRI...
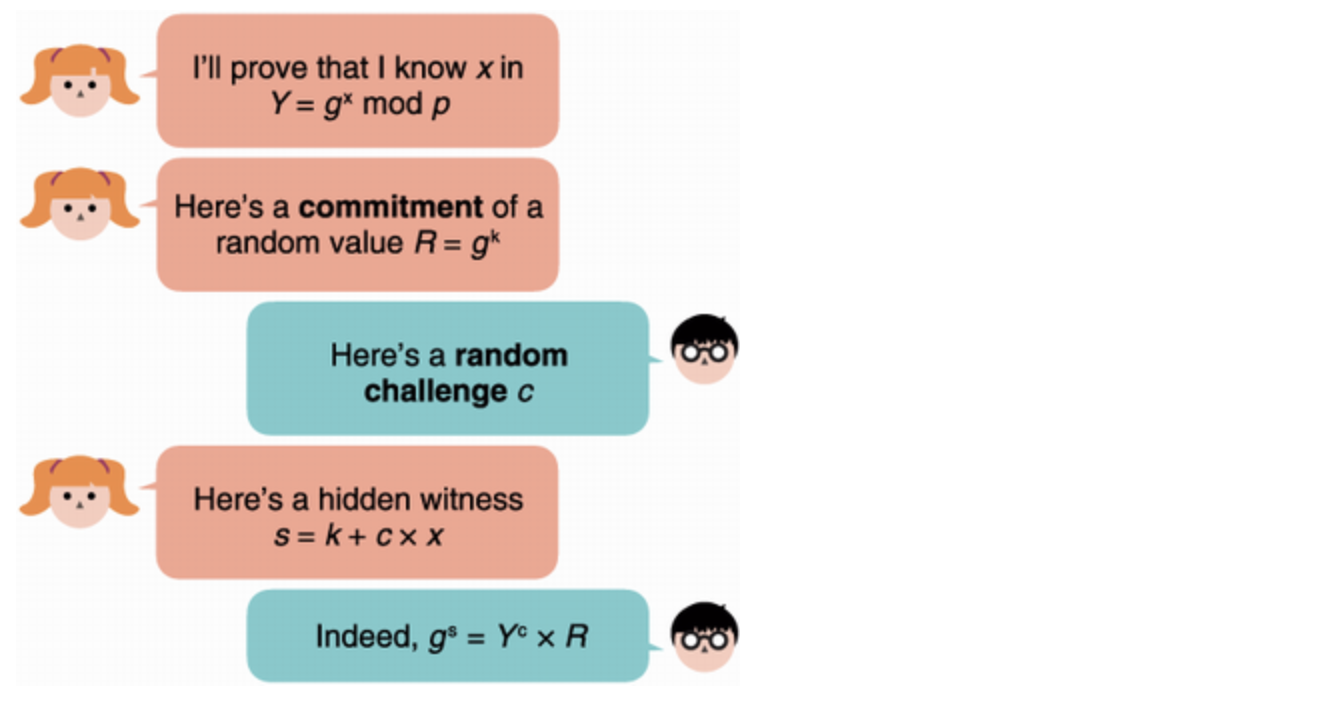
My journey into zero-knowledge proofs (ZKPs) began in university, with me slouching in an amphitheater chair attending a cryptography course. "Zero-knowledge proofs", said the professor, "allow a prover to convince a verifier that they know something without revealing the something". Intriguing, I thought. At the end of the course I had learned that you could prove simple statements, like the knowledge of the discrete logarithm of a field element (e.g. that you know $x$ in $y = g^x \mod p$ for some $g$ and prime $p$) or of an isomorphism between two graphs. Things like that.
The protocols we learned about were often referred to as "sigma protocols" due to the Σ-like shape the interaction between the prover and the verifier looked like. The statements proven were quite limited and simple and I remember thinking "this is interesting but where is this used?"
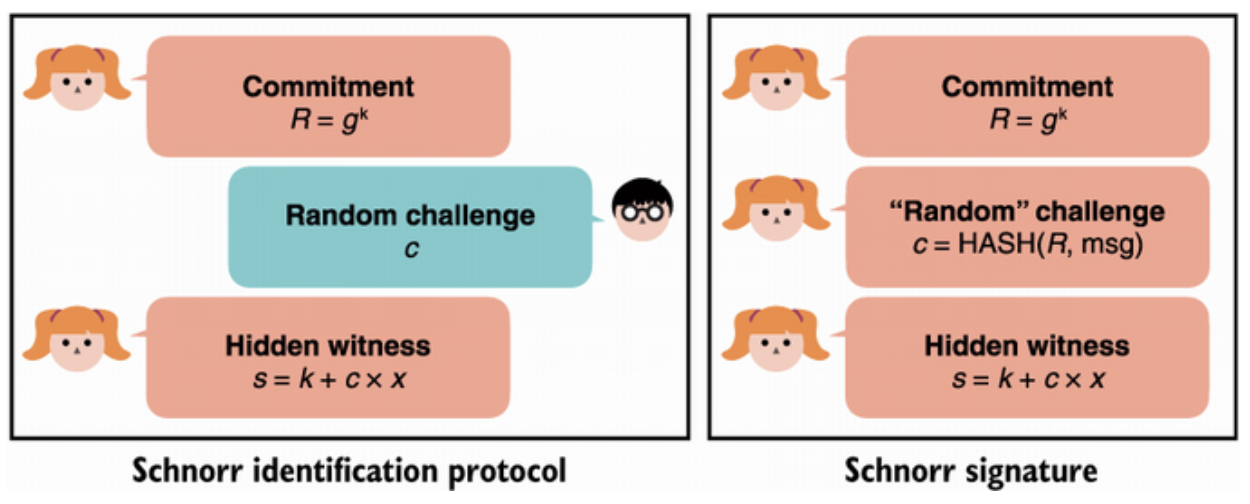
It took me some time to realize that the cryptographic signature schemes used all over the place were actually zero-knowledge proofs. Non-interactive zero-knowledge proofs specifically. As in, no back-and-forth had to happen between a prover and a verifier. The prover could instead create the proof by themselves, publish it, and then anyone could act as a verifier and verify it. I wrote about this first discovery of mine in 2014 here.
Anyone familiar with these ZK proofs would tell you that the non-interactivity is usually achieved using a transformation called "Fiat-Shamir", where the messages of the verifier are replaced by hashing any messages sent previously. If the hash function acts random enough, it seems to work. Although, this technique can only be applied when the verifier messages are not structured, and are just random values. Sigma protocols that have verifiers who only send random values as part of the protocol are referred to as "public-coin".
In 2015 I moved to Chicago and joined NCC Group as the first intern in a new team called Crypto Services. It was a small team of cryptographers led by the fantastic Tom Ritter, and we mostly focused on auditing cryptographic applications. From TLS/SSL to secure messaging, we did it all. These were transformative years for me, as I got a crash course in applied cryptography, and got to work with truly amazing people (like theThomas Pornin!)
At some point cryptocurrencies started booming and we switched to auditing cryptocurrencies almost exclusively. The second time I encountered zero-knowledge proofs was during an audit of ZCash, a fork of Bitcoin that used ZKPs to hide who sent how much to who. This was mind-blowing to me, as the statements proven were not "simple" anymore. What was proven was actual program logic.
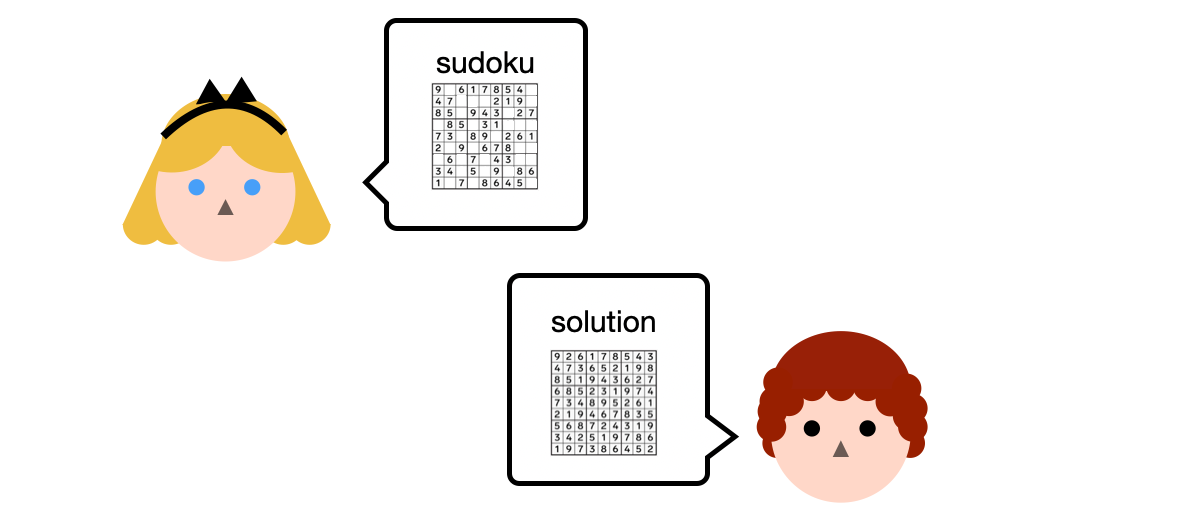
This new kind of "general-purpose" zero-knowledge proofs seemed like a game changer to me. It took me some time to understand the interface behind these ZKPs, but let me try to give you the gist using sudokus. I believe that if you understand this simple example, you can then understand any type of application that makes use of ZKPs by abstracting the zero-knowledge proofs as black boxes.
In this scenario, Alice has a sudoku grid and Bob has a solution. Also, they both have access to some Python program on Github that they can use to verify that the solution solves Alice's grid.
Bob could send the solution to Alice, and she could then run that program, but Bob does not want to share his solution. So Bob runs the program himself and tells Alice "I ran it with your grid and my solution as inputs, and it output true". Is this enough to convince Alice?
Of course not! Why would Alice trust that Bob actually ran the software? For all she knows he could have done nothing, and just lied to her. This is what general-purpose zero-knowledge proofs solve: they allow Bob to create a proof of correct execution given some public inputs (Alice's grid) and some private inputs (Bob's solution).
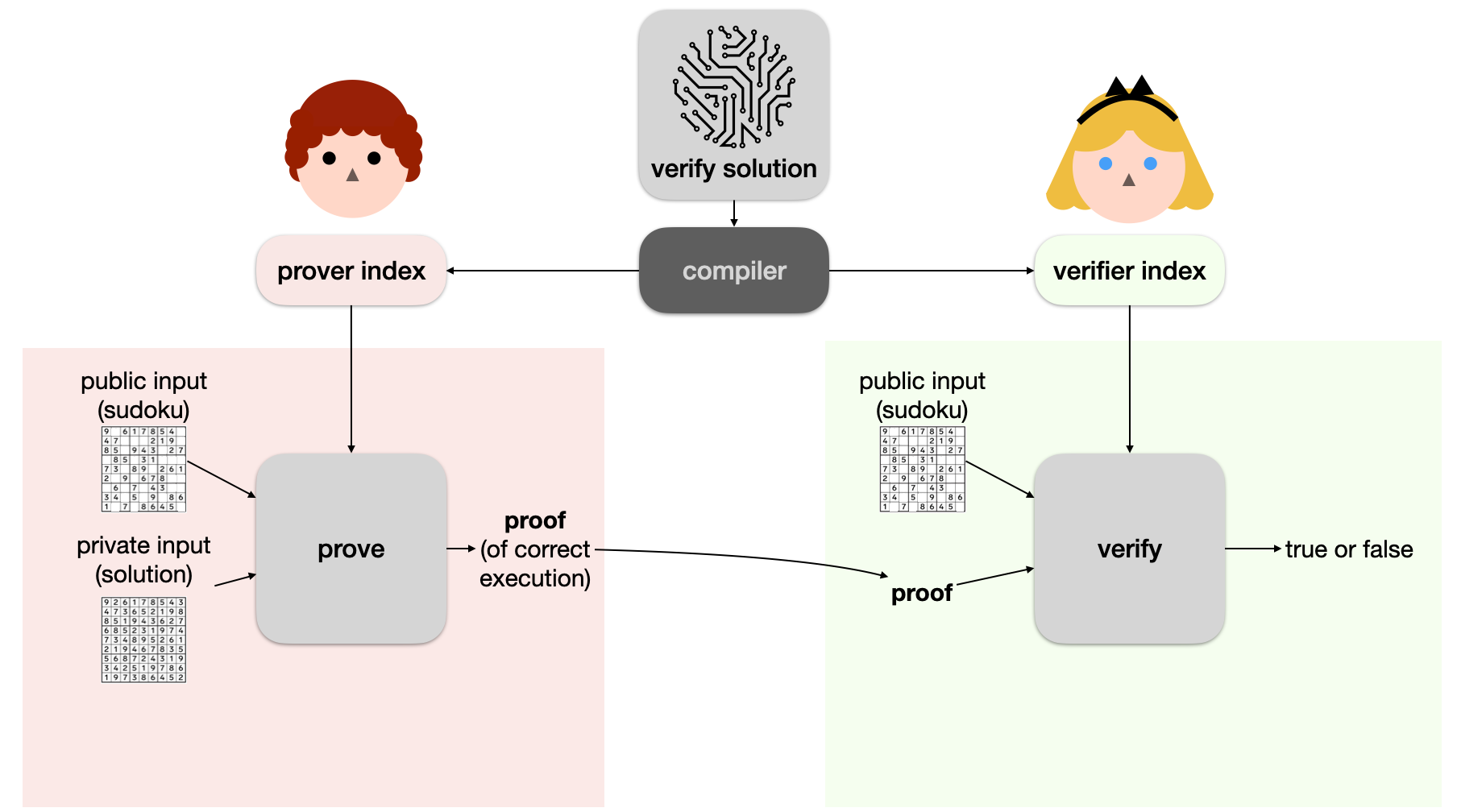
More specifically, both of them can take the "verify solution" program and compile it to two asymmetric parts: a prover index and a verifier index (also called prover key and verifier key, although they're not really keys). Bob can then use a proving algorithm with the correct arguments to produce a proof, and Alice can use another algorithm (a verifier algorithm) to verify that proof. To do that she of course needs to use the verifier index (which is basically a short description of the program) as well as pass the sudoku grid as public input (otherwise who knows what sudoku grid Bob used to create the execution proof).
Python programs are of course not really something that we can prove using math, and so you'll have to believe me when I say that we can translate all sorts of logic using just the multiplication and addition gates. Using just these, we form arithmetic circuits.
I'll give you some examples that come up all the time in circuits people write:
here's how you constraint some value to be a bit: $x ( x - 1 ) = 0$
here's how you unpack a value into bits: $x = x_0 + x_1 \cdot 2 + x_2 \cdot 4 + \cdots$
here's how you do an XOR between two bits (this one is cute): $a + b - 2ab = 0$
here's how you do an if else condition to encode something like r = if cond { a } else { b }: $r = \text{cond} \cdot a + (\text{cond} - 1) b$.
And so, you can imagine that what people end up proving are lists of such equations where the variables are "wired" between different equations (for example, an XOR would use variables that are also constrained to be bits).
To prove that a list of equations is correct given some values, you would then record all of the values used to fill the equations during execution (an execution trace if you will) and apply some math magic on it.
That's all I'll say about that but you can check my series of videos on plonk (a proof system) to learn more about that part.
But let's go back to the project I was looking at at the time. Zcash used a proof system called Groth16. Groth16 was, as the name indicates, created in 2016 by a Mr. Groth. 2016, in the world of zero-knowledge proofs, sounds like centuries ago. Things go really fast and new schemes and breakthroughs are published every year. Yet, one can say that Groth16 is still competitive today as it remains the proving scheme with some of the smallest proofs (hundreds of bytes). In addition it is still used all over the place. Most ZK apps that I've seen being built, or that have been built, on top of Ethereum are using Groth16.
The reason might be that some of the tooling available has dominated the space: Circom and snarkjs. Circom allows you to write circuits in a format Groth16 can understand, and snarkjs allows you to prove and verify these on your laptop, as well as verify proofs on Ethereum (via a verifier implemented in Solidity).
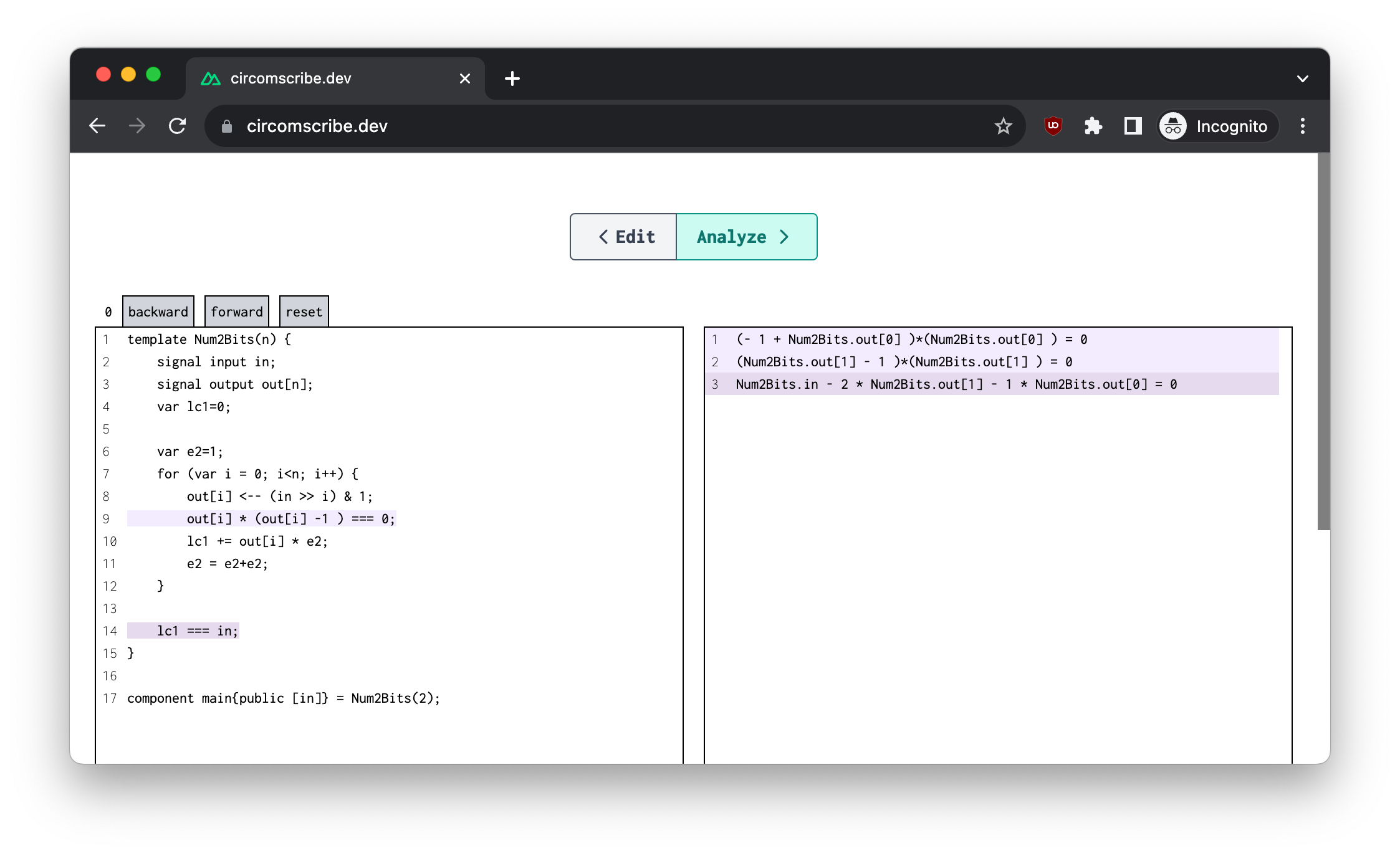
In the following screenshot you can see what Circom code looks like on the left, and how the code is converted down to equations (called constraints) on the right. This is obtained via circomscribe. Take some time to understand what the code does, and how the compiled constraints end up enforcing the same logic.
You might have noticed that none of the equations/constraints have a higher degree than 2. This is a limitation of the arithmetization that Groth16 supports, which is called R1CS. The term arithmetization here is used as to refer to the format that your constraints or equations have to be in for them to be provable by the proof system. This is important as not all proof systems enforce the same "encoding" for your circuit, some allow more complex equations to be packed, while others force you to break down your equations into smaller ones (which increases the list of equations, and thus is more expensive).
Briefly, the way R1CS works is that each equation/constraint has the ability to perform the multiplication of two linear combinations of any of your witness values (the values in the execution trace) and enforce that the result is equal to another linear combination. If that doesn't make sense think of it this way, what you do in R1CS is to encode your circuits as a number of variables $a_i$, $b_i$, and $c_i$ such that if your execution trace is the vector of values $\vec{w} = (w_0, w_1, \cdots)$ then each of your constraints will look like this:
Imagine that we wanted to constrain that $w_1$ is a bit (it's equal to 0 or 1), then we'd try to hardcode a new set of values $a_i, b_i, c_i$ such that we get $w_1 (w_1 - 1) = 0$.
We could set $a_i = b_i = c_i = 0$ except for: $a_1 = 1$ and $b_1 = 1$ which would get us to $(1 \cdot w_1)(1 \cdot w_1) = 0$ which is close but not exactly what we want. How do we get the $-1$ in there?
The solution to encode constants in your circuit is to require that one of the witness values is fixed to a known value. This is done via the proof system (and not by R1CS itself), and usually we set $w_0 = 1$. This way by setting $b_0 = -1$ we get what we want. Right?
Note: additionally, we usually enforce the following witness values $w_1, w_2, \cdots$ to contain the public input values, and then everything after that are private variables that will be used to store the prover's execution trace.
Now, let me say one last thing about Groth16 before moving on. The scheme sort of sucks massively in other ways, because it requires a trusted setup. I've explained what trusted setups are here, but I'll briefly repeat it here: Alice, Bob, or whoever wants to use Groth16 has to generate a set of parameters first. This generation of parameters is unfortunately dangerous, as the person who performs it will be in possession of some values that will let them forge proofs. So-called toxic waste.
We're not crazy, so the way we deal with this is to have someone we trust run the generation of parameters and then destroy the toxic waste they produced during that. This explains the "trusted" part in "trusted setup". Relying on the goodness of a single person is usually not enough to convince people, and so the trusted setup is normally ran by many people in a multi-party computation kind of protocol (called a ceremony). This ensures that as long as one person is honest, the whole thing is secure.
This doesn't always work out. In 2018, Ariel, an employee of Zcash, found a bad bug. Turns out Zcash's ceremony had been run incorrectly and people could have minted money out of thin air. The fix (and a subsequent new ceremony) took a year to land.
What doubly sucks with Groth16 is that you need such a ceremony per-circuit. Every change you want to make to your circuit, or every new circuit you want to prove, will require you to go through that painful ceremony thing again. On top of that, I would say that the tooling to do such ceremonies is in quite an experimental shape.
In 2018, while still working at NCC Group, Ava brought me to the announcement party of the Coda protocol blockchain. There I learned that this project used zero-knowledge proofs in a novel way: they recursed them! Using proofs to prove other proofs, ad-infinitum.
After the meetup I went on their webpage that at the time hosted a demo that looked like that:
Zero-knowledge proofs managed to blew my mind once more. Unfortunately the demo doesn't exist anymore, but if you could experience it today you would have see that: a webpage taking seconds to synchronize to a testnet's latest state (with some cool animations) and then proceeding to verify each new block being added on top of the latest one, live.
At the time this was something I had never seen. Bitcoin or Ethereum were cryptocurrencies that got longer and longer with time. And if you wanted to synchronize your client to their network, you'd have to wait for it to verify the chain block by block, which could take days or even weeks (and perhaps months today). Coda's demo would do that in mere seconds.
ZKPs gave the whole "trust but verify" a whole new meaning.
Each new block would carry a proof, which would prove the correct validation of the entire block and its transactions, and the correct application of the transactions to the previous state resulting in the latest state. On top of that the proof contained a proof that the previous proof was correct. And the previous proof contained a proof that the previous block was correct, along with the previous previous proof. And on and on. You get the idea.
Back then I couldn't believe what I had seen. It seemed too magical, too good to be true. Later I learned how recursive proofs worked and some of the magic dissipated. Intuitively, you can think of it like this: if these zero-knowledge proofs allow you to prove any sort of programs, then why not prove a verifier? The proof verifier is just some software, like any other software, and so its execution can be proved as well!
This novel idea brought some new use cases with it: you could now prove long-running computations. Year-long computations if you wanted. It also brought some novel problems with it that are worth mentioning: recursion is expensive. The reason is that in general, while verifying is cheap (in the order of milliseconds), proving is expensive (in the order of seconds). And so, if recursing meant creating a proof at each step, it meant paying some heavy cost at each step.
In 2019, Sean from Zcash ended up coming up with some techniques called Halo to defer some of that cost to the very end. More recently, a new technique called folding was independently proposed by Srinath (via his scheme Nova) and Benedikt and Binyi (via their scheme Protostar) which allows recursion to completely bypass the expensive computation of a proof at every step. Folding allows us to directly recurse on the execution trace. I call it pre-proof recursion. Of course, folding comes with its different set of challenges and limitations but this is for another article.
In 2018 I decided to move from the service industry to work on a product: Libra (later renamed Diem). I served as the security lead there for two years, in which I ended up writing a book: Real-World Cryptography. This was the culmination of two years of work, and you can read more about why I decided to write yet another cryptography book here. The book contains a chapter on zero-knowledge proofs (and MPC and FHE), as well as a chapter on cryptocurrencies which I believe makes it the first (and perhaps still the only) book with a chapter on cryptocurrencies. Believe it or not.
Not much happened ZK-wise in my life during my time at Facebook. The only thing I can remember was learning about Celo's Plumo protocol and pushing for similar ideas internally. The idea behind Plumo was similar to Coda protocol, but instead of using recursive zero-knowledge proofs to prove the whole blockchain, it relied on the consensus protocol of the Celo blockchain to do most of the work. Left to the zero-knowledge proof was to verify a number of signatures. Sometimes a number of signatures so large that Plumo used a very big proof as well as beefy computers in the cloud to compute it.
it is possible create proofs that span half a year worth of epochs for 100 validators in about 2 hours. We evaluated the performance of our verifier on a Motorola Moto G (2nd Gen), a 2014 mobile phone with 1GB RAM and a Quad-core 1.2 GHz Cortex-A7 processor. We used an unoptimized implementation, directly cross-compiled from [GS19]. The results show it is possible to verify such a proof in about 6 seconds.
I'm not sure why the proof takes so long to verify, but the proving time says a lot about the performance of zero-knowledge proofs in 2020. Since then, a LOT has happened (including folding) and it is probable that the proving time is much more reasonable now.
Unlike AI, which has opened the way to so many applications, it is always hard for me to think of interesting applications for zero-knowledge proofs. My current mental model is the following: the privacy features of ZKPs (provided by the "ZK") seem to mostly be useful when they impact end-users directly. Privacy has been very useful in cryptocurrencies, where everything is public by design, and the word public mixed with money leads to obvious issues. But outside of cryptocurrencies, I have a hard time seeing a large adoption of ZK thanks to its privacy features.
People don't care about privacy. Users want something that's fast and that has a good user experience. If they have to choose between two applications where one is a better experience, but the other provides privacy, they will choose the one with a better experience over the privacy-enhanced one. I've seen this happen again and again (encrypted emails, encrypted messages, cryptographic algorithms, etc.)
People also generally don't care about the "verifiable computation" aspect. Every day we agree to trust many establishments and other human beings. This is how society works, and nothing would work without this kind of network of trust. As such, the high-degree of assurance that ZKPs provide are often unnecessary, and if more trust is needed signatures are often enough.
Between machines though? When no users are involved, the compression and verifiable computation aspects of zero-knowledge proofs are totally a game changer, and I believe that these are going to be the two aspects of ZKPs that are going to impact the non-blockchain world.
I said that signing is often enough, and ZKPs are overkill in a number of scenarios, but verifying signatures in a ZKP is something that actually leads to interesting and useful applications. Both Coda protocol and Plumo did exactly this (verifying consensus and transaction signatures for nodes/light clients). More recently, Sui came out with zkLogin which allows you to prove that a platform (e.g. Google) signed over your username/mail without leaking that information, and Aayush and Sampriti came up with zkEmail which allows you to verify that your email provider signed on the fact that you received some email without leaking the content or your email.
At some point in 2021, the writing was on the wall that Libra was not going to launch. I was still thinking about ZK a lot, and also about the lack of progress I had made in this field. I decided to join the project that had blown my mind a few years prior: Coda Protocol. Their name was now Mina protocol (apparently they had been sued into changing name). I ended up joining and working there for two years on their proof system as a cryptography architect.
The proof system was called Kimchi, which was a variant of PlonK. PlonK had been released in 2019, and had been a game changer in the field, introducing an efficient universal scheme which got rid of Groth16's ugly per-circuit trusted setup. Now a single trusted setup was enough to last for a lifetime of circuits (as long as the circuits didn't reach some upper bound size).
PlonK also brought a different arithmetization, moving us from R1CS to something more flexible (that people often refer to as the "plonkish arithmetization"). No more quadratic constraints, now you could come up with higher degree equations for your constraints as long as they were limited to act on a small part of the execution trace (if that doesn't make sense don't worry). The R1CS tooling was lost though, and PlonK implementations were often incompatible with one another.
Around the same time, Marlin, a universal scheme for R1CS was also released. PlonK won the popular contest though, and a long line of papers started forming around the construction: turboplonk, plookup & ultraplonk, fflonk, shlonk, hyperplonk, honk, etc.
I wouldn't do the space justice without mentioning transparent schemes. Transparent schemes are proof systems that completely bypass the trusted setup: you can generate the parameters to use them without having to do a ceremony! (In other words, Alice, Bob, and anyone can generate them by themselves.)
So-called STARKs (where the T is for transparent) formed a bubble at the same time as the Plonk and Groth16 bubble. These schemes had much faster provers at the cost of larger proofs. If Groth16 had proofs of hundreds of bytes, STARKs looked like hundreds of kilobytes. In addition, due to their use of hash functions they boasted resistance against hypothetical quantum-computers. More seriously they have been criticized for using lower security parameters compared to other schemes.
Another notable line of work of transparent ZKP based on the discrete logarithm problem are inner product arguments (IPAs). Most people know the bulletproof scheme for its use in the Monero cryptocurrency. Unlike other schemes, IPAs have slower verifiers (although still in the order of ms), which can be an issue in practice, but unlike STARKs can still claim to have small proofs.
Interestingly, people have mixed PlonK with the two previously discussed schemes. Plonky mixes PlonK with STARKs, and Zcash's Halo 2 mixes PlonK with IPAs (which is what we used at Mina).
During my time at Mina, most of the company was focused on shipping zero-knowledge smart contracts (or zkapps). The idea was pretty simple: smart contracts in Ethereum (and similar cryptocurrencies) were inefficient in parts due to everyone having to re-execute transactions over and over.
This was the perfect problem to solve for zero-knowledge proofs as one could just execute a smart contract once and then provide an execution proof for others to verify. Avoiding the cost of recomputing the same thing over and over.
One issue when smart contracts are executed locally, on people's laptops, is that they might prove conflicting state transitions. Imagine that someone's transaction takes a smart contract from state A to state B, and someone else's transaction takes the same smart contract from state A to state C, then whoever's transaction gets in first will invalidate the other one. The two transactions are racing.
The problem is that each execution proof has the precondition that the state must be A for it to be valid. In practice this means that the network verifies the proof using the state as public input, and so if the state is no longer "A" then the proof won't verify.
Preconditions can be more relaxed than "this public input MUST be equal to this specific value for the proof to be valid". You can, for example, enforce that the a public input has to be higher than some value, or something like that. But this relaxation also limits the number of applications one can build.
To solve this problem of resource contention, Mina separates the logic of smart contracts into two parts: a private part that doesn't lead to conflicts (and is thus highly parallelizable), and an optional final intent. Final intents are ordered by the network (consensus specifically) and queued up for some time. Other parts of the smart contract can then be used to process that queue. That "post-ordering" execution is lagging behind, and who performs it is a choice of the application.
Aleo, another cryptocurrency similar to Mina, has a similar approach except that their final intent is an actual logic that is executed by the network. The network does that right after processing the transaction (and verifying its ZKP). While both solutions have the network order transactions, Aleo decides to provide a smoother developer experience (at a cost for the network) by taking the burden of executing the final intent in the same fashion Ethereum does.
Note: another worthy contender is Starknet, who decides to bypass this issue by not allowing users to create the proofs at all, and by letting the network sequentially create proofs after some ordering/sequencing of the transactions. The whole purpose of Starknet is to create proofs of execution that Ethereum can verify (making Starknet a "zkrollup", the best kind of "layer 2").
Another issue to solve, if one wants to emulate Ethereum-style smart contracts, is to support contracts calling other contracts. Both projects do this by having each nested call be its own proof, and by having the verifier (the network) glue the calls (but really the proofs) together.
More specifically, one can imagine that at the moment of calling another smart contract's function, a circuit can simply advertise (we also say "witness publicly") what arguments it is using to call the function with, and then advertise the resulting value of the call. It is up to the verifier to verify that the call was correctly encoded by plugging the input and output values as public inputs in the verification of both the caller and callee circuits.
There's something I've sort of shied away from talking about so far: writing circuits. If proof systems can be thought of as backends, then circuit writing is the frontend.
Mina's solution is to provide a library in Typescript (called o1js). That's the "embedded-DSL (Domain Specific Language)" approach. With such a library people can keep using their favorite language, at the cost of writing code that might not produce constraints (and thus produce vulnerabilities). Here's what a Mina zkapp looks like written with o1js:
Several projects have followed this approach. For example, there's arkworks-r1cs for writing R1CS circuits in Rust, and there's gnark for writing circuits in Golang.
Another approach is to invent a new programming language. That's the approach taken by Circom which I've mentioned before. More recently Noir (by Aztec Network) and Leo (by Aleo) were introduced as Rust-like languages. Interestingly Aleo also has a VM that can be compiled into a circuit (so a more low-level-looking language in some way).
Finally, there's the approach of letting developers use their favorite language without having to write code in a specific "circuit way". By that I mean that we can compile the Rust/Golang/C/etc. code they write into a circuit directly. This is the approach of zkLLVM which supports any language that uses the LLVM toolchain/compiler, and translates the LLVM intermediate representation (IR) directly into a circuit.
But wait, I lied, I'm actually not done. There's another completely different proposition: zkVMs. If the previous approach was about "encoding your logic into a circuit", the zkVM approach is about "encoding a Virtual Machine into a circuit".
A VM is essentially just a loop, that at every iteration loads the next instruction and executes it. This is logic in itself that can be converted in a circuit, which would load another program and run it to its course. This is the idea behind the concept of zkVM. It is a very attractive idea because it removes a number of bugs that only happen when you're writing circuits directly (as long as the VM circuit itself doesn't have bugs of course). It also makes loops, branching, etc. much more efficient.
In zkVM-land, there's two branches of philosophy: targeting existing VMs and inventing your own VM.
For example, Risc0 and Jolt both target the RiscV VM. There's also been some ZKWASM projects (like this one). In crypto-land, there are dozens of zkEVMs which all attempt to target the Ethereum VM.
Why would anyone invent new VMs? The idea is that the other VMs I've mentioned are not optimized for being encoded as circuits. And so there's been a line of work to invent optimal zkVMs. For example, there was Cairo (which has an amazing whitepaper) and Miden (which has amazing doc), and more recently Valida (productionized by Lita).
I recently quit my job to launch zkSecurity with two of my ex-coworkers Gregor and Brandon. The idea being that zero-knowledge proofs are going to change the world, and I'll be the first to move into the security for ZK space (hence the great choice of name).
We're also helping organize Zprize, the largest competition in ZK. The idea of ZPrize is to accelerate what is today a technology that's practical for applications that remain relatively simple, but that could be practical for a much larger number of applications if the technology were to gain some efficiency boost.
ZKPs are not FHEs (in that they're practical today), but they still have a number of speed issues to overcome. Mostly, not all operations are practical to encode in circuits. Circuits are encoded over a field (think numbers modulo a large prime number), and don't play nice with anything that requires a lot of bitwise operations (impacting basically all of symmetric cryptography) or bigint arithmetic (impacting basically all of asymmetric cryptography). This means that in general, simple things like doing XORs and checking if values are within a certain range easily blow up the size of our circuits. This leads to provers being slow and using a lot of memory.
There's been three ways to tackle these issues:
screw it, we'll run things on beefy machines in the cloud
let's figure out how to accelerate these operations in order to reduce the circuit size
screw it, let's break up a circuit into multiple smaller circuits
The first solution works somewhat well for machine-to-machine applications that provide mostly compression of computation. For privacy applications targeting end-users? It's often more tricky as users don't want to share their private inputs to some untrusted machine in the cloud. For this, there's been some interesting lines of work that decentralize the prover using multi-party computation protocols, so that delegating a proof doesn't mean losing privacy. The latest work that I know of is zkSAAS from Sanjam.
Still, finding better proof systems and accelerating awkward operations has been one of the most successful ways to solve the efficiency problem. The major breakthrough was to use lookups. For example, integrating an XOR table to your proof system so that you can quickly get the XOR of 4-bit variables, or integrating a table with all the numbers from 0 to $2^{12}$ to allow you to quickly check if a number is within a certain range. Ariel was the first one to introduce a lookup scheme (called plookup) in 2020, which was followed by a stream of improvements, up to the more recent Lasso which basically claims that lookups are so efficient that we can now implement a zkVM using lookups only (isn't that crazy?)
Finally, breaking a circuit into smaller circuits is something I've already almost mentioned (but you might have missed that): using recursion and/or folding one can break a circuit into smaller circuits! Nova Scotia does exactly that by upgrading Circom to use the Nova folding scheme.
There's so much more I could say, but I've now reached 5,000 words and it's getting late. I hope you appreciated the wall of text, and if you have your own ZK journey I encourage you to write about it as well :)
This week, Anna and Guillermo chat with David Wong, author of the Real-World Cryptography book, and a cofounder zksecurity.xyz – an auditing firm focused on Zero Knowledge technology.
They chat about what first got him interested in cryptography, his early work as a security consultant, his work on the Facebook crypto project and the Mina project, zksecurity.xyz, auditing techniques and their efficacy in a ZK context, what common bugs are found in ZK code, and much more.
It should be quite interesting to read as we found double spending and double voting issues. It's also nice because there are two reports in the post, one from us (zksecurity) and one from my previous team over at NCC Group =)